5. 線形二値分類#
import numpy as np
import matplotlib.pyplot as plt
5.1. 二値分類の例:スパム判定#
\(\def\bm{\boldsymbol}\)電子メールは誰にでもすぐにメッセージを送ることができるので便利である一方、自分が受け取りたくないスパムメール(迷惑メール)が送られてくることがある。総務省の統計によると、電気通信事業者10社の全受信メール数に対する迷惑メール数の割合は約50%(2020年3月時点)である。そこで、多くのメールサーバやメールクライアントではスパムメールを自動で認識し、利用者の目に触れさせない機能(スパムフィルタ)が搭載されている。スパムフィルタの主なタスクは、与えられたメールがスパムであるか、スパムではないか自動的に判定することである。この判定を行うモジュール、すなわちスパム判定器を構築するのが、今回のお題である。
では、スパム判定器をどのように構築すればよいか。以下のスパムメールを具体例として考えたい。
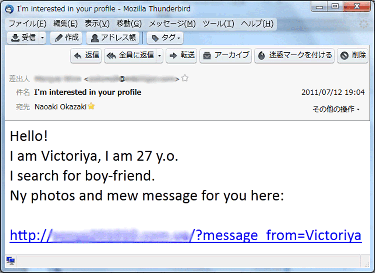
このメールの本文中で"I am Victoriya", "search for boy-friend", "Ny photos"などのフレーズが出てくることに着目し、これらのフレーズが本文中に含まれているメールをスパムと判定するには、次のようなルールを実装するかもしれない。
def is_spam(x):
if x.find('I am Victoriya') != -1:
return True
if x.find('search for boy-friend') != -1:
return True
if x.find('Ny photos') != -1:
return True
#
# ... (大量の判定ルール)
#
return False
is_spam('I am Victoriya, I am 27 y.o.')
True
is_spam('I search for boy-friend.')
True
このようにメールの本文に関して、スパムである条件を記述していくアプローチをルールに基づく手法と呼ぶ。ルールに基づく手法は、訓練データが少ないときは迅速に作ることができる、スパムと判定する条件が明解であるという利点がある。一方で、スパムと判定する条件を詳細化するほどプログラムが複雑になるため、ルールの保守が難しい。また、英語のスパムメールのために作ったルールを、日本語のスパムメールに適用することができないため、特定の言語やジャンルにおけるメールにしか対応できない。
そこで、教師あり学習を用いてスパム判定器を構築することを考える。より具体的には、メールを\(d\)次元の説明変数\(\bm{x} \in \mathbb{R}^d\)で表現し、スパムメールか(\(1\))スパムメールでないか(\(0\))を表す目的変数(出力)\(y \in \{0, 1\}\)を考える。説明変数から目的変数を計算する関数\(f: \mathbb{R}^d \longmapsto \{0, 1\}\)を教師データ\(\mathcal{D}\)から学習することで、スパム判定器を構築できる。説明変数から\(\{0, 1\}\)などの離散値を取る目的変数を求めることを分類(classification)もしくは識別と呼ぶ。分類において目的変数が取りうる値は、クラスやカテゴリなどと呼ばれる。特に、説明変数の取りうる値が2つのクラスに限定された分類を、二値分類(binary classification)と呼ぶ。
以下の図は、機械学習によるスパムフィルターの典型的な動作を示している。スパムメールに関する教師データを使い、事前にスパム判定器を学習しておく。そして、与えられたメールに対して、スパム判定器はメールがスパムであるかどうか推定する。スパムと判定されたメールはスパムフォルダーに自動的に仕分けすることで、新着メールとして表示させないようにする。ただ、スパム判定器が間違った判定をしてしまうことがある。例えば、本当はスパムであるメールをスパムではないと判定してしまうと、新着メールとして表示されてしまう。このとき、メールを閲覧したユーザがそのメールにスパムであることの目印(フラグ)を付けたとする(スパムフォルダーに移動させてもよい)。これは、スパムメールの新しい学習事例を作ったことに相当する。そこで、この新しい学習事例を教師データとしてスパム判定器を再学習すると、スパム判定の性能が向上すると期待される。以降では、スパム判定などの二値分類を実現するモデルと、その学習方法や評価方法を説明する。

なお、スパムの語源はイギリスBBCが1970年頃に制作した『空飛ぶモンティ・パイソン』のスケッチ「スパム」から来ていると言われている(以下は2014年に行われた復活ライブの時に使われた メニュー)。

.jpg){kind=link}
メールのスパム判定以外にも、二値分類には様々な応用例がある。
臨床検査: 血液検査やアンケートの回答などの説明変数から、患者の病気や異常の有無を判定する
与信調査: 属性情報や過去の取引履歴から顧客の信用の有無を判定する
当落予測: 世論調査や出口調査の結果から、候補者の当選・落選を予測する
5.2. 線形二値分類#
線形二値分類 (linear binary classification) は、\(d\)次元の特徴ベクトルで表現された事例\(\bm{x} \in \mathbb{R}^{d}\)が与えられた時、線形モデルのパラメータ\(\bm{w} \in \mathbb{R}^{d}\)との内積を計算し、その正負によってラベル\(\hat{y} \in \{1, 0\}\)を推定する。
線形二値分類のラベル推定式
スパム判定では、スパムメールを\(\hat{y} = 1\)、スパムではないメールを\(\hat{y} = 0\)などと定義する。二値分類において、\(\hat{y} = 1\)の事例を正例(positive example)、\(\hat{y} = 0\)の事例を負例(negative example)と呼ぶことがある。
メールがスパムであるか判定するための手がかりは色々考えられるが、ここでは簡単のため、\(d=9\)次元の特徴空間を例として用いる。この特徴空間の\(1\)次元目は、与えられたメールの本文に"attached"という単語が含まれるならば\(1\)、含まれなければ\(0\)とする。同様に、\(2\)次元目から\(8\)次元目まで、メール本文中に、それぞれ"darling", "file", "hi", "kyoto", "mark", "my", "photo"という単語が含まれるかどうかを表現する。\(9\)次元目はメールの内容に関わらず常に\(1\)とする。例えば、スパム判定を行いたいメールの本文が"Hi darling, my photo in attached file"であった場合、事例\(\bm{x} \in \mathbb{R}^9\)は、
線形二値分類は、事例\(\bm{x}\)とパラメータ\(\bm{w}\)の内積、
を計算し、その符号が正ならば事例をスパム(\(\hat{y} = 1\))と判定し、\(0\)以下ならばスパムでない(\(\hat{y} = 0\))と判定する。つまり、メールに含まれている単語\(j\)に対応する重み\(w_j\)の和でメールのスパムらしさをスコア付けし、そのスコアがしきい値\(0\)を超えたらスパムメールと判定する。
なお、特徴ベクトルの\(d\)次元目の値が常に\(1\)であることに注意して、正例・負例の判別条件を求めると、
となる。すなわち、事例を分類するしきい値を\(0\)に固定するのではなく、重み\(-w_9\)でしきい値を自動的に調整する効果が得られる。このように、すべての事例で\(1\)となる特徴量を入れておくことで、線形二値分類モデルのバイアス項を導入できる。
線形モデルのパラメータ\(\bm{w}\)は、学習データによく合致するように(例えば学習データ上においてスパム判定が正しく行えるように)決定する。モデルのパラメータ\(\bm{w}\)を推定する方法は色々あるが、ここではロジスティック回帰に基づく確率的勾配降下法を紹介する。
5.3. ロジスティック回帰#
ロジスティック回帰(logistic regression)は線形二値分類を実現するモデルの一つで、事例\(\bm{x}\)に対するラベル\(\hat{y} \in \{1, 0\}\)の条件付き確率\(p(y|\bm{x})\)を以下の式で求める。
ロジスティック回帰
ただし、\(\sigma(a)\)はシグモイド関数 (sigmoid function) である。
シグモイド関数
シグモイド関数の形状を以下に示す。
fig, ax = plt.subplots()
x = np.linspace(-10, 10, 1000)
ax.plot(x, 1 / (1 + np.exp(-x)))
ax.set_xlabel('$a$')
ax.set_ylabel('$\sigma(a)$')
ax.grid()
plt.show()
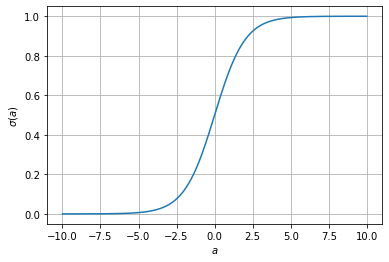
この形状から明らかなように、シグモイド関数は、以下の特徴を持つ。
\((-\infty, +\infty) \to (0, 1)\)の単調増加関数
\(\lim_{a \to -\infty} \sigma(a) = 0\)
\(\lim_{a \to +\infty} \sigma(a) = 1\)
\((0, 0.5)\)に関して点対称
ゆえに、ロジスティック回帰は線形二値分類モデルの内積値\(\bm{x}^\top\bm{w}\)をシグモイド関数\(\sigma\)で確率値に変換していると理解することができる。また、
であるから、
なお、事例\(\bm{x}\)を\(\hat{y}=1\)と予測する確率が\(0.5\)を上回る条件を求めると、線形二値分類の判別式(5.1)と整合することが確認できる。
5.3.1. シグモイド関数の実装#
シグモイド関数\(\sigma(a)\)を素直に実装すると、以下のようなプログラムになるであろう。
def sigmoid(a):
return 1 / (1 + np.exp(-a))
sigmoid(0)
0.5
sigmoid(3), sigmoid(-3)
(0.9525741268224334, 0.04742587317756678)
ところが、\(a=-1000\)とすると\(e^{1000}\)の計算でオーバーフローが発生する。
sigmoid(-1000.)
<ipython-input-2-d5641a12eae7>:2: RuntimeWarning: overflow encountered in exp
return 1 / (1 + np.exp(-a))
0.0
この問題を回避するには、式(5.7)より\(\sigma(-a) = 1 - \sigma(a)\)であることを利用し、np.expの計算結果が大きくならないようにすればよい。
def sigmoid(a):
if 0 <= a:
return 1 / (1 + np.exp(-a))
else:
return 1. - 1 / (1 + np.exp(a))
sigmoid(-1000.)
0.0
5.4. データの表現#
分類問題のデータの表現方法は回帰と同様である。説明変数と目的変数の一つの組を学習事例として表現する。\(1\)番目の学習事例を\((\bm{x}_1, y_1)\)、\(2\)番目の学習事例を\((\bm{x}_2, y_2)\)、\(i\)番目の学習事例を\((\bm{x}_i, y_i)\)と表すことにすると、\(N\)個の事例からなるデータ\(\mathcal{D}\)は次のように表される。
以降では、2個の学習事例(\(N=2\))からなる単純なデータ\(\mathcal{D}_{s}\)を例として用いる。
なお、学習データ\(\mathcal{D}_{s}\)はトイ・データではあるが、スパム判定の例と対応付けて理解できるように、メールを\(\mathcal{D}_{s}\)に変換するまでの過程を簡単に説明しておく。先ほどの\(d=9\)次元の特徴空間を用いたスパムメール判定の例の通り、メールは\(9\)次元の事例ベクトル\(\bm{x}\)で表現され、\(1\)次元目から\(8\)次元目まで、各次元はメール本文中に"attached", "darling", "file", "hi", "kyoto", "mark", "my", "photo"が含まれるならば\(1\)、含まれなければ\(0\)である。\(9\)次元目はメールの内容に関わらず常に\(1\)としておく。いま、スパム判定器の学習データとして、以下の2つのメールがあるとすると、先ほどの学習データ\(\mathcal{D}_s\)が得られる。
学習事例1(スパムではない): "Hi Mark, Kyoto photo in attached file"
学習事例2(スパム): "Hi darling, my photo in attached file"
なお、分類モデルは特徴ベクトル(説明変数)を通してのみ、メールなどの入力を観測できる。したがって、分類が成功しやすくなるような特徴空間を定義することは、分類器の性能を向上させるために極めて重要である。
5.5. 尤度#
さて、何らかの方法でモデルのパラメータ\(\bm{w}\)を以下のように決定したとしよう。
ここで、\(\mathcal{D}_s\)中の事例\(\bm{x}_1\)に対してロジスティック回帰モデルを適用する。
ゆえに、\(P(\hat{y} = 1|\bm{x}_1) = 0.269\)であるから、このモデルは与えられたメールがスパムである確率を\(0.269\)と予測し、その確率が\(0.5\)を超えないことから、\(\bm{x}_1\)はスパムメールではないと判定している。
これまでの流れは、事例\(\bm{x}_1\)とモデルのパラメータ\(\bm{w}\)が与えられた時、予測結果\(P(\hat{y} = 1|\bm{x}_1) = 0.269\)を計算するものであった。ここで、学習事例\((\bm{x}_1, y_1)\)は不変("Hi Mark, Kyoto photo in attached file"というメールがスパムではないのは事実)であると考える。そして、確率に対する見方を変えて、このモデルのパラメータ\(\bm{w}\)が与えられた学習事例を正しく判定できる確率、すなわちモデルパラメータ\(\bm{w}\)の学習事例\((\bm{x}, y)\)に対する尤度\(\hat{l}_{\bm{x}, y}(\bm{w})\)を次式で定義する。
この学習事例に対する尤度は、モデルのパラメータが「どのくらい学習事例を正しく再現できるか」を定量化した指標と見なすことができる。尤度が\(1\)に近いほど学習事例を正しく再現できていること、\(0\)に近づくほど学習事例を間違って(例えば\(y=0\)なのに\(\hat{y}=1\)と予測して)再現していることを意味する。
例えば、学習事例\((\bm{x}_1, y_1)\)は\(y_1 = 0\)であるから、この学習事例に対するモデルパラメータ\(\bm{w}\)の尤度は、
これは、モデルパラメータ\(\bm{w}\)が学習事例\((\bm{x}_1, y_1)\)を\(0.731\)の確率で正しく分類できることを表している。
続いて、\(\mathcal{D}_s\)中の事例\(\bm{x}_2\)に対してロジスティック回帰モデルを適用する。
ゆえに、このモデルは与えられたメールがスパムである確率を\(0.953\)と推定し、その確率が\(0.5\)を超えていることから、\(\bm{x}_2\)はスパムメールである可能性が高いと判定している。また、モデルパラメータ\(\bm{w}\)の学習事例\((\bm{x}_2, y_2)\)に対する尤度\(\hat{l}_{\bm{x}_2, y_2}(\bm{w})\)は、
これは、モデルパラメータ\(\bm{w}\)が学習事例\((\bm{x}_2, y_2)\)を\(0.953\)の確率で正しく分類できることを表している。
なお、学習事例に対する尤度\(\hat{l}_{\bm{x}, y}\)は、\(y=0\)と\(y=1\)で場合分けする代わりに、\(y\)乗を使ってまとめると、次式で表現できる。
事例ごとの尤度
ここで、
とおいた。
5.6. 最尤推定#
先ほどの例では、モデルのパラメータ\(\bm{w}\)を合理的な値に(手で)調整しておいたので、すべての学習事例を正しく分類できた。しかし、パラメータ\(\bm{w}\)の値によっては、正しく分類できない学習事例が出てくる。また、両方の学習事例の尤度は学習事例を完全に再現できる値(\(1\))を下回っている。パラメータ\(\bm{w}\)を調整することで、すべての学習事例の尤度を\(1\)に引き上げ、未知の事例に対する予測性能を向上させることができるかもしれない。先ほどの学習データ\(\mathcal{D}_s\)の例では、\(\bm{w}\)をうまく調整することで、
を実現できるかもしれない。
そこで、学習データ\(\mathcal{D}\)全体における尤度を定義し、モデルのパラメータ\(\bm{w}\)がどのくらい学習データ\(\mathcal{D}\)をうまく反映しているのか、定量的に示したい。ここで、学習データのすべての事例は独立同分布(i.i.d: independent and identically distributed)である仮定し、学習データ全体の尤度\(\hat{L}_{\mathcal{D}}(\bm{w})\)を各学習事例の尤度の結合確率として定義する。
学習データ全体の尤度も\(0\)から\(1\)までの値をとり、尤度が\(1\)に近いほど学習事例を正しく再現できていることを表す。ゆえに、\(\hat{L}_{\mathcal{D}}(\bm{w})\)を目的関数とみなし、この目的関数の値を最大化するような\(\bm{w}^*\)を求めることで、学習データ\(\mathcal{D}\)によく合致するモデルパラメータを求めることができる。尤度が最大になるパラメータを求めることを最尤推定(MLE: Maximum Likelihood Estimation)と呼ぶ。
ところで、学習データ全体の尤度は事例の尤度の積であるから、学習事例の数が多くなると\([0, 1]\)の範囲の積を繰り返すことになる。これは、コンピュータ上で学習データ上の尤度を計算するとき、アンダーフローの問題(小さい値を精度良く表現できない問題)を引き起こす。そこで、尤度を最大化する代わりに、尤度の対数をとった対数尤度を最大化する。対数尤度は、学習事例の尤度の対数\(\log \hat{l}_{(\bm{x}_i, y_i)}(\bm{w})\)の和として表現できる。
なお、回帰では目的関数を最小にするパラメータを求めた。二値分類でも目的関数の最小化の問題に書き換えるため、負の対数尤度を目的関数として用いる。最終的に、ロジスティック回帰モデルの学習で最小化する目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{w})\)は次式で表される。
最尤推定による目的関数
また、学習時に\(L_2\)正則化を導入する場合、目的関数は、
となる。ここで、\(\alpha\) (\(\alpha>0\)) は\(L_2\)正則化の係数である。
5.7. 確率的勾配降下法#
これまでの議論により、ロジスティック回帰モデルの学習は、目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{w})\)を最小にするパラメータ\(\bm{w}^*\)を求める問題に帰着した。回帰の場合は目的関数を最小にする解析解(閉じた解)を求めることができたが、ロジスティック回帰モデルの目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{w})\)は、パラメータ\(\bm{w}\)に関して偏微分はできるが、その偏微分の値を\(\bm{0}\)とする解析解を求めることができない。そこで、確率的勾配降下法で目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{w})\)を最小にするパラメータ\(\bm{w}^*\)を求めることにする。
ここで、最尤推定の目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{w})\)は、
であり、事例毎の実数値の和に分解できるため、確率的勾配降下法を適用可能である。
確率的勾配降下法がランダムに訓練事例\((\bm{x}, y) \in \mathcal{D}\)を選んだとき、その勾配は\(- \nabla \log \hat{l}_{\bm{x}, y}(\bm{w})\)であるから、確率的勾配降下法によるパラメータ\(\bm{w}\)の更新式は、
となる。確率的勾配降下法でロジスティック回帰モデルのパラメータ推定を行うためには、訓練事例の勾配\(\nabla \log \hat{l}_{\bm{x}, y}(\bm{w})\)、すなわち訓練事例の対数尤度\(\log \hat{l}_{\bm{x}, y}(\bm{w})\)の\(\bm{w}\)に関する偏微分を求めればよい。
学習事例の対数尤度は、式(5.18)より、
と整理できる。ただし、式(5.6)と(5.19)で表現されているように、\(p\)は\(\bm{w}\)と\(\bm{x}\)に依存していることに注意が必要である。
合成関数の微分より、
\(\frac{\partial p}{\partial a}\)はシグモイド関数\(\sigma(a)\)の微分である。
また、\(\frac{\partial a}{\partial \bm{w}}=\bm{x}\)であるから、式(5.29)は、
これを、確率的勾配降下法の反復式(5.26)に代入すると、
確率的勾配降下法によるロジスティック回帰モデルのパラメータ更新式
ただし、\(p^{(t)}\)は\(t\)回目の反復時のパラメータ\(\bm{w}^{(t)}\)で事例\(\bm{x}\)を分類したとき、その事例が正例\(\hat{y}=1\)と予測される確率である。
確率的勾配降下法で回帰モデルのパラメータを求めるための反復式(4.33)と同様に、ある訓練事例における目的変数の真の値\(y\)とその確率推定値\(p\)の差を係数として、その事例の特徴ベクトル\(\bm{x}\)をパラメータベクトルに足し込む形になっているのが興味深い。
5.7.1. 確率的勾配降下法の更新式の解釈#
式(5.32)の反復式の振る舞いを、学習事例が正例(\(y=1\))のときと、負例(\(y = 0\))に分けて考える。もし、学習事例が正例(\(y=1\))のとき、パラメータの更新式は、
である。この更新後のパラメータ\(\bm{w}^{(t+1)}\)で同じ事例\(\bm{x}\)との内積を計算すると、
であるから、更新後のパラメータの内積\(\bm{x}^\top\bm{w}^{(t+1)}\)は、更新前のパラメータの内積値\(\bm{x}^\top\bm{w}^{(t)}\)以上にとなり、その変化量は\(\eta_t (1 - p^{(t)}) \bm{x}^\top\bm{x}\)である。ここで、学習率\(\eta_t\)は学習事例に依存しない。また、\(\bm{x}^\top\bm{x}\)もパラメータ\(\bm{w}^{(t)}\)の値によらない定数と見なすと、内積の変化量は\((1-p^{(t)})\)に比例することが分かる。いま、学習事例は正例(\(y=1\))であるので、\((1-p^{(t)})\)はこの事例に対して予測すべき確率\(1\)と、実際に計算された確率\(p^{(t)}\)との差を表している。したがって、モデルのパラメータ\(\bm{w}^{(t)}\)が学習事例が正例であることをよく予測できている(\(p^{(t)} \approx 1\))ならば内積の変化量は小さくなる。逆に、モデルのパラメータ\(\bm{w}^{(t)}\)が学習事例が正例であることを予測できていない場合(\(p^{(t)} \approx 0\))ならば、内積の変化量が大きくなるようにパラメータ\(\bm{w}^{(t)}\)が更新される。
続いて、学習事例が負例(\(y=0\))のとき、パラメータの更新式は、
である。この更新後のパラメータ\(\bm{w}^{(t+1)}\)で同じ事例\(\bm{x}\)との内積を計算すると、
であるから、更新後のパラメータの内積\(\bm{x}^\top\bm{w}^{(t+1)}\)は、更新前のパラメータの内積値\(\bm{x}^\top\bm{w}^{(t)}\)以下にとなり、その変化量は\(\eta_t p^{(t)} \bm{x}^\top\bm{x}\)である。先ほどの正例の議論と同様に、内積の変化量は\(p^{(t)}\)に比例することが分かる。いま、学習事例は負例(\(y=0\))であるので、\(p^{(t)}\)はこの事例に対して予測すべき確率\(0\)と、実際に計算された確率\(p^{(t)}\)との差を表している。したがって、学習事例が負例であることをモデルのパラメータ\(\bm{w}^{(t)}\)がよく予測できている(\(p^{(t)} \approx 0\))ならば内積の変化量は小さくなる。逆に、学習事例が負例であることをモデルのパラメータ\(\bm{w}^{(t)}\)があまり予測できていない場合(\(p^{(t)} \approx 1\))、内積の変化量が大きくなるようにパラメータ\(\bm{w}^{(t)}\)が更新される。
5.7.2. \(L_2\)正則化付きロジスティック回帰#
学習時に\(L_2\)正則化を導入する場合、目的関数は、
と整理できるので、確率的勾配降下法を適用できる。確率的勾配降下法がランダムに選んだ学習事例を\((\bm{x}, y)\)とすると、その損失\(l_{\bm{x}, y}(\bm{w})\)は、
である。この勾配\(\nabla l_{\bm{x}, y}(\bm{w})\)を求めるために、\(\bm{w}\)で偏微分すると、
これを、確率的勾配降下法の反復式に代入すると、
リッジ回帰と同様に、パラメータの重みを減衰させる係数\((1 - \frac{2\alpha\eta_t}{N})\)が現れる。
5.8. 評価#
さて、学習によって獲得した二値分類モデルの性能(分類の正しさ)をどのように評価すればよいか。回帰のときは、学習で用いた目的関数、すなわち平均二乗残差を使って検証データやテストデータ上の性能を測定した。ロジスティック回帰モデルを最尤推定で学習する場合、尤度(もしくは対数尤度)を最大化していたので、検証データやテストデータ上で尤度を測定すればよい(実際に尤度が評価に用いられることもある)。ところが、尤度は人間にとって分かりやすい指標ではないため、二値分類ではもう少し分かりやすい評価尺度が用いられる。ここでは、二値分類モデルの評価尺度として、正解率、適合率、再現率、F1スコアを紹介する。
これらの尺度を説明する前に、真陽性(TP: true positive)、偽陽性(FP: false positive)、偽陰性(FN: false negative)、真陰性(TN: true negative)の概念を理解する必要がある。モデルが正例と予測(\(\hat{y}=1\))した事例のうち、実際に正例(\(y=1\))である事例を真陽性、実際には負例(\(y=0\))である事例を疑陽性と呼ぶ。一方、モデルが負例と予測(\(\hat{y}=0\))した事例のうち、実際に負例(\(y=0\))である事例を真陰性、実際には正例(\(y=1\))である事例を偽陰性と呼ぶ。これらの概念を表に表すと、以下のようになる。

ここで、真陽性、偽陽性、偽陰性、真陰性の事例数をそれぞれ、\({\rm TP}\), \({\rm FP}\), \({\rm FN}\), \({\rm TN}\)と書くことにすると、正解率\(A\)、適合率\(P\)、再現率\(R\)、F1スコア\(F_1\)は、
重要
この中で最も分かりやすい尺度は正解率(accuracy)であろう。正解率は、すべての評価事例の中でモデルが予測に成功した割合である。スパム判定の例では、届いたメールに対して、スパム判定の結果が正しかった割合を表す。ただし、評価データ中の正例と負例の割合が大きく偏っている場合、正解率は高くなりやすい。例えば、100件中1件しかスパムメールがやってこない状況では、すべてのメールを「スパムでない」と判定しても正解率が0.99となる。
適合率と再現率はセットで理解する必要がある。適合率(precision)は、モデルが正例と予測した事例のうち、実際に正例である事例の割合である。スパム判定の例では、スパムと判定されたメールのうち、実際にスパムであるメールの割合である。スパム判定において適合率が低いと、本当はスパムではないメールがスパムフォルダに自動仕分けされてしまうことになる。一方、再現率(recall)は、実際に正例である事例のうち、モデルが正例として予測できる事例の割合である。スパム判定の例では、スパムメールの何割を自動的に認識できるかを表す。スパム判定において再現率が低いと、スパムメールがスパムフォルダに自動仕分けされず、新着メールとして頻繁に表示されてしまうことになる。
一般に、適合率と再現率はトレードオフの関係にある。スパムメールの判定の適合率を高めるには、自信を持ってスパムメールと判定できるものだけスパムと判定し、あまり自信がない事例についてはスパムではないと判定すればよい。ところが、このようにして適合率を高めると、スパムメールと判定することに消極的となり、再現率が低下する。一方、再現率を高めるには、スパムメールと認定する基準を下げ、より多くのメールをスパムとして判定できるように調整すればよい。ところが、メールをスパムとして積極的に判定しすぎると、適合率が低下する。従って、モデルの性能を評価するときは、適合率と再現率の両方を測定することが望ましい。スパムメール判定では、スパムフォルダに自動的に仕分けされてしまったメールは読まれないことになってしまうため、再現率よりも適合率を重視すべきである。
このように、適合率と再現率はトレードオフの関係にあるため、分類器の性能を測定するときにはこの両方の尺度の数値を見る必要がある。この適合率と再現率の調和平均をとったものがF1スコアである。F1スコアは異なるモデル間の性能を一つの評価尺度で比較できるので便利である。
なお、病気などの検査では感度(sensitivity)と特異度(specificity)もよく用いられる。感度は再現率と同じ定義であり、実際に陽性となるべき事例をどの程度陽性として検出できたかを表す。特異度は負例に関する再現率であり、実際に陰性となるべき事例をどの程度陰性として検出できたかを表す。特異度(\(S\))の定義は次式の通りである。
5.9. スパムフィルタの構築#
5.9.1. データのダウンロード#
SMS Spam Collection Data Setを用いて、英語のスパムフィルタを学習する。
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip
--2021-08-01 06:20:41-- https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip
Resolving archive.ics.uci.edu (archive.ics.uci.edu)... 128.195.10.252
Connecting to archive.ics.uci.edu (archive.ics.uci.edu)|128.195.10.252|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 203415 (199K) [application/x-httpd-php]
Saving to: ‘smsspamcollection.zip’
smsspamcollection.z 100%[===================>] 198.65K 249KB/s in 0.8s
2021-08-01 06:20:43 (249 KB/s) - ‘smsspamcollection.zip’ saved [203415/203415]
ダウンロードしたファイルを解凍する。
!unzip smsspamcollection.zip
Archive: smsspamcollection.zip
inflating: SMSSpamCollection
inflating: readme
データのファイル(SMSSpamCollection)は、1行1事例で書かれており、各事例はラベルとテキストのタブ区切り形式である。スパムではないメッセージは"ham"、スパムメッセージは"spam"としてラベル付けされている。
!head SMSSpamCollection
ham Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
ham Ok lar... Joking wif u oni...
spam Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's
ham U dun say so early hor... U c already then say...
ham Nah I don't think he goes to usf, he lives around here though
spam FreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, £1.50 to rcv
ham Even my brother is not like to speak with me. They treat me like aids patent.
ham As per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune
spam WINNER!! As a valued network customer you have been selected to receivea £900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.
spam Had your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030
Windows版PythonなどでLinuxコマンドを利用できない場合
上の3つのコードセルでは、!を先頭に付けることでLinuxコマンドを呼び出している。ところが、Windows版のPython上で動作しているJupyterでは、Linuxコマンドを実行できない。その代替として、以下のPythonプログラムを実行すればよい。
wgetコマンドの代わりにSMS Spam Collection Data Setをダウンロードするコード。
import urllib.request
filename, _ = urllib.request.urlretrieve(
'https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip',
'smsspamcollection.zip'
)
zipコマンドの代わりにダウンロードしたファイルを解凍する。
import zipfile
with zipfile.ZipFile(filename, 'r') as fi:
fi.extractall('.')
解凍したファイルの先頭から10行を表示する。
with open('SMSSpamCollection', encoding="utf-8") as fi:
for n, line in enumerate(fi):
if n < 10:
print(line, end='')
else:
break
なお、Windows 10以降ではWindows Subsystem for Linux (WSL)をインストールすることで、UbuntuなどのLinux ディストリビューションを動作させ、その環境内でJupyterを立ち上げることができる。その場合、LinuxコマンドをJupyterのコードセルから直接呼び出すことが可能である。
5.9.2. データの読み込み#
このファイルから事例を読み込み、リストオブジェクトDに格納する。
Windows版Pythonで文字化けが発生する場合
Windows版のPythonでは、テキストファイルの読み書きの際の文字コードの規定値がCP932 (Shift_JIS) に設定されていることがある。ところが、SMSSpamCollectionというファイルの文字コードはUTF-8であるため、ファイルの内容を正常に読み込むことができない。その場合は、以下のプログラムで
with open('SMSSpamCollection') as fi:
となっている箇所を、
with open('SMSSpamCollection', encoding='utf8') as fi:
に変更すればよい。
もしくは、PYTHONUTF8という環境変数に1をセットした状態でJupyterを立ち上げると、テキストファイルの読み書き時の文字コードの規定値がUTF-8となるので、プログラムを変更しなくてもSMSSpamCollectionをUTF-8のテキストファイルとして読み込むことができる(PEP 540 -- Add a new UTF-8 Mode)。
set PYTHONUTF8=1
import collections
def tokenize(s):
return [t.rstrip('.') for t in s.split(' ')]
def vectorize(tokens):
return collections.Counter(tokens)
def readiter(fi):
for line in fi:
fields = line.strip('\n').split('\t')
x = vectorize(tokenize(fields[1]))
y = fields[0]
yield x, y
with open('SMSSpamCollection') as fi:
D = [d for d in readiter(fi)]
Dの各要素はメッセージ中に含まれる単語の出現頻度(collections.Counterオブジェクト)とラベルのタプルである。
D[6]
(Counter({'Even': 1,
'my': 1,
'brother': 1,
'is': 1,
'not': 1,
'like': 2,
'to': 1,
'speak': 1,
'with': 1,
'me': 2,
'They': 1,
'treat': 1,
'aids': 1,
'patent': 1}),
'ham')
sklearn.model_selection.train_test_splitを用いて、このデータセットを訓練データ(90%)と評価データ(10%)に分割する。
from sklearn.model_selection import train_test_split
Dtrain, Dtest = train_test_split(D, test_size=0.1, random_state=0)
訓練データと評価データの事例数を確認しておく。
len(Dtrain), len(Dtest)
(5016, 558)
5.9.3. データ形式の変換#
sklearn.feature_extraction.DictVectorizerとsklearn.preprocessing.LabelEncoderを用いて、訓練データと評価データをscikit-learnが扱える行列形式に変換する。
DictVectorizerは、特徴をキー、値をバリューとする辞書オブジェクトから特徴ベクトルに変換する。このとき、各特徴に\(0\)から始まるID番号を割り振っていくことで、文字列などで表現される特徴をベクトルの要素番号に対応づける。なお、テキストを単語を特徴とするベクトルで表現する場合、ベクトルの要素数はデータ中のすべての単語となるが、各事例のテキストは少数の単語で構成されるため、特徴ベクトルの多くの要素はゼロで、テキストに含まれている単語に対応する要素だけ非ゼロとなる。このように、要素の多くはゼロで、少数の要素が非ゼロであるベクトルは疎ベクトルと呼ばれる。DictVectorizerのデフォルトの動作では、辞書オブジェクトをscipy.sparseの疎ベクトル形式に変換する。
fit_transform関数は、 特徴と要素番号の対応関係を更新しながら、辞書オブジェクトを疎ベクトルに変換する。transform関数は、特徴と要素番号の対応関係を更新せずに、辞書オブジェクトを疎ベクトルに変換する(対応関係が登録されていない特徴は無視される)。 学習時に存在しなかった特徴を評価時に使うことができないため、前者を学習データに、後者を評価データに用いる。いずれの関数も、引数として辞書オブジェクトのリスト(事例のリスト)を与えると、返り値は事例の疎ベクトルをまとめた疎行列となる。
LabelEncoderはラベルを整数値に変換する。各ラベルに\(0\)から始まるID番号を割り振っていくことで、文字列などで表現されるラベルをクラスの番号に対応づける。今回用いるデータは"ham"と"spam"の二つのラベルで構成されているため、これらのラベルに対して\(0\)または\(1\)が割り当てられる。
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_extraction import DictVectorizer
VX = DictVectorizer()
VY = LabelEncoder()
Xtrain = VX.fit_transform([d[0] for d in Dtrain])
Ytrain = VY.fit_transform([d[1] for d in Dtrain])
Xtest = VX.transform([d[0] for d in Dtest])
Ytest = VY.transform([d[1] for d in Dtest])
訓練データの事例Dtrain[10]がどのように変換されたのか確認しておこう。
Dtrain[10]
(Counter({'I': 1,
'take': 1,
'it': 2,
'we': 3,
"didn't": 1,
'have': 2,
'the': 1,
'phone': 1,
'callon': 1,
'Friday': 1,
'Can': 1,
'assume': 1,
"won't": 1,
'this': 1,
'year': 1,
'now?': 1}),
'ham')
この事例の特徴ベクトルは疎ベクトルとして表現されている。
print(Xtrain[10])
(0, 1831) 1.0
(0, 2385) 1.0
(0, 2769) 1.0
(0, 5546) 1.0
(0, 6110) 1.0
(0, 6923) 1.0
(0, 8101) 2.0
(0, 8587) 2.0
(0, 9821) 1.0
(0, 10231) 1.0
(0, 11832) 1.0
(0, 11957) 1.0
(0, 12014) 1.0
(0, 12653) 3.0
(0, 12862) 1.0
(0, 13030) 1.0
値が3.0となっているベクトルの列番号は12653である。Dtrain[10]の実行結果から、この特徴に対応する単語は"we"である。そこで、12653に対応づけられている特徴を調べると、"we"であることが確認できる。
VX.feature_names_[12653]
'we'
この事例に対応づけられたラベルのID番号は\(0\)である。
print(Ytrain[10])
0
LabelEncoderオブジェクトに格納されているラベルからID番号への対応付けを確認すると、"ham"が\(0\)番、"spam"が\(1\)番に割り当てられていることが分かる。つまり、\(y=0\)が"ham"、\(y=1\)が"spam"に対応付けられている。
VY.classes_
array(['ham', 'spam'], dtype='<U4')
5.9.4. 二値分類モデルの学習#
sklearn.linear_model.SGDClassifierは線形分類モデルを確率的勾配降下法で学習する。ロジスティック回帰モデルを学習するには、SGDClassifierの引数にloss='log'を指定する。fit関数に訓練データを渡すことで、モデルのパラメータが学習される。
from sklearn.linear_model import SGDClassifier
model = SGDClassifier(loss='log')
model.fit(Xtrain, Ytrain)
SGDClassifier(loss='log')
5.9.5. 分類器の適用・評価#
学習した分類器のモデルを用い、評価データの先頭の事例を分類する。予測されたラベルのID番号は\(0\)なので、このメッセージは"ham"(スパムではない)と予測された。
model.predict(Xtest[0])
array([0])
モデルがこの事例を"ham"および"spam"と予測する確率を表示する。
model.predict_proba(Xtest[0])
array([[0.99567905, 0.00432095]])
評価データのすべての事例を使い、正解率を求める。
model.score(Xtest, Ytest)
0.9695340501792115
任意のテキストメッセージを分類モデルに適用する例。以下のメッセージはspamに分類された。
msg = "Your account has been credited with 500 FREE Text Messages."
model.predict_proba(VX.transform(vectorize(tokenize(msg))))
array([[0.30330529, 0.69669471]])
5.9.6. モデルパラメータの確認#
学習で求められたモデルのパラメータ(重み)はcoef_メンバ変数で確認できる。
model.coef_
array([[-8.37090795e-01, -1.76138728e-01, -7.74805758e-04, ...,
2.93789017e-02, -3.55600052e-01, -9.90864851e-04]])
特徴を表す単語とその重みのタプルからなるリストを作成し、重みが小さい順に並べたものを変数Fに格納する。
F = sorted(zip(VX.feature_names_, model.coef_[0]), key=lambda x: x[1])
重みの値が負に大きいトップ20の単語を表示する。\(y=0\)は"ham"に対応するので、これらの単語を含むメッセージは"ham"と予測されやすくなる。
F[:20]
[('<#>', -1.3558829924814004),
('me', -1.303455143586944),
('So', -1.14067222707557),
('him', -1.0598045974397776),
('i', -1.0030856587407084),
('my', -0.989036736792116),
('?', -0.9782504941221924),
('good', -0.9565766623762151),
('I', -0.9376350998709289),
('Its', -0.8771757171170732),
('how', -0.8669824265651959),
(':)', -0.8547153077528507),
('ask', -0.8455262058905626),
('Ok', -0.8390078922985393),
("I'll", -0.8386832325339574),
('', -0.8370907952027454),
('something', -0.8358732912496923),
('hi', -0.8223764866888945),
("i'm", -0.8157132793348036),
('&', -0.8138253181689464)]
重みの値が正に大きいトップ20の単語を表示する。\(y=1\)は"spam"に対応するので、これらの単語を含むメッセージは"spam"と予測されやすくなる。
F[-20:]
[("let's", 1.5410199592235803),
('-', 1.546029930147131),
('85233', 1.5646354767938881),
('FREE>Ringtone!Reply', 1.5646354767938881),
('To', 1.5765775613191408),
('Reply', 1.6688173510729016),
('84484', 1.7389287297155838),
('ringtoneking', 1.7389287297155838),
('146tf150p', 1.763641194218317),
('2/2', 1.763641194218317),
('text', 1.7664355866227701),
('won', 1.9273478586846209),
('service', 1.9282663075223407),
('&', 1.928861893331028),
('STOP', 2.0508768286731196),
('mobile', 2.059881177176412),
('now!', 2.112823595204192),
('txt', 2.1171488639279636),
('Txt', 2.119470386271705),
('Call', 2.374054661665122)]
5.10. 確認問題#
(1) 確率的勾配降下法によるロジスティック回帰モデルの学習
確率的勾配降下法でロジスティック回帰モデルを学習するアルゴリズムを自前で実装せよ。学習データや評価データは自由に選んでよい(難しければ、前節で用いたSMS Spam Collection Data Setを用いよ)。
(2) 評価データ上での正解率
評価データ上で学習したモデルの正解率を測定せよ。
(3) 学習で求めたパラメータ
学習で求めたモデルのパラメータのうち、重みの絶対値が大きいものトップ20を、重みが正のものと負のものに分けて表示せよ。