1. 単回帰#
Show code cell content
!pip install japanize-matplotlib
Requirement already satisfied: japanize-matplotlib in /home/okazaki/.local/lib/python3.8/site-packages (1.1.3)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.8/dist-packages (from japanize-matplotlib) (3.5.1)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (1.3.2)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (0.11.0)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (1.22.2)
Requirement already satisfied: pyparsing>=2.2.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (3.0.7)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (21.3)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (4.29.1)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (2.8.2)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (9.0.1)
Requirement already satisfied: six>=1.5 in /usr/lib/python3/dist-packages (from python-dateutil>=2.7->matplotlib->japanize-matplotlib) (1.14.0)
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches
import matplotlib.colors
import matplotlib.animation
from IPython.display import HTML
import japanize_matplotlib
1.1. 回帰とは#
\(\def\bm{\boldsymbol}\)「夏になるとかき氷が食べたくなる」「寒くなると温かい鍋を食べたくなる」「雨が降るとお店の客足が鈍る」など、我々の生活や行動は気象と密接に連動している。気象庁は気候リスク管理技術に関する調査(スーパーマーケット及びコンビニエンスストア分野):販売促進策に2週間先までの気温予測を活用するという資料を公開し、気象情報の活用による効率的な在庫管理や商品陳列を紹介している。
ここでは、新規オープンする売店の店長になったつもりで、アイスクリームの在庫管理について考えてみたい。売店の店長としては、商品の在庫をあまり抱えたくない。在庫は売れれば利益となるが、その売店の資金がモノに変化したことになるため、在庫を抱えている間はキャッシュフローが減少する。アイスクリームには賞味期限がないため、売れるまで辛抱強く待てばよいと思われるかもしれないが、冷凍庫で保管するにも保管スペースとコストがかかる。また、最中アイスなどは製造から時間が経過しすぎると、サクサク感が損なわれてしまう。一方で、暑い日にアイスクリームが売れすぎて、在庫を切らしてしまうと、せっかくの商機を失ってしまうことになる。

そこで、気象とアイスクリームの売れ行きの関係を調べ、アイスクリームの在庫の量を調整することを検討したい。例えば、天気予報で最高気温が摂氏30度と予想された日のアイスクリームの売れ行きを推測できれば、それに合わせてアイスクリームの発注を増やしたり、商品を陳列するスペースを増やすことが可能である。ところが、その売店は新しく商売を始めたため、アイスクリームの売れ行きに関する過去の販売データを持ち合わせていない。
そこで、2011年から2020年の東京における
\(x\): 最高気温(東京都の日最高気温の月平均)
\(y\): アイスクリーム・シャーベットへの支出額(一つの世帯が支出する金額の月平均)
の関係を表すデータを用いて、最高気温からアイスクリーム・シャーベットの支出額(以降「支出額」と略す)を近似的に計算する式を求め、売れ行きの傾向を把握したい。以下は、気象庁と総務省統計局が公開している統計データを加工し、グラフ化したものである。
Show code cell source
X = np.array([
9.1, 11.2, 12.3, 18.9, 22.2, 26. , 30.9, 31.2, 28.8, 23. , 18.3,
11.1, 8.3, 9.1, 12.5, 18.5, 23.6, 24.8, 30.1, 33.1, 29.8, 23. ,
16.3, 11.2, 9.6, 10.3, 16.4, 19.2, 24.1, 26.5, 31.4, 33.2, 28.8,
23. , 17.4, 12.1, 10.6, 9.8, 14.5, 19.6, 24.7, 26.9, 30.5, 31.2,
26.9, 23. , 17.4, 11. , 10.4, 10.4, 15.5, 19.3, 26.4, 26.4, 30.1,
30.5, 26.4, 22.7, 17.8, 13.4, 10.6, 12.2, 14.9, 20.3, 25.2, 26.3,
29.7, 31.6, 27.7, 22.6, 15.5, 13.8, 10.8, 12.1, 13.4, 19.9, 25.1,
26.4, 31.8, 30.4, 26.8, 20.1, 16.6, 11.1, 9.4, 10.1, 16.9, 22.1,
24.6, 26.6, 32.7, 32.5, 26.6, 23. , 17.7, 12.1, 10.3, 11.6, 15.4,
19. , 25.3, 25.8, 27.5, 32.8, 29.4, 23.3, 17.7, 12.6, 11.1, 13.3,
16. , 18.2, 24. , 27.5, 27.7, 34.1, 28.1, 21.4, 18.6, 12.3])
Y = np.array([
463., 360., 380., 584., 763., 886., 1168., 1325., 847.,
542., 441., 499., 363., 327., 414., 545., 726., 847.,
1122., 1355., 916., 571., 377., 465., 377., 362., 518.,
683., 838., 1012., 1267., 1464., 1000., 629., 448., 466.,
404., 343., 493., 575., 921., 1019., 1149., 1303., 805.,
739., 587., 561., 486., 470., 564., 609., 899., 946.,
1295., 1325., 760., 667., 564., 633., 478., 450., 567.,
611., 947., 962., 1309., 1307., 930., 668., 496., 650.,
506., 423., 531., 672., 871., 986., 1368., 1319., 924.,
716., 651., 708., 609., 535., 717., 890., 1054., 1077.,
1425., 1378., 900., 725., 554., 542., 561., 459., 604.,
745., 1105., 973., 1263., 1533., 1044., 821., 621., 601.,
549., 572., 711., 819., 1141., 1350., 1285., 1643., 1133.,
784., 682., 587.])
icecream_data = (X, Y)
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='.')
ax.set_title('最高気温とアイスクリーム・シャーベットの支出額')
ax.set_xlabel('最高気温の月平均(℃)')
ax.set_ylabel('支出額(円)')
ax.set_xlim(0, 35)
ax.set_ylim(-250, 2000)
ax.grid()
plt.show()
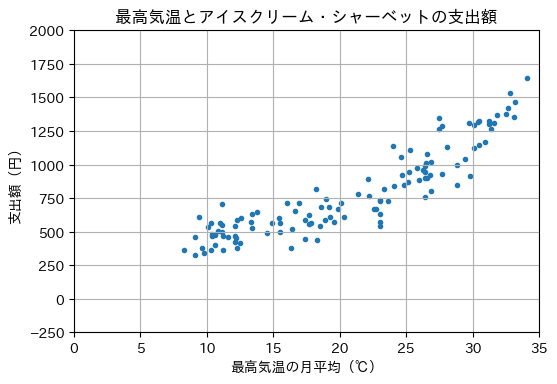
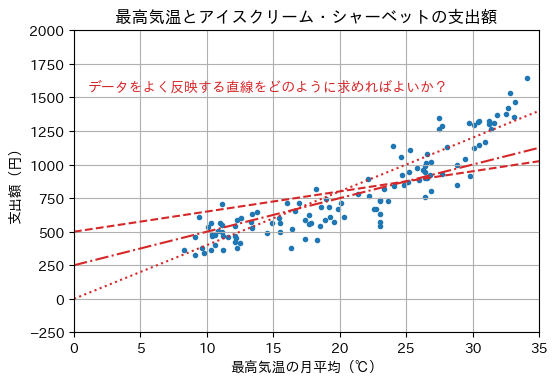
グラフから2次関数や指数関数の形が思い浮かぶが、まずは最も単純な場合として、最高気温(\(x \in \mathbb{R}\))と支出額(\(y \in \mathbb{R}\))の関係を1次関数に当てはめる(フィッティングさせる)ことを考える。 すなわち、1次関数の一般形、
を仮定し、\(x\)と\(y\)の関係を最も適切に表現するように、傾き\(a \in \mathbb{R}\)と切片\(b \in \mathbb{R}\)を決定したい。1次関数の一般形は\(a\)と\(b\)の値を変えることで無数の関数を表現できる(下図参照)。1次関数の一般形のように、説明したい対象(この場合はアイスクリーム・シャーベットの支出額)の形や構造を抽象化したものをモデル(model)と呼ぶ。モデルの中で説明したい対象を定量的に表現する変数(1次関数の一般形の例では\(a\)と\(b\))をパラメータ(parameter)と呼ぶ。データに合うようにモデルのパラメータ(この例では\(a\)と\(b\))を求めることをパラメータ推定(parameter estimation)と呼ぶ。
Show code cell source
X = np.array([0, 35])
fig, ax = plt.subplots(dpi=100)
ax.scatter(icecream_data[0], icecream_data[1], marker='.')
ax.plot(X, 15 * X + 500, ls='--', color='tab:red')
ax.plot(X, 25 * X + 250, ls='-.', color='tab:red')
ax.plot(X, 40 * X + 0, ls='dotted', color='tab:red')
ax.text(1, 1550, 'データをよく反映する直線をどのように求めればよいか?', color='tab:red')
ax.set_title('最高気温とアイスクリーム・シャーベットの支出額')
ax.set_xlabel('最高気温の月平均(℃)')
ax.set_ylabel('支出額(円)')
ax.set_xlim(0, 35)
ax.set_ylim(-250, 2000)
ax.grid()
plt.show()
ところで、人間は外気温が高くなるとアイスクリームやシャーベットなどの冷たいものを食べたくなる。 逆に、人間がアイスクリームやシャーベットを食べるから、外気温が上昇すると考えるのは不自然である。

ゆえに、最高気温からアイスクリーム・シャーベットの支出額の方向に因果関係があると考える。そこで、最高気温で支出額を説明することを考える。 支出額\(y\)のように、説明したい変数は目的変数(target variable)や被説明変数(explained variable)、従属変数(dependent variable)などと呼ばれる。 また、最高気温\(x\)のように、目的変数を説明するための変数は説明変数(explanatory variable)や独立変数(independent variable)などと呼ばれる。 目的変数が量的変数(quantitative variable)であるとき、すなわち説明変数から目的変数の数や量の大小を表現することを回帰(regression)と呼ぶ。 1次関数へのフィッティングのように、説明変数が1つの回帰を単回帰(simple regression)と呼び、単回帰によって求められた直線を回帰直線(regression line)と呼ぶ。 説明変数が2つ以上の回帰を重回帰(multiple regression)と呼び、次章以降で取り扱う。
ところで、回帰は目的変数が数値で表される問題であれば、様々な局面で応用できる。
採用予定の従業員の学歴、スキル、経験などから妥当な年俸額を算定する
地価、最寄り駅からの距離、築年数、床面積、間取りなどから妥当な家賃を算定する
最寄り駅、最寄り駅からの距離、周辺の人口などから、出店時の売上高を予想する
職業、年齢、年収、勤続年数、貯蓄額などから与信限度額を算定する
テレビ、ラジオ、インターネットなどに配信した広告に対する支出が売上高に与える影響を検証する
あるエリアにおいて使われていた携帯電話の台数から、そのエリアの滞在人口を推定する
なお、最後に挙げた例では、人間が携帯電話の位置を動かしているので、滞在人口から携帯電話の台数の方向に因果関係があると考えるべきである。ところが、この回帰分析では説明変数が滞在人口(因果関係における原因側)となっている。滞在人口は直接観測する(数える)のが難しいため、基地局やGPSなどで携帯電話の台数を観測することにして、携帯電話の台数を説明変数、滞在人口を目的変数としている。
1.2. データの表現#
先ほどの例は観測点が多いため、まずは簡単な例として以下のグラフで示された関係を考える。これは\(x\)を説明変数、\(y\)を目的変数として、\(xy\)平面上の4点\((1, 3), (3, 6), (6, 5), (8, 7)\)で構成されている。
D = np.array([[1, 3], [3, 6], [6, 5], [8, 7]])
Show code cell source
colormap = ['tab:red', 'tab:blue', 'tab:green', 'tab:orange']
offset_y = [0.5, 0.5, -0.5, -0.5]
xmin, xmax = 0, 10
ymin, ymax = 0, 10
def init_graph(dpi=100, grid=True):
fig, ax = plt.subplots(dpi=dpi, figsize=(6, 6))
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_xlim(xmin, xmax)
ax.set_ylim(ymin, ymax)
ax.set_aspect('equal')
if grid:
ax.grid()
return fig, ax
def plot_data(ax, D, offset_y=None, marker='o'):
A = []
for i, row in enumerate(D):
A.append(ax.scatter(D[i,0], D[i,1], marker=marker, color=colormap[i]))
if offset_y is not None:
A.append(ax.text(D[i,0], D[i,1] + offset_y[i], f'$(x_{i+1}, y_{i+1})$', ha='center'))
return A
fig, ax = init_graph()
plot_data(ax, D, offset_y)
plt.show()
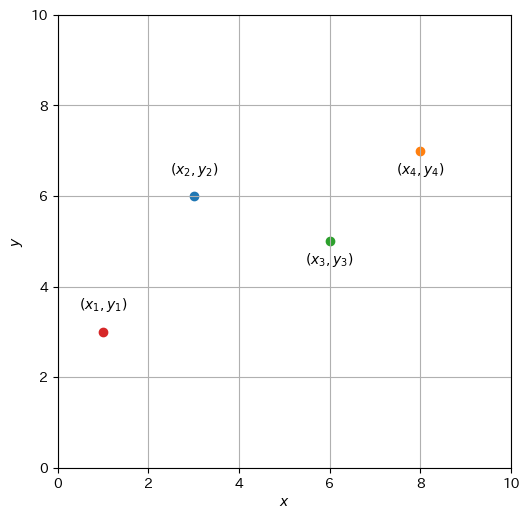
ここでは、説明変数と目的変数の一つの組を事例(instance)として表現する。1個以上の事例をまとめたものをデータ(data)と呼ぶ。 \(1\)番目の事例を\((x_1, y_1)\)、\(2\)番目の事例を\((x_2, y_2)\)、\(i\)番目の事例を\((x_i, y_i)\)と表すことにすると、\(N\)個の事例からなるデータ\(\mathcal{D}\)は次のように表される。
先ほどのグラフの例(\(N=4\))のデータ\(\mathcal{D}_{s}\)は次のように表現される。
データの説明変数\(x\)と目的変数\(y\)を対応付ける関数\(y=f(x)\)を回帰で求めることは、教師データ(supervision data)(もしくは学習データや訓練データ(training data)とも呼ばれる)を用いて、関数\(y = f(x)\)を教師あり学習(supervised learning)で求めると見なすことができる。関数を学習することで、説明変数と目的変数を対応付けるメカニズムの理解が深まるとともに、訓練データには無かった新しい事例(説明変数の値)に対し、その出力(目的変数の値)を予測することに役立つ。
1.3. 残差#
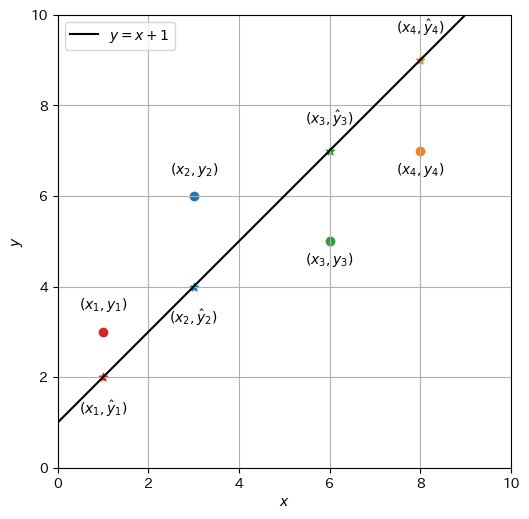
1次関数のモデル\(f_{a,b}(x) = ax + b\)において、傾き\(a\)と切片\(b\)に何らかの値を設定した状況を考える。与えられた\(x\)に1次関数を適用して計算された値を\(\hat{y} \in \mathbb{R}\)と書くことにする。説明変数\(x_i\)に対して、目的変数の実測値(観測値)\(y_i\)と、1次関数\(f_{a,b}(x_i)\)(モデル)から計算された予測値\(\hat{y}_i\)をハット(^)の有無で区別していることに注意されたい。
例えば、\(a = 1, b = 1\)に設定して\(y=x+1\)の回帰直線を考える。データ\(\mathcal{D}_s\)の各点\((x_i, y_i)\)と、回帰で計算された点\((x_i, \hat{y}_i)\)をプロットすると、以下のようになる。
Show code cell source
offset_hat_y = [-0.8, -0.8, 0.6, 0.6]
def plot_line(ax, a, b, label=None, color='black', alpha=1.):
if label is None:
label = f'$y = {a}x + {b}$' if a != 1 else f'$y = x + {b}$'
x = np.array([xmin, xmax])
return ax.plot(x, a * x + b, color, ls='-', label=label, alpha=alpha)
def plot_hat_y(ax, D, a, b, offset_hat_y, marker='*', show_text=True):
A = []
for i, row in enumerate(D):
x = D[i,0]
hat_y = a * x + b
A.append(ax.scatter(x, hat_y, marker=marker, color=colormap[i]))
if show_text:
A.append(ax.text(x, hat_y + offset_hat_y[i], f'$(x_{i+1}, \\hat{{y}}_{i+1})$', ha='center'))
return A
fig, ax = init_graph()
plot_data(ax, D, offset_y)
plot_line(ax, 1, 1)
plot_hat_y(ax, D, 1, 1, offset_hat_y)
plt.legend(loc='upper left')
plt.show()
さて、設定した\(a\)と\(b\)がどのくらいデータ\(\mathcal{D}\)をうまく反映しているのか測定したい。そこで、データ\(\mathcal{D}\)中に含まれる各点\((x_i, y_i)\)に関して、1次関数\(\hat{y}_i = f_{a,b}(x_i) = ax_i + b\)で近似した場合の実測値からのずれ、すなわち残差(residual)\(\epsilon_i \in \mathbb{R}\)を次のように定義する。
この残差\(\epsilon_i\)は、プロットされた点から回帰直線まで、\(y\)軸方向に差を取ったものである。例えば、データ\(\mathcal{D}_s\)に対して\(a = 1, b = 1\)としたとき、
以下に、各事例の残差\(\epsilon_i\)を点線で示した。
Show code cell source
offset_epsilon = [-0.3, -0.3, 0.3, 0.3]
def plot_error(plt, ax, D, a, b, offset_epsilon=None):
A = []
for i, row in enumerate(D):
x, y = row
y_hat = a * x + b
ymin = min(y, y_hat)
ymax = max(y, y_hat)
A.append(plt.vlines([x], ymin, ymax, linestyles='dashed', color=colormap[i], alpha=0.5))
if offset_epsilon is not None:
A.append(ax.text(x + offset_epsilon[i], (ymin + ymax) / 2, f'$\epsilon_{i+1}$', ha='center', va='center'))
return A
fig, ax = init_graph()
plot_data(ax, D, offset_y)
plot_line(ax, 1, 1)
plot_hat_y(ax, D, 1, 1, offset_hat_y)
plot_error(plt, ax, D, 1, 1, offset_epsilon)
plt.legend(loc='upper left')
plt.show()
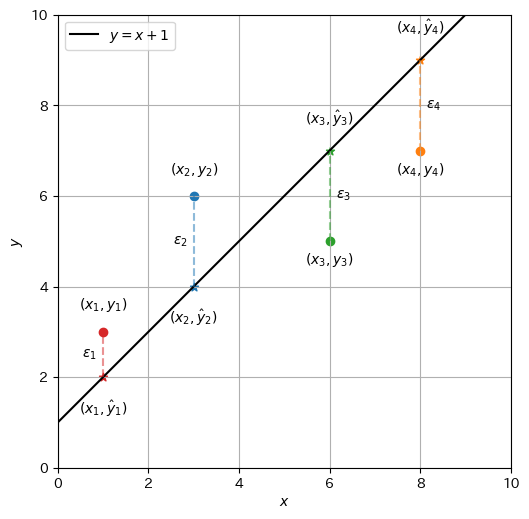
各事例における残差\(\epsilon_i\)を定義したので、次はデータ\(\mathcal{D}\)全体の残差を定義し、設定した\(a\)と\(b\)がどのくらいデータ\(\mathcal{D}\)をうまく反映しているのか、定量的に表現したい。ここで、各事例の残差の平均\(\frac{1}{N}\sum_{i=1}^N \epsilon_i\)を計算してしまうと、正と負の残差が相殺してしまう。ところが、各事例の残差の絶対値の平均\(\frac{1}{N}\sum_{i=1}^N |\epsilon_i|\)を取ると、数学的な取り扱いが煩雑になる。ここでは、平均二乗残差 (MSR: Mean Square Residual) を用いる。
ちなみに、先ほどのデータ\(\mathcal{D}_s\)に対する1次関数\(y = x + 1\)の平均二乗残差は、
なお、平均二乗残差は平均二乗誤差(MSE: Mean Square Error)と呼ばれることも多い。
1.4. 平均二乗残差は\(a,b\)の関数#
これまでの議論では、傾き\(a\)と切片\(b\)に具体的な値を与えていたが、\(a\)と\(b\)の値を変えることで異なる回帰直線を描画できる。以下は、\(a\)と\(b\)の値をランダムに試行しながら回帰直線を描画し、その平均二乗残差を計算するアニメーションである。\(a\)と\(b\)の値により回帰直線が決定され、その回帰直線がデータ点に近い所を通るとき、平均二乗残差(MSR)の値が小さくなる。過去に試行した\(a\)と\(b\)のうち、最も平均二乗残差が小さい回帰直線を赤色で示している。
Show code cell source
def generate_parameter(L = 1000, xwidth=10, ymin=0, ymax=10):
A = np.random.rand(L)
B = np.random.rand(L) * (ymax - ymin) + ymin
for i, b in np.ndenumerate(B):
amax = (ymax - b) / xwidth
amin = (ymin - b) / xwidth
A[i] = np.random.rand() * (amax - amin) + amin
return np.column_stack((A, B))
K = 5
np.random.seed(seed=5)
P = generate_parameter(100)
fig, ax = init_graph(grid=False)
plot_data(ax, D)
best = (None, None, None, None)
artists = []
for i in range(len(P)+K):
# Update the best parameter if necessary.
if i < len(P):
a, b = P[i][0], P[i][1]
msr = ((D[:,1] - a * D[:,0] - b) ** 2).mean()
if best[0] is None or msr < best[1]:
best = (i, msr, a, b)
artist = []
msg_current = ''
# Draw the current best line.
artist += plot_line(ax, best[2], best[3], color='tab:red')
msg_best = "(Current best: $a$ = {0[2]:.2f}, $b$ = {0[3]:.1f}: MSR = ${0[1]:.2f}$)".format(best)
# Draw recent lines.
for k in range(K):
j = i-k
if j < 0 or len(P) <= j:
continue
if j != best[0]:
a, b = P[j][0], P[j][1]
artist += plot_line(ax, a, b, color='black', alpha=1.0 / (k+1))
if k == 0:
artist += plot_hat_y(ax, D, a, b, offset_hat_y, show_text=False)
artist += plot_error(plt, ax, D, a, b)
msg_current = f"$a$ = {a:.2f}, $b$ = {b:.1f}: MSR = ${msr:.2f}$"
artist.append(ax.text(5, 0.6, msg_current + '\n' + msg_best, color='tab:red', ha='center'))
artists.append(artist)
ani = matplotlib.animation.ArtistAnimation(fig, artists, interval=100, repeat=False)
html = ani.to_jshtml()
plt.close(fig)
HTML(html)
このように、パラメータの値をランダムに試すことで、データをある程度反映した回帰直線を求めることができたが、この求め方は非効率である。また、良さそうな回帰直線を引くことができたとしても、それが最良であるという保証も得られない。
ところで、教師あり学習では、学習データ\(\mathcal{D}\)が与えられ、その学習データをよく反映するパラメータを求める。したがって、式(1.7)は学習データ\(\mathcal{D}\)を定数とした、パラメータ\(a\)と\(b\)の関数と見なすことができる。そこで、平均二乗残差を変数\(a, b\)の関数として整理してみよう。
ここで、\(\bar{x}\)や\(\bar{y}\)などは学習データ\(\mathcal{D}\)における各変数の標本平均である。説明変数の確率変数を\(\mathcal{X}\)、目的変数の確率変数を\(\mathcal{Y}\)で表すことにすると、
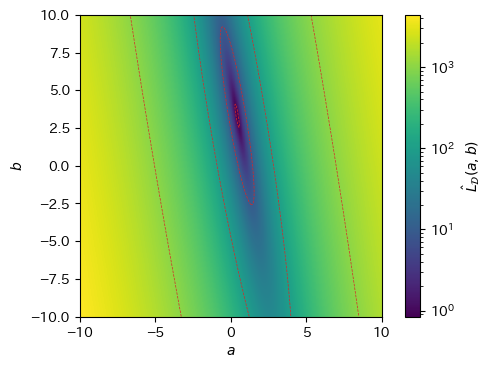
以上のことから、平均二乗残差\(\hat{L}_{\mathcal{D}}(a,b)\)は\(a\)と\(b\)に関する2次関数で、その関数はデータ\(\mathcal{D}\)から統計的に求まる値によって決定されることが分かる。\(a\)を横軸、\(b\)を縦軸として\(\hat{L}_\mathcal{D}(a, b)\)の値をヒートマップで描画してみると、\((a, b) \approx (0.5, 3)\)付近で平均二乗残差が最小になりそうであることが分かる。実際、\(\hat{L}_\mathcal{D}(a, b)\)は凸関数であり、その値を最小にする\(a, b\)が存在する(\(\hat{L}_\mathcal{D}(a, b)\)が凸関数であることは次章で証明する)。
Show code cell source
def msr(a, b, D):
xm = np.mean(D[:,0])
ym = np.mean(D[:,1])
x2m = np.mean(D[:,0] ** 2)
y2m = np.mean(D[:,1] ** 2)
xym = np.mean(D[:,0] * D[:,1])
return x2m * (a ** 2) + b ** 2 + 2 * xm * a * b - 2 * xym * a - 2 * ym * b + y2m
N = 1000
A, B = np.meshgrid(np.linspace(-10, 10, N), np.linspace(-10, 10, N))
J = msr(A, B, D)
fig, ax = plt.subplots(dpi=100)
ax.set_aspect('equal')
ax.set_xlabel('$a$')
ax.set_ylabel('$b$')
# Draw a heat map on a logarithmic scale of MSR.
mesh = ax.pcolormesh(A, B, J, norm=matplotlib.colors.LogNorm(vmin=J.min(), vmax=J.max()), shading='auto')
cbar = fig.colorbar(mesh)
cbar.set_label('$\hat{L}_{\mathcal{D}}(a,b)$')
# Draw a contour map (clip loss values not to draw lines in smaller area)
ax.contour(
A, B, np.clip(J, 1e-3, None), vmin=1, colors='tab:red', linewidths=0.5, linestyles='dashed',
norm=matplotlib.colors.LogNorm(vmin=J.min(), vmax=J.max()))
plt.show()
そこで、平均二乗残差を最小化するパラメータを解析的に求める方法を説明する。平均二乗残差のように、モデルの予測値と正解値(実測値)とのずれを計測する関数を、損失関数(loss function)と呼ぶ。したがって、今回の単回帰モデルの学習は、「平均二乗残差で定義される損失関数を最小化することにより、単回帰モデルのパラメータを推定する」と整理することができる。なお、機械学習や数理最適化において最小化や最大化の対象となる関数を目的関数(objective function)と呼ぶ。しばしば、損失関数のことを目的関数と言い換えることがあるが、損失関数よりも目的関数の方がより広い概念を表す。また、二乗和で表現される目的関数を最小化することで、パラメータを求める方法のことを最小二乗法(least squares)と呼ぶ。
1.5. 平均二乗残差を最小化する#
これまでの議論により、データ\(\mathcal{D}\)を1次関数で近似的に表現するための傾き\(a\)と切片\(b\)を求める問題は、以下の目的関数(平均二乗残差)を最小にする\(a\)と\(b\)を求める問題に帰着した。
単回帰の目的関数(平均二乗残差)
この目的関数\(\hat{L}_{\mathcal{D}}(a,b)\)の値が最小となる点を\((a^*, b^*)\)と書くことにすると、
が成り立つ。そこで、以降ではこの条件を満たす\(a^*, b^*\)を求める。ただし、表記を簡単にするため、導出においてはアスタリスク(*)を付けず、\(a, b\)のまま説明する。
まず、式(1.11)(目的関数)を\(a\)と\(b\)で偏微分する。
式(1.14)を\(0\)とおくと、
なお、以降の式展開において都合がよいので、\(\frac{1}{N}\)を残している。\(b\)を求めるために式変形を続けると、
ここで、式(1.10)で定義した平均の記法で右辺を表現すると、
次に、式(1.13)を\(0\)とおくと、
以降の式展開において都合がよいので、今回も\(\frac{1}{N}\)を残している。\(a\)を求めるために式変形を続けると、
ここで、式(1.10)で定義した平均の記法を導入すると、
\(b\)に式(1.17)を代入し、\(a\)について解くと、
ところで、確率変数\(\mathcal{X}\)と\(\mathcal{Y}\)の共分散は、
また、確率変数\(\mathcal{X}\)の分散は、
まとめると、目的関数\(\hat{L}_{\mathcal{D}}(a,b)\)の値を最小にするパラメータは次式で求めればよい。
単回帰のパラメータを求める式
1.5.1. 実際に\(a\)と\(b\)を求めてみる#
さて、例として用いているデータ\(\mathcal{D}_s\)
に対して、\(a\)と\(b\)を求める。まず、データ\(\mathcal{D}_s\)に対して必要な統計量を求める。
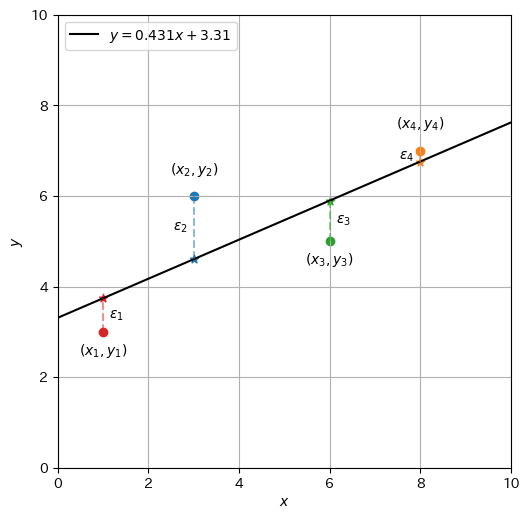
この計算結果から、最小二乗法による回帰直線の傾きと切片の推定値\(a\)と\(b\)は、次のように求めることができる。
したがって、最小二乗法で求まる回帰直線は\(\hat{y} = 0.431x + 3.310\)である。データ\(\mathcal{D}_s\)と一緒にプロットしたグラフを作成してみると、\(a=1, b=1\)の時よりも残差が減少していることが分かる。
Show code cell source
a, b = 0.431, 3.310
offset_y_new = [-0.5, 0.5, -0.5, 0.5]
offset_epsilon_new = [0.3, -0.3, 0.3, -0.3]
fig, ax = init_graph()
plot_data(ax, D, offset_y_new)
plot_line(ax, a, b)
plot_hat_y(ax, D, a, b, offset_hat_y, show_text=False)
plot_error(plt, ax, D, a, b, offset_epsilon_new)
plt.legend(loc='upper left')
plt.show()
1.6. 回帰直線の性質#
1.6.1. 回帰直線の傾き#
さて、最小二乗法で推定された回帰直線の傾き\(a\)はどのような値なのか。まず、\(a\)の分子である\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)について見ていきたい。
ここで、\((x_i - \overline{x})\)はデータ中の点の\(x\)軸の値の平均からのずれを表している。同様に、\((y_i - \overline{y})\)はデータ中の点の\(y\)軸の値の平均からのずれを表している。ゆえに、データ中の点が以下の性質を持つとき、\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)は正に大きくなりやすい。
\(x\)軸の値が平均よりも大きい点において、\(y\)軸の値も平均よりも大きい
\(x\)軸の値が平均よりも小さい点において、\(y\)軸の値も平均よりも小さい
逆に、データ\(\mathcal{D}\)中の点が以下の性質を持つとき、\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)は負になりやすい。
\(x\)軸の値が平均よりも大きい点において、\(y\)軸の値が平均よりも小さい
\(x\)軸の値が平均よりも小さい点において、\(y\)軸の値が平均よりも大きい
Show code cell source
def draw_means(ax, D):
xm = np.mean(D[:,0])
ym = np.mean(D[:,1])
plt.vlines([xm], xmin, xmax, "black", linestyles='dashed', label=r"$\bar{x}$")
plt.hlines([ym], ymin, ymax, "black", linestyles='dotted', label=r"$\bar{y}$")
def draw_regions(ax, D):
xm = np.mean(D[:,0])
ym = np.mean(D[:,1])
ax.add_patch(
matplotlib.patches.Rectangle((0, 0), xm, ym, facecolor='red', alpha=0.1, fill=True))
ax.add_patch(
matplotlib.patches.Rectangle((xm, ym), 10-xm, 10-ym, facecolor='red', alpha=0.1, fill=True))
ax.add_patch(
matplotlib.patches.Rectangle((0, ym), xm, ym, facecolor='blue', alpha=0.1, fill=True))
ax.add_patch(
matplotlib.patches.Rectangle((xm, 0), 10-xm, ym, facecolor='blue', alpha=0.1, fill=True))
fig, ax = init_graph()
plot_data(ax, D)
draw_means(ax, D)
draw_regions(ax, D)
plt.legend(loc='upper left')
plt.show()
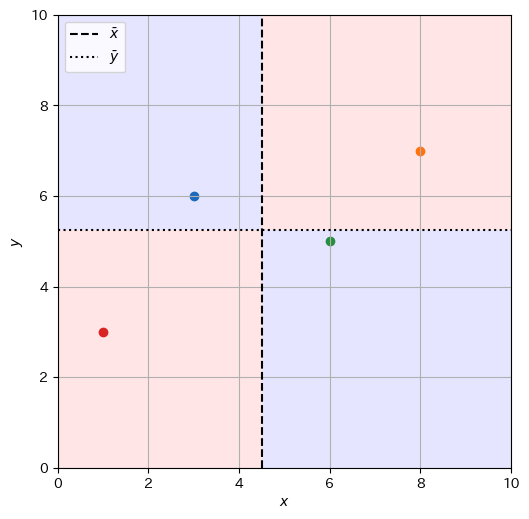
この状況をデータ\(\mathcal{D}_s\)に関して図示したのが上のグラフである。このデータ\(\mathcal{D}_s\)では\(x\)軸の平均値\(\overline{x} = 4.5\)を縦の点線で、\(y\)軸の平均値\(\overline{y} = 5.25\)を横の点線で示した。この2つの点線が交わる点\((4.5, 5.25)\)をデータ\(\mathcal{D}_s\)の重心と呼ぶ。 さらに、\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)が正になりやすい領域を赤で、負になりやすい領域を青で示した。データ中の点が赤の領域に多く入り、かつそれらの点が重心から遠いほど、\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)の値が正になりやすい。逆に、データ中の点が青の領域に多く入り、かつそれらの点が重心から遠いほど、\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)の値が負になりやすい。このことから、データに\(x\)が増加すると\(y\)も増加する傾向があるならば共分散\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)が正になりやすく、傾き\(a\)の値が正となる。逆に、\(x\)が増加すると\(y\)は減少する傾向があるならば、データの共分散\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)が負になりやすく、傾き\(a\)の値が負になる。
このイメージをより具体的に説明したい。まず、共分散の定義を再掲する。
ここで、\(\sum\)の中身はデータ中の各点における\((x_i - \overline{x})(y_i - \overline{y})\)である。これは、データ中の各点\((x_i, y_i)\)と重心を頂点とする長方形を考え、その面積を計算したものである。ただし、データ中の点が重心の左上もしくは右下にあるときは、面積は負の値をとると考える。このようにして計算した面積の平均を計算するのが\(x\)と\(y\)の共分散\(\mathrm{Cov}[\mathcal{X},\mathcal{Y}]\)である。
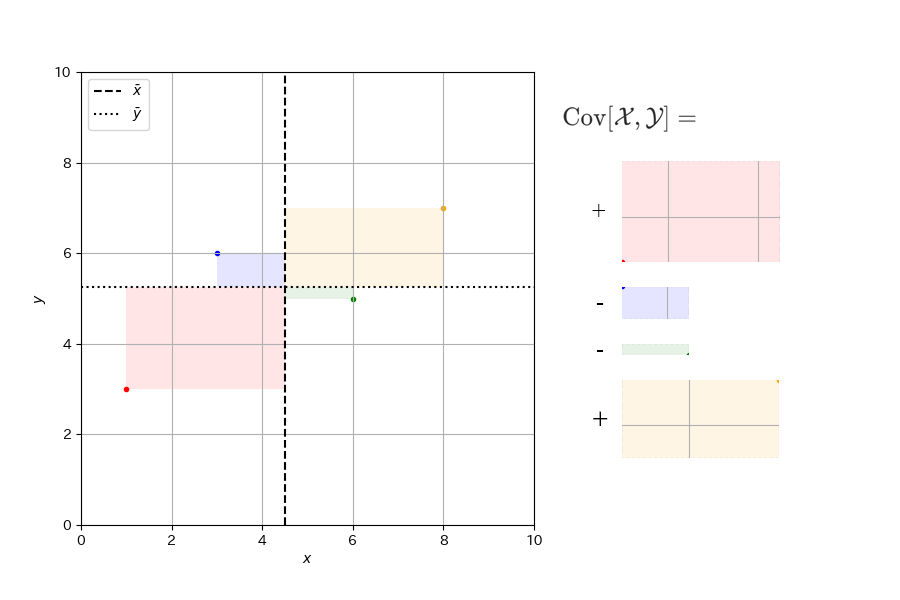
続いて\(a\)の分母を説明する。これは、\(x\)の分散\(\mathrm{Var}[\mathcal{X}]\)である。
ここで、\(\sum\)の中身はデータ中の各点における\((x_i - \overline{x})^2\)である。これは、データ中の各点に対して、重点を頂点として一辺の長さが\(|x_i - \overline{x}|\)の正方形を考え、その面積を計算したものである。このようにして計算した各点の面積の平均を計算するのが\(x\)の分散\(\mathrm{Var}[\mathcal{X}]\)である。
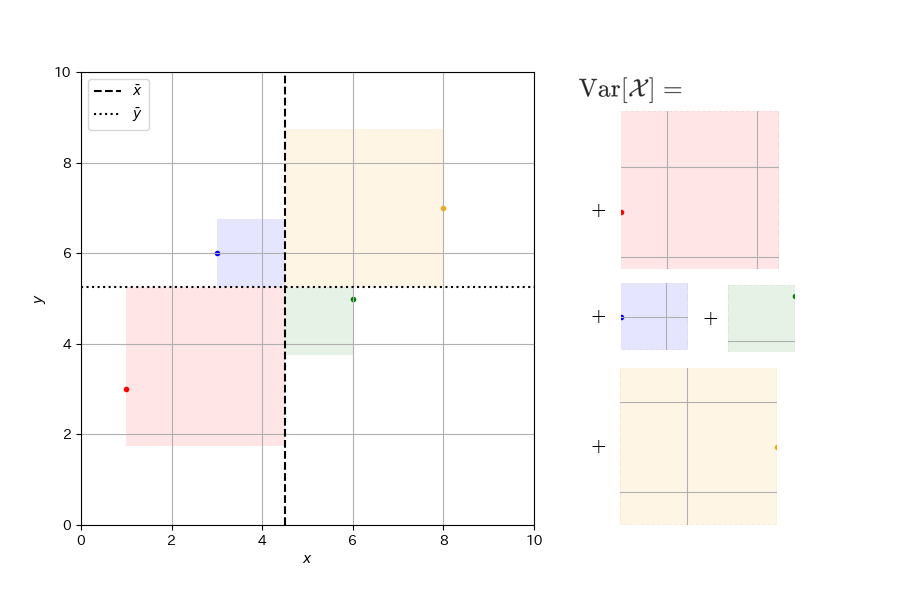
回帰直線の傾き\(a\)は、\(x\)と\(y\)の共分散の大きさを\(x\)の分散の値で割ったものであるから、以下のような計算を行っているとイメージするとよい。
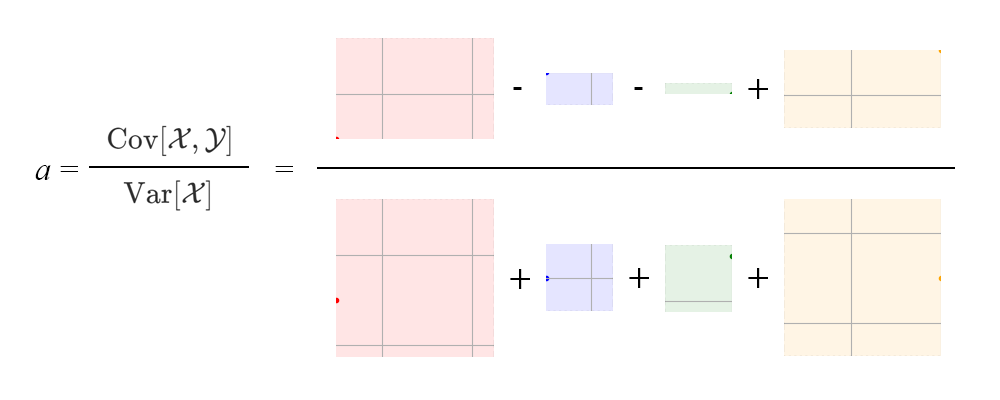
1.6.2. 目的変数の推定値\(\hat{y}\)の平均値は観測値\(y\)の平均に等しい#
式(1.25)は何を表しているのだろうか。この式を目的変数の平均値\(\overline{y}\)を表す式に書き直して整理すると、目的変数の推定値の平均値\(\overline{\hat{y}}\)と等しくなることが分かる。
ゆえに、目的変数の推定値\(\hat{y}\)の平均値は観測値\(y\)の平均に等しい。ここで、\(a\overline{x}\)はデータ\(\mathcal{D}\)の説明変数の平均値\(\overline{x}\)を回帰係数\(a\)で\(y\)軸の値に変換している。説明変数のデータを回帰係数\(a\)で目的変数の空間に写像したとき、目的変数の推定値の平均\(\overline{\hat{y}}\)が観測値の平均\(\overline{y}\)に等しくなるように、バイアスを調整するのが\(b\)である。
1.6.3. 回帰直線は観測データの重心を通る#
これまでの議論の中で、回帰直線はデータ\(\mathcal{D}\)の重心を「中心」と考えて\(x\)と\(y\)の対応付けを考えていることが分かる。実際、\(x = \overline{x}\)として目的変数の推定値\(\hat{y}\)を求めると、式(1.25)より、
となることから、回帰直線は重心\((\overline{x}, \overline{y})\)を通ることが確認できる。
Show code cell source
def draw_slope(ax, D, b):
xm = np.mean(D[:,0])
ym = np.mean(D[:,1])
plt.hlines([b], 0, xm, "tab:brown")
plt.vlines([xm], b, ym, "tab:brown")
plt.text(xm / 2, b - 0.1, "$\\bar{x}$", color="tab:brown", va='top', ha='center')
plt.text(xm + 0.1, b + (ym - b) / 2, "$a\\bar{x}$", color="tab:brown", va='center', ha='left')
a, b = 0.431, 3.310
fig, ax = init_graph()
plot_data(ax, D)
plot_line(ax, a, b)
draw_means(ax, D)
draw_regions(ax, D)
draw_slope(ax, D, b)
plt.legend(loc='upper left')
plt.show()
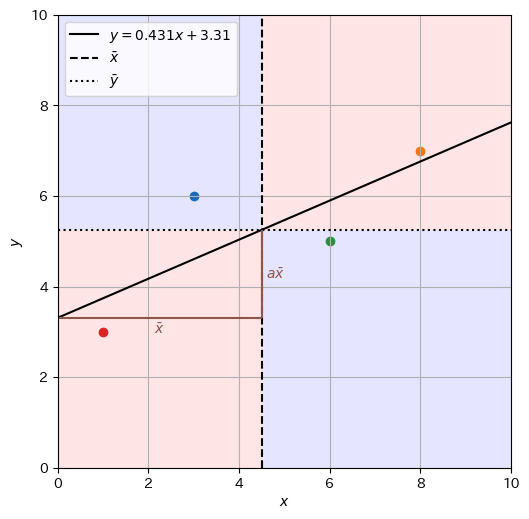
1.6.4. 残差の和および平均は\(0\)#
以下の計算により、残差の和および平均は\(0\)であることが分かる。
なお、下から2行目が\(0\)に等しいことは、式(1.15)による。
1.6.5. 説明変数と残差には相関がない#
説明変数と残差の共分散を計算してみる。残差の和および平均は\(0\)であることに注意すると、
なお、下から2行目の第二項が\(0\)に等しいことは、式(1.33)による。さらに、
であるから、\(\mathrm{Cov}[\mathcal{X},\mathcal{E}] = 0\)が言える。すなわち、説明変数と残差の共分散が\(0\)になることから、説明変数と残差は無相関(無関係)であることが分かる。なお、最後の式展開は、式(1.18)による。
1.6.6. 目的変数の推定値\(\hat{y}\)と残差には相関がない#
目的変数の推定値\(\hat{y}\)と残差の共分散を計算してみる。残差の和および平均は\(0\)であること、式(1.35)を踏まえると、
であるから、\(\mathrm{Cov}[\hat{\mathcal{Y}},\mathcal{E}] = 0\)が言える。すなわち、目的変数の推定値と残差の共分散が0になることから、目的変数の推定値と残差は無相関(無関係)であることが分かる。なお、最後の式展開は、式(1.35)と式(1.33)による。
1.7. 決定係数#
目的変数の観測値の分散\(\mathrm{Var}[\mathcal{Y}]\)は目的変数の推定値の分散\(\mathrm{Var}[\hat{\mathcal{Y}}]\)と残差の分散\(\mathrm{Var}[\mathcal{E}]\)の和で表されることを示す。
なお、下から2行目において、第2項は式(1.36)の導出過程、第3項は式(1.33)より\(0\)であることを利用した。
ここで、以下の用語を整理する。
全変動: 目的変数の観測値の分散\(\mathrm{Var}[\mathcal{Y}]\)(データの変動)
回帰変動: 目的変数の推定値の分散\(\mathrm{Var}[\hat{\mathcal{Y}}]\)(モデルの変動)
残差変動: 残差の分散\(\mathrm{Var}[\mathcal{E}]\)(モデルが説明しきれなかった変動)
すると、先ほどの式は「全変動は回帰変動と残差変動の和で表される」という関係を表している。
データの全変動のうち、回帰によって表現できた回帰変動の割合を決定係数とよび、次式で定義する。
決定係数
決定係数は\([0,1]\)の範囲の値ととり、データがモデル(単回帰の場合は直線)によく当てはまるときは\(1\)に近くなる。
1.8. 単回帰の実施例#
冒頭の最高気温とアイスクリーム・シャーベットの支出額のデータに対して、単回帰を行う例を示す。このJupyter Notebookの冒頭でデータをicecream_dataという変数に格納してあったので、説明変数(最高気温)Xと目的変数(支出額)をYに分離する。
X, Y = icecream_data
Xには最高気温が配列(numpy.array)に格納されている。
X
array([ 9.1, 11.2, 12.3, 18.9, 22.2, 26. , 30.9, 31.2, 28.8, 23. , 18.3,
11.1, 8.3, 9.1, 12.5, 18.5, 23.6, 24.8, 30.1, 33.1, 29.8, 23. ,
16.3, 11.2, 9.6, 10.3, 16.4, 19.2, 24.1, 26.5, 31.4, 33.2, 28.8,
23. , 17.4, 12.1, 10.6, 9.8, 14.5, 19.6, 24.7, 26.9, 30.5, 31.2,
26.9, 23. , 17.4, 11. , 10.4, 10.4, 15.5, 19.3, 26.4, 26.4, 30.1,
30.5, 26.4, 22.7, 17.8, 13.4, 10.6, 12.2, 14.9, 20.3, 25.2, 26.3,
29.7, 31.6, 27.7, 22.6, 15.5, 13.8, 10.8, 12.1, 13.4, 19.9, 25.1,
26.4, 31.8, 30.4, 26.8, 20.1, 16.6, 11.1, 9.4, 10.1, 16.9, 22.1,
24.6, 26.6, 32.7, 32.5, 26.6, 23. , 17.7, 12.1, 10.3, 11.6, 15.4,
19. , 25.3, 25.8, 27.5, 32.8, 29.4, 23.3, 17.7, 12.6, 11.1, 13.3,
16. , 18.2, 24. , 27.5, 27.7, 34.1, 28.1, 21.4, 18.6, 12.3])
Yにはアイスクリーム・シャーベットの売上高が配列(numpy.array)に格納されている。
Y
array([ 463., 360., 380., 584., 763., 886., 1168., 1325., 847.,
542., 441., 499., 363., 327., 414., 545., 726., 847.,
1122., 1355., 916., 571., 377., 465., 377., 362., 518.,
683., 838., 1012., 1267., 1464., 1000., 629., 448., 466.,
404., 343., 493., 575., 921., 1019., 1149., 1303., 805.,
739., 587., 561., 486., 470., 564., 609., 899., 946.,
1295., 1325., 760., 667., 564., 633., 478., 450., 567.,
611., 947., 962., 1309., 1307., 930., 668., 496., 650.,
506., 423., 531., 672., 871., 986., 1368., 1319., 924.,
716., 651., 708., 609., 535., 717., 890., 1054., 1077.,
1425., 1378., 900., 725., 554., 542., 561., 459., 604.,
745., 1105., 973., 1263., 1533., 1044., 821., 621., 601.,
549., 572., 711., 819., 1141., 1350., 1285., 1643., 1133.,
784., 682., 587.])
以下はグラフを書くためのプログラムである。
def show_graph(X, Y, x, y):
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='.')
ax.plot(x, y, 'tab:red')
ax.set_title('最高気温とアイスクリーム・シャーベットの支出額')
ax.set_xlabel('最高気温の月平均(℃)')
ax.set_ylabel('支出額(円)')
ax.set_xlim(0, 35)
ax.set_ylim(-250, 2000)
ax.grid()
plt.show()
1.8.1. numpy.polyfit#
numpy.polynomial.Polynomialを用いると、線形回帰モデルのパラメータを求めることができる。単回帰の場合は、fitメソッドの3番目の引数(次元数)に1を指定する。返り値であるオブジェクトWから切片と傾きを得るには、convert().coefを用いる(これはおまじないだと思った方がよい)。
from numpy.polynomial import Polynomial
W = Polynomial.fit(X, Y, 1)
W.convert().coef
array([-8.26568744, 38.46344295])
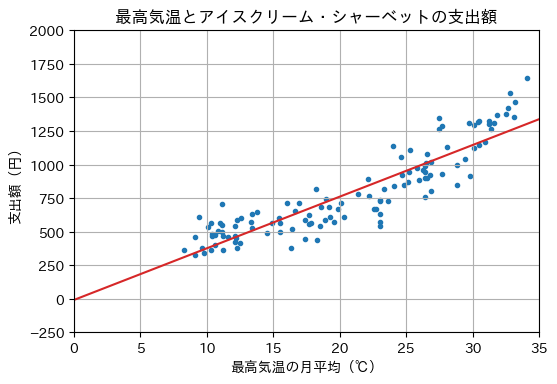
\(0\)から\(35\)までに等間隔に配置した\(100\)個の数値xに対して、目的変数の推定値y_hatを求め、回帰直線を描画する。
x = np.linspace(0, 35, 100)
y_hat = W(x)
show_graph(X, Y, x, y_hat)
1.8.2. sklearn.linear_model.LinearRegression#
from sklearn.linear_model import LinearRegression
sklearn.linear_model.LinearRegressionクラスを用いても、線形回帰を容易に実行できる。訓練データにフィッティングさせるには、fit関数を呼び出せばよいが、説明変数のデータとして、事例数を行数、目的変数の数を列数とした行列形式で与えることになっているので、Xの形状を変更する。
reg = LinearRegression()
reg.fit(X.reshape(-1, 1), Y)
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
回帰直線の係数(傾き)を表示する。
reg.coef_
array([38.46344295])
回帰直線の切片を表示する。
reg.intercept_
-8.265687440297484
決定係数を求めるため、score関数を呼び出す。
reg.score(X.reshape(-1, 1), Y)
0.8123821444273189
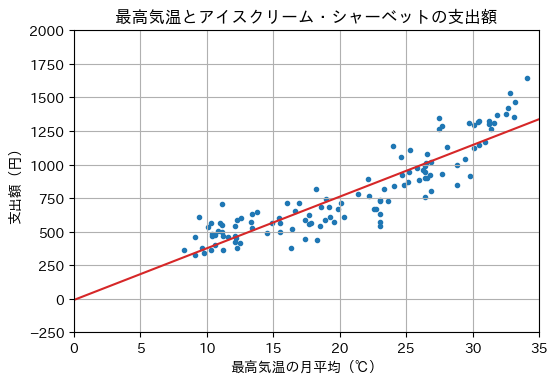
\(0\)から\(35\)までに等間隔に配置した\(100\)個の数値xに対して、目的変数の推定値y_hatを求めるため、predict関数を呼び出し、回帰直線を描画する。
x = np.linspace(0, 35, 100)
y_hat = reg.predict(x.reshape(-1, 1))
show_graph(X, Y, x, y_hat)
1.9. 確認問題#
以下のデータ\(\mathcal{D}_s\)に対して単回帰分析を行うプログラムを実装せよ。
D = np.array([[1, 3], [3, 6], [6, 5], [8, 7]])
X = D[:,0]
Y = D[:,1]
なお、NumPy, SciPy, scikit-learn, statsmodel等のライブラリには回帰分析を行う便利な関数がある(下記参照)が、ここでは使わずに本資料で説明した式をプログラムとして表現すること。
(1) 単回帰の実装
\(\mathcal{D}_s\)に対して単回帰を行うプログラムを実装し、回帰直線\(\hat{y}=ax+b\)の係数\(a\)と\(b\)の値を求めよ
(2) 回帰直線の描画
単回帰の実装で求めた回帰直線をデータ点とともにグラフに描け
(3) 残差の計算
各事例\((x_i, y_i)\)に対して残差\(\hat{\epsilon}_i\)を求めよ
(4) 説明変数と残差の共分散
説明変数と残差の共分散を求めよ
(5) 目的変数の推定値と残差の共分散
目的変数の推定値と残差の共分散を求めよ
(6) 決定係数
決定係数(\(R^2\))を求めよ