2. 重回帰#
Show code cell content
!pip install japanize-matplotlib
Requirement already satisfied: japanize-matplotlib in /home/okazaki/.local/lib/python3.8/site-packages (1.1.3)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.8/dist-packages (from japanize-matplotlib) (3.5.1)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (1.22.2)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (1.3.2)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (2.8.2)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (4.29.1)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (21.3)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (9.0.1)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (0.11.0)
Requirement already satisfied: pyparsing>=2.2.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (3.0.7)
Requirement already satisfied: six>=1.5 in /usr/lib/python3/dist-packages (from python-dateutil>=2.7->matplotlib->japanize-matplotlib) (1.14.0)
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
2.1. 重回帰#
\(\def\bm{\boldsymbol}\)これまで、以下のデータ\(\mathcal{D}_s\)を例として単回帰を説明した。
また、求めた回帰直線をデータ点とともにプロットしたものを以下に示す。
Show code cell source
a, b = 0.431, 3.310
D = np.array([[1, 3], [3, 6], [6, 5], [8, 7]])
fig, ax = plt.subplots(dpi=100, figsize=(6, 6))
ax.scatter(D[:,0], D[:,1], marker='o')
x = np.array([0, 10])
ax.plot(x, a * x + b, 'tab:red', ls='-', label=f'$y = {a}x + {b}$')
for i, row in enumerate(D):
x, y = row
y_hat = a * x + b
plt.vlines([x], min(y, y_hat), max(y, y_hat), "tab:blue", linestyles='dashed')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.set_aspect('equal')
ax.grid()
plt.legend(loc='upper left')
plt.show()
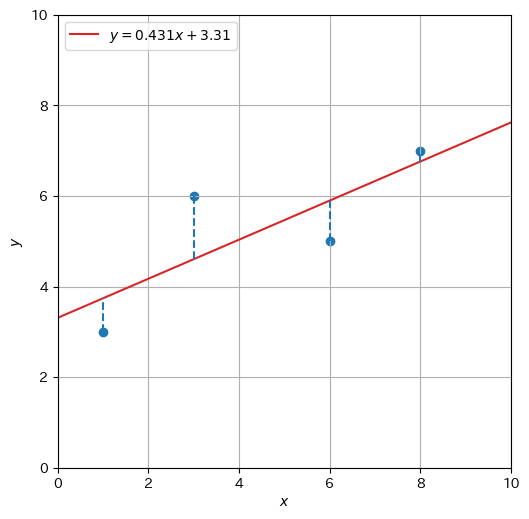
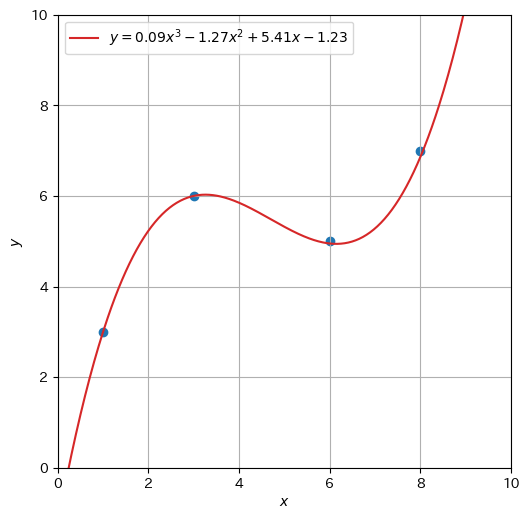
残差の平均二乗和が最小になるような直線を引いたはずであるが、残差を完全に無くすことはできなかった(決定係数を求めてみると\(0.616\)であり、あまり高くない)。プロットされている点を眺めると、3次関数を当てはめる方が向いているように思われる。そこで、1次関数よりも表現力が高いモデルとして、\(d\)次の多項式の一般形、
にフィッティングすることを考えたい。ここで、\(w_0, w_1, w_2, \dots, w_d \in \mathbb{R}\)はモデルのパラメータである。
なお、\(\hat{y}\)は重み\(w_0, w_1, w_2, \dots, w_d\)による説明変数\(1, x, x^2, \dots x^d\)の線形重み付き和と考えることができる。このモデルは多項式の一般形ではあるが、\(\hat{y}\)は\(w_i\)と\(x^i\)の線形結合で表されているため、線形モデルと見なすことができる。ただし、説明変数が2個以上であるので、単回帰を重回帰に拡張する必要がある。
一般的に、\(d\)個の説明変数\(x_1, x_2, \dots, x_d\)に対して、線形モデル、すなわち\(d\)個の重み\(w_1, w_2, \dots, w_d\)の線形結合で目的変数の予測値\(\hat{y}\)を計算することを線形回帰と呼ぶ。
ゆえに、\((d-1)\)次の多項式へのフィッティングは、\(d\)個の説明変数\(x_1 = 1\), \(x_2 = x\), \(x_3 = x^2\), \(\dots\), \(x_d = x^{d-1}\)による線形回帰と見なすことができる。下図は、重回帰でデータ\(\mathcal{D}_s\)に3次関数を当てはめた結果である。本章の内容をマスターすると、\(4\)個の説明変数\(1, x, x^2, x^3\)に対して、その重み(\(-1.23, 5.41, -1.27, 0.09\))を求めることができる。
Show code cell source
a, b = 0.431, 3.310
D = np.array([[1, 3], [3, 6], [6, 5], [8, 7]])
fig, ax = plt.subplots(dpi=100, figsize=(6, 6))
ax.scatter(D[:,0], D[:,1], marker='o')
x = np.linspace(0, 10, 500)
ax.plot(x, 0.09 * x ** 3 - 1.27 * x ** 2 + 5.41 * x - 1.23, 'tab:red', ls='-', label='$y = 0.09 x^3 - 1.27 x^2 + 5.41 x - 1.23$')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.set_aspect('equal')
ax.grid()
plt.legend(loc='upper left')
plt.show()
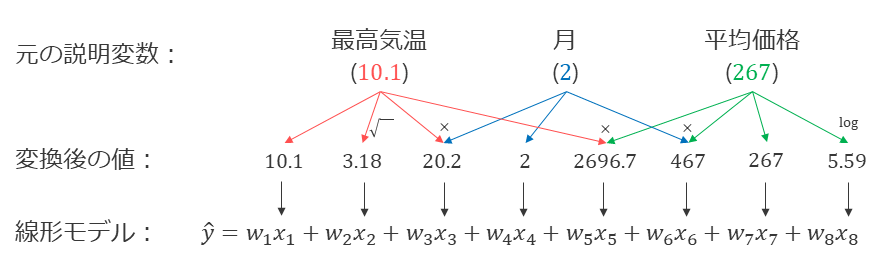
回帰分析において、説明変数を何個用意するか、それぞれの説明変数をどのように定義するかは任意である。たとえば、東京におけるアイスクリームへの支出額を予測するために、最高気温だけでなく、予測したい月の数字やアイスクリームの平均価格も有力な説明変数になり得るかもしれない。また、最高気温の平方根や、最高気温と月の積など、元の説明変数に非線形変換を適用した説明変数を導入してもよい。分析者が非線形変換の方法を明示的に設計する必要があるが、説明変数の組み合わせを考慮した非線形な回帰分析も、線形回帰の枠組みで行うことができる。
2.2. 表記法の定義#
重回帰の目的関数を一般的に記述するため、ベクトルによる表記を導入する。\(d\)個の説明変数\(x_1, x_2, \dots, x_d\)をベクトル\(\bm{x} \in \mathbb{R}^d\)でまとめて表現する。
また、\(d\)個のパラメータ(重み)\(w_1, w_2, \dots, w_d\)をベクトル\(\bm{w} \in \mathbb{R}^d\)でまとめて表現する。
すると、重回帰モデルによる目的変数の予測値\(\hat{y}\)は、ベクトル\(\bm{x}\)と\(\bm{w}\)の内積として記述できる。
単回帰のときと同様に、説明変数と目的変数の組を事例として表現する。単回帰の場合と異なるのは、説明変数がスカラー\(x\)からベクトル\(\bm{x}\)に拡張されたことである。 \(1\)番目の事例を\((\bm{x}_1, y_1)\)、\(2\)番目の事例を\((\bm{x}_2, y_2)\)、\(i\)番目の事例を\((\bm{x}_i, y_i)\)と表すことにすると、\(N\)個の事例からなるデータ\(\mathcal{D}\)は次のように表される。
さらに、\(N\)個の事例や目的変数を行列やベクトルで記述する表記法も導入しておく。説明変数のベクトル\(\bm{x}_i\)を行ベクトルとして縦に\(N\)個並べた行列\(\bm{X} \in \mathbb{R}^{N \times d}\)を定義する。この行列\(\bm{X}\)は計画行列(design matrix)と呼ばれ、それぞれの事例の\(d\)個の説明変数を水平方向に\(d\)個並べ、\(N\)個の事例を垂直方向に\(N\)個並べたものである。
ここで、\(X_{i,j}\)は行列\(\bm{X}\)の\(i\)行\(j\)列の要素を表す。
また、目的変数\(y_i\)を縦に\(N\)個並べたベクトル\(\bm{y} \in \mathbb{R}^N\)を定義する。
目的変数の予測値\(\hat{y}_i\)を縦に\(N\)個並べ、ベクトル\(\hat{\bm{y}} \in \mathbb{R}^N\)と書くことにすると、その予測値は計画行列とパラメータベクトルの積で求めることができる。
2.2.1. 単回帰を表現する#
これまでに定義した表記法で単回帰を記述できることを確認しておこう。\(d=2\)として説明変数とパラメータベクトルを以下のように定義する。
目的変数の予測値\(\hat{y}\)を計算する式を展開すると、単回帰モデルが得られる。
したがって、この章で説明する性質(例えば目的関数が凸関数であること等)は単回帰にも当てはまる。なお、冒頭のグラフの例(\(N=4\))の学習データは次のように表現される。
計画行列\(\bm{X} \in \mathbb{R}^{4 \times 2}\)と目的変数ベクトル\(\bm{y} \in \mathbb{R}^4\)は、それぞれ、
目的変数の予測ベクトル\(\hat{\bm{y}}\)は行列\(\bm{X}\)とベクトル\(\bm{w}\)の積で求めることができる。
2.3. 目的関数#
単回帰のときと同様に、ある事例の目的変数の真の値\(y_i\)と推定値\(\hat{y}_i\)の差を残差\(\epsilon_i\)とする。
学習データにおける平均二乗残差は、
重回帰モデルの学習において平均二乗残差を最小化するときは、学習データ\(\mathcal{D}\)や学習事例数\(N\)は事前に与えられる定数であり、パラメータ\(\bm{w}\)は変数である。したがって、\(N\)は最小化の解に影響を与えないので(二乗残差の平均を最小化することと二乗残差の和を最小化することは等価なので)、今後は目的関数に含めないことにする。すると、重回帰で最小化したい目的関数は、
なお、全事例に関する残差をベクトル、
で表すことにすると、
である。
以上まとめると、重回帰で最小化したい目的関数は、
重回帰の目的関数(二乗残差和)
と表現できる。
2.4. 目的関数の最小化#
目的関数\(\hat{L}_{\mathcal{D}}(\bm{w})\)を最小にするパラメータのベクトル\(\bm{w}\)を求めるため、式(2.19)をあるパラメータ\(w_j\)で偏微分する(\(j \in \{1, 2, \dots, d\}\)はパラメータのインデックスである)。
なお、最後から2番目の式変形は、計画行列\(\bm{X}\)の転置\(\bm{X}^\top\)、
の\(j\)行目の行ベクトルが\(\begin{pmatrix} X_{1,j} & X_{2,j} & \dots & X_{N,j}\end{pmatrix}\)であることを利用した。最終行の式変形では、以下の行列ベクトル積の\(j\)行目の計算結果に基づく。
式(2.20)より、\(\frac{\partial \hat{L}_{\mathcal{D}}(\bm{w})}{\partial w_j}\)は\(-2 (\bm{X}^\top \bm{\epsilon})\)の\(j\)行目の要素に対応する。全ての\(j \in \{1, 2, \dots, d\}\)について偏微分したものを\(d\)次元ベクトルとしてまとめ、\(\nabla \hat{L}_{\mathcal{D}}(\bm{w})\)と書くことにすると、
さらに、式(2.18)より\(\bm{\epsilon} = \bm{y} - \bm{X}\bm{w}\)であるから、
目的関数を最小化するパラメータベクトル\(\bm{w}\)を求めるため、これを\(\bm{0}\)とおき、\(\bm{w}\)について解くと、
したがって、学習データに対応する計画行列\(\bm{X}\)と目的変数ベクトル\(\bm{y}\)が与えられると、平均二乗残差を最小にするパラメータベクトル\(\bm{w}\)は行列演算で解析的に(閉じた式で)求めることができる。なお、\((\bm{X}^\top \bm{X})^{-1}\bm{X}^\top\)を求める部分は、ムーア・ペンローズの擬似逆行列(一般化逆行列)でも十分であるが、ここでは詳しく説明しない。
まとめとして、\(\bm{w}\)を求める式を再掲する。
重回帰のパラメータを求める式
なお、導出の途中で出てきた以下の等式は正規方程式(normal equation)と呼ばれる。
正規方程式
2.5. 目的関数の微分(別の導出)#
式(2.19)の目的関数をベクトルで記述したまま、\(\bm{w}\)で微分する導出も紹介しておく。まず、目的関数を展開する。
続いて、目的関数\(\hat{L}_{\mathcal{D}}(\bm{w})\)を最小化する\(\bm{w}\)を求めるために、\(\hat{L}_{\mathcal{D}}(\bm{w})\)を\(\bm{w}\)で偏微分する。
上式の第2項は、
第3項は、\(\bm{X}^\top \bm{X}\)が正方行列(\(d \times d\)行列)であり、\((\bm{X}^\top \bm{X})^\top=\bm{X}^\top (\bm{X}^\top)^\top = \bm{X}^\top \bm{X}\)、すなわち\(\bm{X}^\top \bm{X}\)は対称行列であることに注意すると、
ゆえに、
したがって、式(2.23)で求めた勾配と一致する。
2.6. 目的関数は凸関数#
ここで、重回帰の目的関数は凸関数であることを示しておく。証明の方針は、目的関数の二階微分(ヘッセ行列)が半正定値行列であることを示すことであるが、その方針で証明ができる背景を簡単に説明する。
2.6.1. 凸関数であるための条件#
まずは重回帰の問題設定を忘れ、凸関数に関する一般的な説明を行う。
凸関数の定義
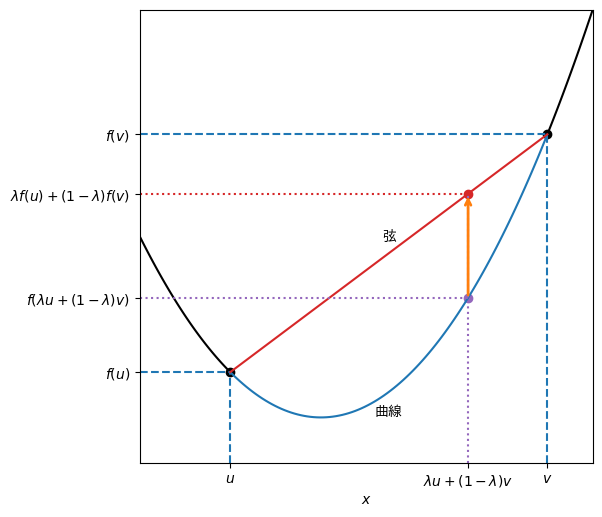
\(d\)次元ベクトル\(\bm{x} \in \mathbb{R}^{d}\)を引数にとり、スカラーを返す関数\(f: \mathbb{R}^{d} \longmapsto \mathbb{R}\)がある。任意の\(\bm{u}, \bm{v} \in \mathbb{R}^{d}\)と\(0 \leq \lambda \leq 1\)を満たす任意の\(\lambda\)に対して、
が成り立つとき、\(f\)を凸関数と呼ぶ。
この定義は「関数\(f\)上の任意の2点間の曲線は、その2点を結ぶ直線(弦)よりも下にある」ことを表現している(厳密には曲線が弦が同じでも凸関数と呼べる)。\(f\)を1変数関数として、この凸関数の定義を可視化したのが下のグラフである。点\((u, f(u)), (v, f(v))\)を結ぶ弦は、関数\(f\)の曲線よりも上に位置している。
Show code cell source
def f(x):
return 0.25 * (x - 4) ** 2 + 1
u = 2
v = 9
l = 0.25
lx = l*u + (1-l)*v
ly = l*f(u) + (1-l)*f(v)
ymax = 10
xmax = 10
fig, ax = plt.subplots(dpi=100, figsize=(6, 6))
# Plot the curve of f(x).
X = np.linspace(0, u, 100)
ax.plot(X, f(X), 'black')
X = np.linspace(u, v, 100)
ax.plot(X, f(X), 'tab:blue')
X = np.linspace(v, xmax, 100)
ax.plot(X, f(X), 'black')
ax.text((u + v) / 2, f((u + v)/2) - .3, '曲線', ha='center', va='top')
# Plot the points of u and v.
ax.scatter([u, v], [f(u), f(v)], c='black')
ax.axvline(x=u, ymin=0, ymax=f(u) / ymax, ls='--', c='tab:blue')
ax.axhline(y=f(u), xmin=0, xmax=u / xmax, ls="--", c='tab:blue')
ax.axvline(x=v, ymin=0, ymax=f(v) / ymax, ls='--', c='tab:blue')
ax.axhline(y=f(v), xmin=0, xmax=v / xmax, ls="--", c='tab:blue')
# Draw a line between u and v.
ax.plot([u, v], [f(u), f(v)], c='tab:red')
ax.text((u + v) / 2, (f(u) + f(v))/2 + .2, '弦', ha='center', va='bottom')
ax.axvline(x=lx, ymin=0, ymax=ly / ymax, ls=':', c='tab:purple')
ax.axhline(y=f(lx), xmin=0, xmax=lx / xmax, ls=":", c='tab:purple')
ax.scatter([lx], [f(lx)], c='tab:purple')
ax.annotate('', xy=(lx, ly), xytext=(lx, f(lx)), arrowprops=dict(arrowstyle='->', color='tab:orange', lw=2))
ax.axhline(y=ly, xmin=0, xmax=lx / xmax, ls=":", c='tab:red')
ax.scatter([lx], [ly], c='tab:red')
ax.set_xlabel('$x$')
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.set_xticks([u, lx, v], ['$u$', r'$\lambda u + (1 - \lambda)v$', '$v$'])
ax.set_yticks([f(u), f(lx), ly, f(v)], ['$f(u)$', r'$f(\lambda u + (1 - \lambda)v)$', r'$\lambda f(u) + (1 - \lambda)f(v)$', '$f(v)$'])
ax.set_aspect('equal')
plt.show()
一階微分と凸関数に関する定理
関数\(f: \mathbb{R}^{d} \longmapsto \mathbb{R}\)が一階微分可能であるとする。任意の\(\bm{x}, \bm{z} \in \mathbb{R}^{d}\)に対して、
が成り立つとき、\(f\)は凸関数である。
【証明】任意の\(\bm{u}, \bm{v} \in \mathbb{R}^d\)と\(0 \leq \lambda \leq 1\)を満たす任意の\(\lambda\)を用いて、\(\bm{x} = \lambda \bm{u} + (1-\lambda)\bm{v}\)と表す。式(2.33)の不等式を\(\bm{z} = \bm{u}, \bm{v}\)として適用すると、
これらの不等式に基づいて\(\lambda f(\bm{u}) + (1 - \lambda)f(\bm{v})\)を計算すると、
である(最終行の変形では\(\bm{x}\)の\(\bm{u}\)と\(\bm{v}\)による表示を代入した)。この不等式は凸関数の定義(式(2.32))そのものであり、\(f\)は凸関数であることが示された。なお、ここでは省略するが、この逆を証明して必要十分条件を示すことができる。
この定理は、「関数\(f\)上の任意の点の接線は\(f\)の曲線よりも下にある」ことを表現している(厳密には曲線が接線が同じ点で接することがある)。 \(f\)が1変数関数のとき、ある\(\bm{x}, \bm{z}\)に対してこの定理が成り立つ様子を図示した。
Show code cell source
def f(x):
return 0.15 * (x - 2) ** 2 + 1
def g(x):
return 2 * 0.15 * (x - 2)
x = 4
z = 8
ymax = 10
xmax = 10
X = np.linspace(0, xmax, 100)
fxz = f(x)+g(x) * (z - x)
fig, ax = plt.subplots(dpi=100, figsize=(6, 6))
ax.plot(X, f(X), 'black')
ax.plot([0, xmax], [f(x) - g(x) * x, f(x) + g(x) * (xmax-x)], c='tab:red')
ax.axvline(x=x, ymin=0, ymax=f(x)/ymax, ls='--', c='tab:blue')
ax.axhline(y=f(x), xmin=0, xmax=x/xmax, ls="--", c='tab:blue')
ax.axvline(x=z, ymin=0, ymax=f(x)/ymax, ls='--', c='tab:blue')
ax.axhline(y=f(z), xmin=0, xmax=z/xmax, ls="--", c='tab:blue')
ax.annotate('', xy=(z, f(x)), xytext=(z, fxz), arrowprops=dict(arrowstyle='<->', color='tab:green'))
ax.axhline(y=fxz, xmin=0, xmax=z/xmax, ls=":", c='tab:red')
ax.annotate('', xy=(x, f(x)), xytext=(z, f(x)), arrowprops=dict(arrowstyle='<->', color='tab:green'))
ax.text((x + z)/2, f(x)-0.2, '$(z-x)$', ha='center', va='top')
ax.text(z + 0.2, (fxz + f(x))/2, r"$\nabla f(x)(z-x)$", ha='left', va='center')
ax.annotate('', xy=(z, f(z)), xytext=(z, fxz), arrowprops=dict(arrowstyle='->', color='tab:orange', lw=2))
xm = x * .4 + z * 0.6
ax.text(xm, f(xm) + 0.5, '曲線', ha='center', va='bottom')
ax.text(xm, f(x) + g(x) * (xm-x) - 0.3, '接線', ha='center', va='top')
ax.set_xlabel('$x$')
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.set_xticks([x, z], ['$x$', '$z$'])
ax.set_yticks([f(x), fxz, f(z)], ['$f(x)$', r"$f(x) + \nabla f(x)(z-x)$", '$f(z)$'])
ax.set_aspect('equal')
plt.show()
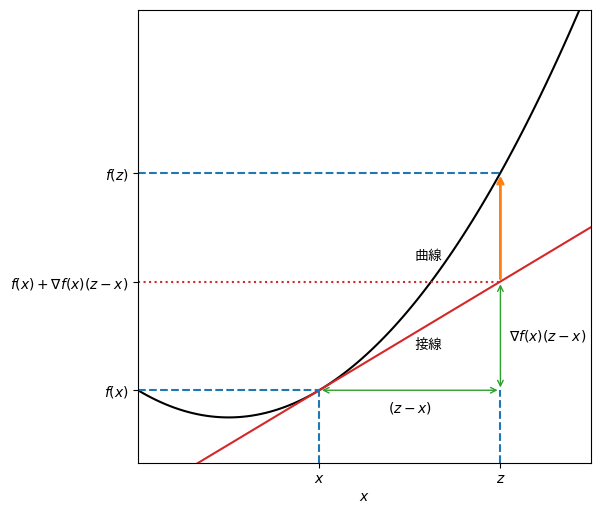
二階微分と凸関数に関する定理
関数\(f: \mathbb{R}^{d} \longmapsto \mathbb{R}\)が二階微分可能であるとする。\(f\)の二階微分であるヘッセ行列、
が半正定値行列であるとき、すなわち、任意のベクトル\(\bm{u}\)に対して、
が成り立つとき、\(f\)は凸関数である。
【証明】テイラーの定理より、任意の\(\bm{x}, \bm{z} \in \mathbb{R}^{d}\)に対して、\(0 < \lambda < 1\)を満たす\(\lambda\)が存在し、
を満たす。仮定より、\(f\)のヘッセ行列は半正定値行列であることから、上式の第3項は常に非負である(\(\bm{u} = \bm{z} - \bm{x}\)とおけばよい)。ゆえに、
であり、一階微分と凸関数に関する定理(式(2.33))から、\(f\)は凸関数であることが示された。なお、ここでは省略するが、この逆を証明して必要十分条件を示すことができる。
\(f\)が1変数関数のとき、式(2.34)の条件は\(f''(x) \geq 0\)となる。これは、\(f\)の傾きが単調増加する(厳密には減少しない)ことを表している。
2.6.2. 目的関数が凸関数であることの証明#
さて、ヘッセ行列の半正定値性から凸関数であることを示せることが分かったので、変数を\(\bm{x} \to \bm{w}\)に、目的関数を\(f(\bm{x}) \to \hat{L}_{\mathcal{D}}(\bm{w})\)に置換して考察する。式(2.23)より、目的関数の一階微分は、
さらに、目的関数の二階微分(ヘッセ行列)は、
ここで、任意のベクトル\(\bm{u} \in \mathbb{R}^d\)に対して、
であるから、目的関数の二階微分\(2 \bm{X}^\top \bm{X}\)は半正定値行列である。ゆえに、重回帰の目的関数は凸関数である。
なお、凸関数の定義を用いて重回帰の目的関数が凸であることを証明する方法もあるが、ここでは省略する。
2.7. 重回帰の性質#
重回帰に関する様々な性質を導出してみよう [Beck, 2009]。重回帰で推定されたパラメータ\(\bm{w}\)は、式(2.23)を\(\bm{0}\)とおいたものであるので、
この行列・ベクトルの成分を明示すると、
ゆえに、任意の整数\(j \in \{1, 2, \dots, d\}\)に関して、
これは、\(\bm{w}\)を求めるときに、式(2.20)の2行目を全ての\(j\)に対して\(0\)としたことからも、明らかである。
ここで、バイアス項(切片)に対応するパラメータを持たせるため、\(\bm{X}\)の先頭列の要素はすべて\(1\)と仮定する。
念のため、\(\bm{X}\)と\(\bm{X}^\top\)を明示的に書くと、
これにより、\(w_1\)がバイアス項に対応するパラメータとなる。ここから、重回帰の様々な性質を導出してみよう。なお、バイアス項に対応させる列は先頭である必要はなく、その他の場所でも以降の議論の一般性は失われない。
2.7.1. 残差の和および平均は\(0\)#
\(j=1\)として式(2.40)に式(2.41)を代入すると、
ゆえに、残差の和および平均は\(0\)である。
2.7.2. 目的変数の推定値\(\hat{y}\)の平均値は観測値\(y\)の平均に等しい#
残差の定義\(\bm{\epsilon} = \bm{y} - \hat{\bm{y}}\)を明示的に書くと、
両辺の各要素の和をとると、
ここで、式(2.43)より左辺は\(0\)であるから、
ゆえに、目的変数の推定値\(\hat{y}\)の平均値は観測値\(y\)の平均に等しい。
2.7.3. 観測データの重心は回帰平面上に存在する#
説明変数の平均ベクトル\(\overline{\bm{x}}\)、
に対して、目的変数の推定値を計算すると、
目的変数の平均\(\overline{y}\)が得られる。ゆえに、観測データの重心は回帰平面上に存在する。
2.7.4. 各説明変数と残差には相関がない#
\(j\)番目の説明変数\(\bm{X}_{:,j}\)を確率変数と見なし、\(\mathcal{X}_j\)と書くことにする。 任意の説明変数\(\mathcal{X}_j\)と残差\(\mathcal{E}\)の共分散を計算する。残差の平均は\(\overline{\epsilon}=0\)であること、式(2.40)と式(2.43)を利用すると、
2.7.5. 目的変数の推定値と残差には相関がない#
目的変数の推定値\(\hat{\mathcal{Y}}\)と残差\(\mathcal{E}\)の共分散を計算する。残差の平均は\(\overline{\epsilon}=0\)であること、式(2.38)と式(2.43)を利用すると、
であるから、\(\mathrm{Cov}[\hat{\mathcal{Y}},\mathcal{E}] = 0\)が言える。すなわち、目的変数の推定値と残差の共分散が0になることから、目的変数の推定値と残差は無相関(無関係)であることが分かる。
2.8. 決定係数#
目的変数の観測値の分散\(\mathrm{Var}[\mathcal{Y}]\)は目的変数の推定値の分散\(\mathrm{Var}[\hat{\mathcal{Y}}]\)と残差の分散\(\mathrm{Var}[\mathcal{E}]\)の和で表されることを示す。
なお、以上の式変形における最後から2行目において、第2項は式(2.50)の導出結果、第3項は式(2.43)より\(0\)であることを利用した。
したがって、単回帰のときと同様に、
全変動: 目的変数の観測値の分散\(\mathrm{Var}[\mathcal{Y}]\)(データの変動)
回帰変動: 目的変数の推定値の分散\(\mathrm{Var}[\hat{\mathcal{Y}}]\)(モデルの変動)
残差変動: 残差の分散\(\mathrm{Var}[\mathcal{E}]\)(モデルが説明しきれなかった変動)
すると、先ほどの式は「全変動は回帰変動と残差変動の和で表される」という関係を表している。
データの全変動のうち、回帰によって表現できた回帰変動の割合を決定係数とよび、次式で定義する。
決定係数
決定係数は\([0,1]\)の範囲の値ととり、データがモデル(単回帰の場合は直線)によく当てはまるときは\(1\)に近くなる。
2.9. 重回帰の実施例#
冒頭の最高気温とアイスクリーム・シャーベットの支出額のデータに対して、単回帰を行う例を示す。まず、説明変数(最高気温)をX、目的変数(支出額)をYに格納する。
def plot_graph(X, Y, x, y):
fig, ax = plt.subplots(dpi=100)
ax.set_title('最高気温とアイスクリーム・シャーベットの支出額')
ax.set_xlabel('最高気温の月平均(℃)')
ax.set_ylabel('支出額(円)')
ax.set_xlim(0, 35)
ax.set_ylim(-250, 2000)
ax.grid()
ax.scatter(X, Y, marker='.')
ax.plot(x, y, 'r')
X = np.array([
9.1, 11.2, 12.3, 18.9, 22.2, 26. , 30.9, 31.2, 28.8, 23. , 18.3,
11.1, 8.3, 9.1, 12.5, 18.5, 23.6, 24.8, 30.1, 33.1, 29.8, 23. ,
16.3, 11.2, 9.6, 10.3, 16.4, 19.2, 24.1, 26.5, 31.4, 33.2, 28.8,
23. , 17.4, 12.1, 10.6, 9.8, 14.5, 19.6, 24.7, 26.9, 30.5, 31.2,
26.9, 23. , 17.4, 11. , 10.4, 10.4, 15.5, 19.3, 26.4, 26.4, 30.1,
30.5, 26.4, 22.7, 17.8, 13.4, 10.6, 12.2, 14.9, 20.3, 25.2, 26.3,
29.7, 31.6, 27.7, 22.6, 15.5, 13.8, 10.8, 12.1, 13.4, 19.9, 25.1,
26.4, 31.8, 30.4, 26.8, 20.1, 16.6, 11.1, 9.4, 10.1, 16.9, 22.1,
24.6, 26.6, 32.7, 32.5, 26.6, 23. , 17.7, 12.1, 10.3, 11.6, 15.4,
19. , 25.3, 25.8, 27.5, 32.8, 29.4, 23.3, 17.7, 12.6, 11.1, 13.3,
16. , 18.2, 24. , 27.5, 27.7, 34.1, 28.1, 21.4, 18.6, 12.3])
Y = np.array([
463., 360., 380., 584., 763., 886., 1168., 1325., 847.,
542., 441., 499., 363., 327., 414., 545., 726., 847.,
1122., 1355., 916., 571., 377., 465., 377., 362., 518.,
683., 838., 1012., 1267., 1464., 1000., 629., 448., 466.,
404., 343., 493., 575., 921., 1019., 1149., 1303., 805.,
739., 587., 561., 486., 470., 564., 609., 899., 946.,
1295., 1325., 760., 667., 564., 633., 478., 450., 567.,
611., 947., 962., 1309., 1307., 930., 668., 496., 650.,
506., 423., 531., 672., 871., 986., 1368., 1319., 924.,
716., 651., 708., 609., 535., 717., 890., 1054., 1077.,
1425., 1378., 900., 725., 554., 542., 561., 459., 604.,
745., 1105., 973., 1263., 1533., 1044., 821., 621., 601.,
549., 572., 711., 819., 1141., 1350., 1285., 1643., 1133.,
784., 682., 587.])
2.9.1. numpy.polynomialを用いる例#
numpy.polynomialを用いると、線形回帰モデルのパラメータを求めることができる。多項式近似の次元数を3番目の引数に指定する。以下は2次関数にフィッティングする例である。
from numpy.polynomial import Polynomial
W = Polynomial.fit(X, Y, 2)
W.convert()
多項式近似の係数を\(0\)次、\(1\)次、…の順で並べて表示する。
W.convert().coef
array([635.74825774, -33.14302425, 1.73160796])
\(0\)から\(35\)までに等間隔に配置した\(100\)個の数値xに対して、目的変数の推定値y_hatを求め、回帰曲線を描画する。
x = np.linspace(0, 35, 100)
y_hat = W(x)
plot_graph(X, Y, x, y_hat)
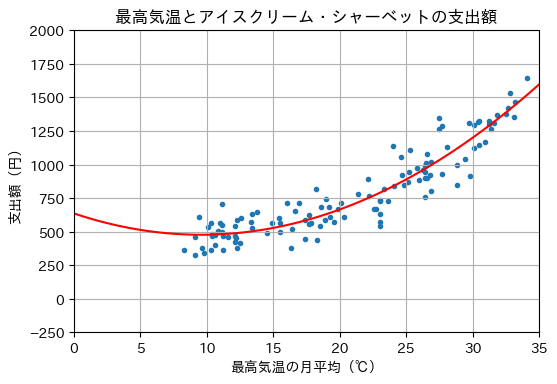
続いて、3次関数にフィッティングしてみる。
W = Polynomial.fit(X, Y, 3)
W.convert().coef
array([ 2.64628814e+02, 2.92887138e+01, -1.44685888e+00, 5.01164586e-02])
x = np.linspace(0, 35, 100)
y_hat = W(x)
plot_graph(X, Y, x, y_hat)
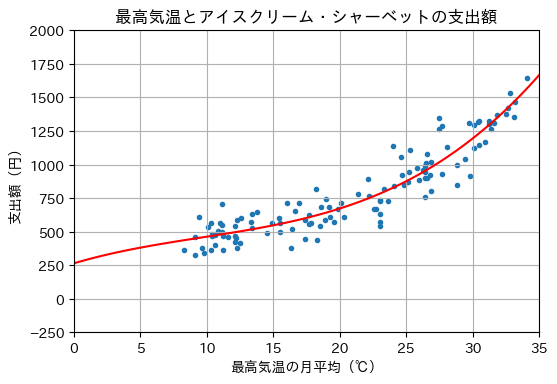
さらに、4次関数にフィッティングした結果を示す。
W = Polynomial.fit(X, Y, 4)
W.convert().coef
array([-3.47044444e+02, 1.67566320e+02, -1.23937689e+01, 4.12591380e-01,
-4.27358629e-03])
x = np.linspace(0, 35, 100)
y_hat = W(x)
plot_graph(X, Y, x, y_hat)
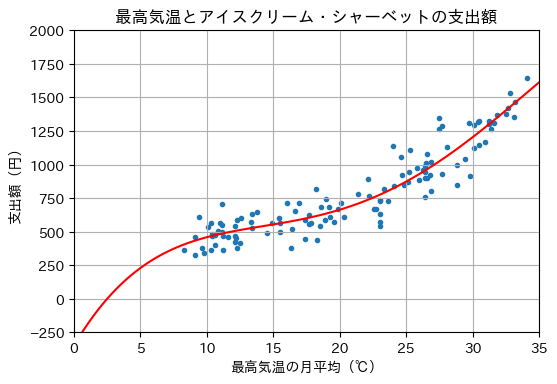
2.9.2. sklearn.linear_model.LinearRegressionを用いる例#
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import make_pipeline
sklearn.linear_model.LinearRegressionクラスを用いても、線形回帰を容易に実行できる。訓練データにフィッティングさせるには、fit関数を呼び出せばよいが、説明変数のデータとして、事例数を行数、目的変数の数を列数とした行列形式で与えることになっているので、Xの形状を変更する。以下に、3次関数にフィッティングする例を示す。
reg = make_pipeline(PolynomialFeatures(3), LinearRegression())
reg.fit(X.reshape(-1, 1), Y)
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(degree=3)),
('linearregression', LinearRegression())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('polynomialfeatures', PolynomialFeatures(degree=3)),
('linearregression', LinearRegression())])PolynomialFeatures(degree=3)
LinearRegression()
回帰直線の係数(傾き)を表示する。
reg[1].coef_
array([ 0. , 29.28871381, -1.44685888, 0.05011646])
回帰直線の切片を表示する。
reg[1].intercept_
264.628814101544
決定係数を求めるため、score関数を呼び出す。
reg.score(X.reshape(-1, 1), Y)
0.8784609747360882
\(0\)から\(35\)までに等間隔に配置した\(100\)個の数値xに対して、目的変数の推定値y_hatを求めるため、predict関数を呼び出し、回帰曲線を描画する。
x = np.linspace(0, 35, 100)
y_hat = reg.predict(x.reshape(-1, 1))
plot_graph(X, Y, x, y_hat)
2.10. 確認問題#
データ\(\mathcal{D}_s\)に対して多項式のフィッティングを行いたい。以下の処理を行うプログラムを作成せよ。
D = np.array([[1, 3], [3, 6], [6, 5], [8, 7]])
なお、NumPy, SciPy, scikit-learn, statsmodel等のライブラリには回帰分析を行う便利な関数として以下のようなものがあるが、ここでは使わずに講義中で説明した式をプログラムとして表現すること。
(1) 行列による1次関数のパラメータ推定
\(y = w_0 + w_1 x\)とおき、学習データ\(\mathcal{D}_s\)上の平均二乗残差を最小にする\(\bm{w} = \begin{pmatrix} w_0 \\ w_1 \end{pmatrix}\)を行列演算により求めよ。
(2) 2次関数による重回帰
\(y = w_0 + w_1 x + w_2 x^2\)とおき、重回帰により平均二乗残差を最小にする\(\bm{w} = \begin{pmatrix} w_0 \\ w_1 \\ w_2 \end{pmatrix}\)を求めよ。
(3) 回帰曲線の描画
回帰で求めた2次関数をデータ点とともにグラフに描け。
(4) 決定係数
回帰で得られた2次関数の決定係数(\(R^2\))を求めよ。
(5) 3次関数による重回帰
\(y = w_0 + w_1 x + w_2 x^2 + w_3 x^3\)とおき、重回帰により平均二乗残差を最小にする\(\bm{w} = \begin{pmatrix} w_0 \\ w_1 \\ w_2 \\ w_3 \end{pmatrix}\)を求めよ。
(6) 回帰曲線の描画
回帰で求めた3次関数をデータ点とともにグラフに描け
(7) 決定係数
回帰で求めた3次関数の決定係数(\(R^2\))を求めよ