12. 主成分分析 (1)#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.animation
from IPython.display import HTML
\(\def\bm{\boldsymbol}\)以下は、教育用標準データセット(SSDSE: Standardized Statistical Data Set for Education)の「C. 都道府県庁所在市別、家計消費データ」から麺類に関する部分を抜き出したものである(多いので冒頭の15行だけを表示した)。SSDSE-Cは、総務省統計局「家計調査」から、二人以上の世帯の1世帯当たりの年間支出金額を都道府県庁所在市別・品目別に表形式で収録したものである。
Show code cell source
df = pd.read_excel('https://www.nstac.go.jp/SSDSE/data/2021/SSDSE-C-2021.xlsx', skiprows=1)
df = df[['都道府県', '生うどん・そば', "乾うどん・そば", "パスタ", "中華麺", "カップ麺", "即席麺", "他の麺類"]]
df = df.iloc[1:]
df[:15]
| 都道府県 | 生うどん・そば | 乾うどん・そば | パスタ | 中華麺 | カップ麺 | 即席麺 | 他の麺類 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 北海道 | 3162 | 2082 | 1266 | 4152 | 5189 | 1609 | 726 |
| 2 | 青森県 | 2964 | 2224 | 1114 | 5271 | 6088 | 2039 | 554 |
| 3 | 岩手県 | 3349 | 2475 | 1305 | 5991 | 5985 | 1889 | 898 |
| 4 | 宮城県 | 3068 | 2407 | 1339 | 5017 | 5295 | 1709 | 842 |
| 5 | 秋田県 | 3231 | 3409 | 1019 | 5172 | 5013 | 1680 | 554 |
| 6 | 山形県 | 4478 | 3084 | 1288 | 5236 | 5875 | 1745 | 754 |
| 7 | 福島県 | 2963 | 2705 | 1064 | 4397 | 5862 | 1687 | 919 |
| 8 | 茨城県 | 3353 | 2477 | 1248 | 4034 | 4562 | 1440 | 653 |
| 9 | 栃木県 | 3908 | 2218 | 1391 | 4534 | 4945 | 1860 | 742 |
| 10 | 群馬県 | 4563 | 1948 | 1203 | 4153 | 5049 | 1544 | 546 |
| 11 | 埼玉県 | 4016 | 2256 | 1487 | 4512 | 4584 | 1568 | 949 |
| 12 | 千葉県 | 3389 | 2277 | 1441 | 4582 | 4513 | 1840 | 835 |
| 13 | 東京都 | 3088 | 2385 | 1595 | 4592 | 3953 | 1734 | 974 |
| 14 | 神奈川県 | 3410 | 2684 | 1472 | 4484 | 4035 | 1741 | 1049 |
| 15 | 新潟県 | 2697 | 3409 | 1308 | 4192 | 6095 | 2201 | 612 |
このデータを分析することで、日本における麺類の消費行動の全体的な傾向や、地域における特徴が明らかになるかもしれない。また、カップ麺と即席麺は消費行動が似ているかもしれないのでどちらか一方だけ調査すれば十分である、ということがデータから明らかになるかもしれない。
そこで、麺類の消費行動の傾向を掴むために、このデータを可視化することを考える。仮に、このデータが2次元(2種類の麺類によるデータ)であるならば、2次元平面上に各都道府県庁所在地をプロットすればよい。ところが、このデータは各都道府県庁所在地が7次元のベクトルで表されているため、2次元平面上にプロットすることができない。そこで、このデータの特徴空間を7次元から2次元に圧縮することを考えたい。
本章では、このような分析に役立つ手法として、主成分分析(principal component analysis)を紹介する。主成分分析は、データの情報をできるだけ豊富に表現できるように配慮しながら、もとの特徴量の線形結合で表現される新しい「軸」を導き出す手法である。元データの情報量を最も豊富に表現できる軸は第1主成分(first principal component)と呼ばれる。その第1主成分と直交し、かつ2番目に情報量が豊富な軸を第2主成分、第1主成分と第2主成分に直交し、かつ3番目に情報量が豊富な軸を第3主成分、・・・という形で、元データを表現する情報量の多い順にお互いに直交する複数の軸を求めることができる。
元のデータの各事例は、主成分分析で求められた新しい軸に射影される。主成分分析で求められた全ての軸を用いることで、元のデータを完全に再現することができる。また、元データを第1主成分、第2主成分といった主要な軸だけで表現することで、元データよりも少ない軸に要約することができる。このため、主成分分析はデータの次元圧縮やノイズ除去、可視化等に用いられる。
12.1. 2次元データの例#
いきなり3次元以上のデータで考えるのは難しいので、まずは2次元のデータの場合を考える。簡単な例として、以下のグラフで示されたデータ\(\mathcal{D}_s\)を考える。このデータは\(xy\)平面上の\(4\)点\((-7,-2),(-3,-3),(4,1),(6,4)\)で構成されている。
Show code cell source
D = np.array([[-7, -2], [-3, -3], [4, 1], [6, 4]])
C = ['red', 'blue', 'green', 'orange']
fig = plt.figure(dpi=100, figsize=(6, 6))
ax = fig.add_subplot(1,1,1)
ax.scatter(D[:,0], D[:,1], marker='o', color=C)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_aspect('equal')
ax.set_xlim(-8, 8)
ax.set_ylim(-8, 8)
ax.grid()
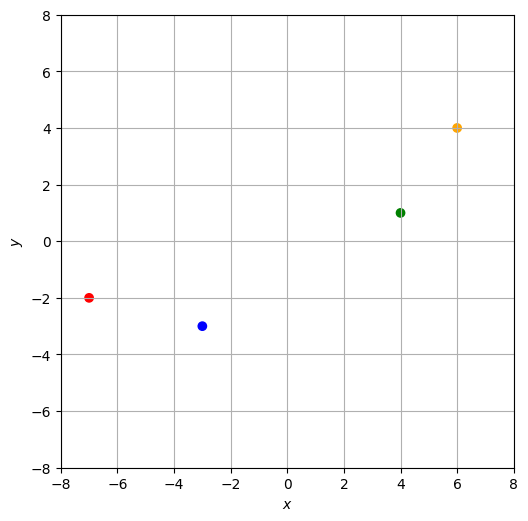
このデータ\(\mathcal{D}_s\)を次のように表すことにする(\(i \in \{1, 2, 3, 4\}\)は事例に対するインデックスである)。
なお、
であるから、この4点の重心は原点\((0,0)\)である(データの重心が原点にない場合の取り扱いは次章で説明する)。
12.2. データ点を直線へ射影#
さて、各点\((x_i, y_i) \in \mathbb{R}^2\)を\(xy\)平面上で原点を通る直線に射影し、その直線上の点\((\hat{x}_i, \hat{y}_i)\)で近似的に表現したい。原点を通る直線は、長さ\(1\)の方向ベクトル\(\bm{u} \in \mathbb{R}^2\)と媒介変数\(a \in \mathbb{R}\)を用いて、\(a \bm{u}\)で表される。したがって、点\((x_i, y_i)\)を射影した点\((\hat{x}_i, \hat{y}_i)\)は、\(a_i \in \mathbb{R}\)を用いて次式で表される。
なお、\(|a_i|\)は射影された点\((\hat{x}_i, \hat{y}_i)\)の原点からの距離を表す。射影された点が方向ベクトルと同じ向きにあるときは\(a_i\)は正の値、反対の向きにあるときは\(a_i\)は負の値をとることとし、\(a_i\)を直線上の位置と呼ぶ。以上の定式化により、元のデータ点\((x_i, y_i)\)は\(\bm{u}\)が定める(1次元の)数直線上の位置\(a_i\)として近似的に表現される。
例えば、直線\(y=\frac{1}{2}x\)を考えると、元のデータ点(丸印)は射影された点(データ点から降ろした垂線の足、四角印)で近似的に表現される。
Show code cell source
def draw_projections(ax, q, fill=False, show_a = False, show_e = False, show_xy=False):
artist = []
ya = ['bottom', 'top', 'top', 'bottom']
yoffs = np.array([0.2, -0.2, -0.2, 0.2])
axoffs = np.array([-0.2, -0.3, -0.4, -0.2])
ayoffs = np.array([-0.7, 0.5, 0.5, -0.7])
exoffs = np.array([-0.8, -0.3, 0.3, -0.1])
eyoffs = np.array([0.35, -0.8, -0.4, 0.35])
P = []
for i in range(D.shape[0]):
x, y = D[i,0], D[i,1]
# Project (x, y) onto the line q.
d = np.dot(np.array([x, y]), q)
p = d * q
artist.append(ax.scatter(p[0], p[1], marker='s', color=C[i]))
if show_a:
artist.append(ax.text(p[0] + axoffs[i], p[1] + ayoffs[i], '$a_{}$'.format(i+1)))
if show_e:
artist.append(ax.text(p[0] + exoffs[i], p[1] + eyoffs[i], '$\epsilon_{}$'.format(i+1)))
if show_xy:
artist.append(ax.text(x, y + yoffs[i], '$(x_{0}, y_{0})$'.format(i+1), ha='center', va=ya[i]))
artist += ax.plot([x, p[0]], [y, p[1]], ls='--', color=C[i])
P.append((i, p))
# Sort the projected points so that we can draw lines in an appropriate order.
P.sort(key=lambda x: np.dot(x[1], x[1]), reverse=True)
for i, p in P:
artist += ax.plot([0, p[0]], [0, p[1]], ls='-', color=C[i])
if fill:
tri = plt.Polygon(((0, 0), D[i], p), fc=C[i], alpha=0.2)
artist.append(ax.add_patch(tri))
return artist
u = np.array([2, 1])
uy = 8 * u[1] / u[0]
fig = plt.figure(dpi=100, figsize=(6, 6))
ax = fig.add_subplot(1,1,1)
ax.scatter(D[:,0], D[:,1], marker='o', color=C)
ax.plot([-8, 8], [-uy, uy], ls='-', color='black', lw=1)
draw_projections(ax, u / np.linalg.norm(u), show_a=True, show_xy=True)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_aspect('equal')
ax.set_xlim(-8, 8)
ax.set_ylim(-8, 8)
ax.grid()
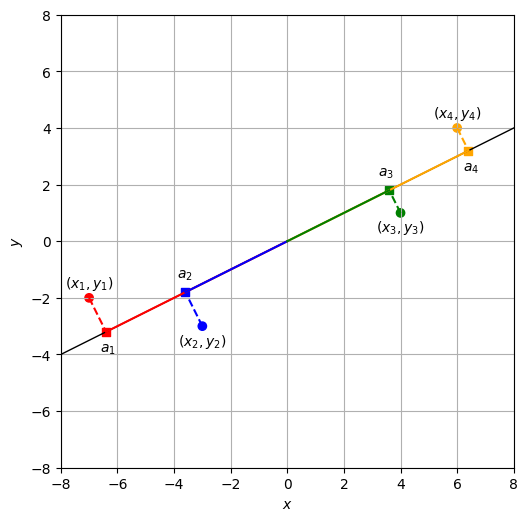
\(a_i\)を求めるため、直線\(y=\frac{1}{2}x\)に対応する長さ\(1\)の方向ベクトル\(\bm{u}\)を求める。
ある点\((x_i, y_i)\)を方向ベクトル\(\bm{u}\)上に射影したとき、その位置\(a_i\)は、
と求めることができる。ここで、\(\theta\)は位置ベクトル\((x_i, y_i)\)と方向ベクトル\(\bm{u}\)のなす角である。ゆえに、
以上により、データ\(\mathcal{D}_s\)の各事例\((x_i, y_i)\)を方向ベクトル\(\bm{u}\)と、位置\(a_i\)で近似的に表現したことになる。各事例\((x_i, y_i)\)を射影した点\((\hat{x}_i, \hat{y}_i)\)は、
12.3. 近似の良さの定量化#
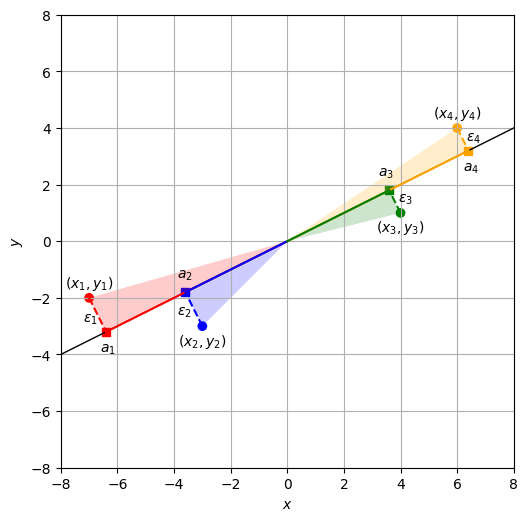
直線への射影による近似の良さを定量化するため、元データの各点\((x_i, y_i)\)から直線上に垂線を降ろしたときの長さを\(\epsilon_i\)とし、これを残差と呼ぶ。三平方の定理(ピタゴラスの定理)より、
が成り立つ。以下のグラフでは、各事例に関して直角三角形を色付けして描いている。直線\(y=\frac{1}{2}x\)上の面を底辺、垂線を高さとすると、
\(x_i^2 + y_i^2\): 斜面の長さの二乗(原点から丸印までの距離の二乗)
\(a_i^2\): 底辺の長さの二乗(原点から四角印までの距離の二乗)
\(\epsilon_i^2\): 高さ(点線)の二乗(残差の二乗)
と整理できる。
Show code cell source
u = np.array([2, 1])
uy = 8 * u[1] / u[0]
fig = plt.figure(dpi=100, figsize=(6, 6))
ax = fig.add_subplot(1,1,1)
ax.scatter(D[:,0], D[:,1], marker='o', color=C)
ax.plot([-8, 8], [-uy, uy], ls='-', color='black', lw=1)
draw_projections(ax, u / np.linalg.norm(u), True, show_a=True, show_e=True, show_xy=True)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_aspect('equal')
ax.set_xlim(-8, 8)
ax.set_ylim(-8, 8)
ax.grid()
これまでの議論では、データ点を射影する直線(方向ベクトル\(\bm{u}\))を固定していたが、以降は射影された点の良さを考慮しながら様々な直線を検討したい。今回のデータ\(\mathcal{D}_s\)の重心は原点であるため、直線の切片は\(0\)に固定し、直線の傾きだけを変更する。回帰分析と同様に、方向ベクトル\(\bm{u}\)で元のデータ点を射影したときの「良さ」を、全てのデータ点の残差の二乗和で定量化する。
なお、2次元のデータにおいて、線形回帰では\(y\)軸に関する実際の値と近似値の値の差\(\epsilon = y - \hat{y}\)を残差として定義したのに対し、主成分分析では事例を直線に射影したときの垂線の長さ\(\epsilon = \sqrt{(x - \hat{x})^2 + (y - \hat{y})^2}\)を残差として定義する所が異なる。
さて、直線の傾きを変えながら射影された点をプロットするアニメーションを示す。
Show code cell source
K = 50
X = np.hstack([np.linspace(-8, 8, K, endpoint=False), np.full(K-1, 8)])
Y = np.hstack([np.full(K-1, -8), np.linspace(-8, 8, K, endpoint=False)])
fig = plt.figure(dpi=100, figsize=(6, 6))
ax = fig.add_subplot(1,1,1)
ax.scatter(D[:,0], D[:,1], marker='o', color=C)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_aspect('equal')
ax.set_xlim(-8, 8)
ax.set_ylim(-8, 8)
ax.grid()
artists = []
for x, y in zip(X, Y):
q = np.array([-x, -y]) - np.array([x, y])
artist = []
artist += ax.plot([x, -x], [y, -y], ls='-', color='black', lw=1)
artist += draw_projections(ax, q / np.linalg.norm(q), True)
artists.append(artist)
ani = matplotlib.animation.ArtistAnimation(fig, artists, interval=100)
#ani.save('pca.mp4', writer="ffmpeg")
html = ani.to_jshtml()
plt.close(fig)
HTML(html)
このアニメーションを注意深く観察すると、残差の二乗和が小さくなる、すなわち各三角形の高さ\(\epsilon_i\)が短くなるとき、各三角形の底辺の長さ\(a_i\)が大きくなり、三角形が直線方向に大きく広がることが分かる。各点について三平方の定理を適用すると、
この4つの式の両辺を足すと、
左辺の\(\left(a_1^2 + a_2^2 + a_3^2 + a_4^2\right)\)は「直線に射影した各点の原点からの距離の二乗和」、\(\left(\epsilon_1^2 + \epsilon_2^2 + \epsilon_3^2 + \epsilon_4^2\right)\)は「直線に射影した各点の残差の二乗和」である。右辺はデータが与えられると直線の傾きに依らず計算できる定数であり、今回のデータ\(\mathcal{D}_s\)では\(140\)である。
一般に、以下の関係が成り立つ。
ゆえに、残差の二乗和を最小にする方向ベクトル\(\bm{u}^*\)を求めることは、\(a_i\)の二乗和を最大にする単位ベクトル\(\bm{u}^*\)を求めることと等価である。
ところで、元のデータの重心が原点にあるとき、\(a_i\)の和も\(0\)になる。
これは、\(a_i\)の平均\(\bar{a}\)が\(0\)であることを意味する。すると、
であるから、
したがって、データ点を直線に射影し、近似的に表現するとき、その残差の二乗和を最小化するようにベクトル\(\bm{u}\)を選ぶことと、射影された点の分散を最大化するようにベクトル\(\bm{u}\)を選ぶことは等価である。後者は射影された点の分散を大きくとることで、元のデータ点の情報をできるだけ保存しようとしていると解釈できる。主成分分析は「元データを写像したときの分散が大きくなるような軸を見つける」と説明されることがあるが、これは「元データの情報をできるだけ豊富に表現できるような軸を見つける」や「元データを射影したときの残差ができるだけ小さくなるような軸を見つける」という動機に基づいている。
12.4. 第1主成分を求める#
これまでの議論により、データ\(\mathcal{D}_s\)を「よく」射影するベクトル\(\bm{u}\)を求めることは、\(\|\bm{u}\|=1\)の制約下で、以下の目的関数\(J\)を最大化する問題に帰着した。
ここで、\(\bm{a} = \begin{pmatrix}a_1 & a_2 & a_3 & a_4\end{pmatrix}^\top\)と表すことにすると、
そこで、式(12.5)の\(\bm{a}\)の定義に立ち返って整理してみる。
なお、行列\(\bm{X} = \mathbb{R}^{4 \times 2}\)はデータ点(事例)のベクトルを並べたものである。
すると、目的関数\(J\)は、
と整理できる。\(\bm{S} = \bm{X}^\top \bm{X}\)は対称行列である。
\(\bm{u}\)を求めることは、制約\(\|\bm{u}\|=1\)のもとで目的関数\(J\)を最大化する問題であるので、ラグランジュの未定乗数法で制約なしの問題に書き換える。すると、\(\lambda\)をラグランジュ乗数として、以下のラグランジュ関数\(\mathcal{L}(\bm{u}, \lambda)\)を最大化する問題に帰着する。
ラグランジュ関数\(\mathcal{L}(\bm{u}, \lambda)\)を\(\bm{u}\)で偏微分すると、
これを\(0\)とおくと、
ゆえに、\(\bm{S} = \bm{X}^\top \bm{X}\)の固有値問題に帰着した。\(\lambda\)が\(\bm{S}\)の固有値であるので、特性方程式は、
さて、データ\(\mathcal{D}_s\)の例で実際に計算を進める。
であるから、特性方程式は、
\(J\)を最大化する解として、\(\lambda \approx 134.8\)と\(\lambda \approx 5.185\)のどちらを選べばよいのか? \(\bm{S} \bm{u} = \lambda\bm{u}\)の両辺に左から\(\bm{u}^\top\)をかけると、左辺は目的関数\(J\)に一致する。右辺は\(\|\bm{u}\|=1\)であることに注意すると、
したがって、求めた固有値\(\lambda\)が目的関数の値となる。そこで、固有値のうち大きい方を\(\lambda_1\)と書くことにして、\(\lambda_1 = 134.8\)とする。\(\bm{S}\)の固有値問題の等式に\(\lambda = 134.8\)を代入すると、
であるから、
したがって、\(c\)をスカラー値の定数として、
と表される。さらに制約\(\|\bm{u}\|=1\)を満たすように\(\bm{u}\)を求めると、
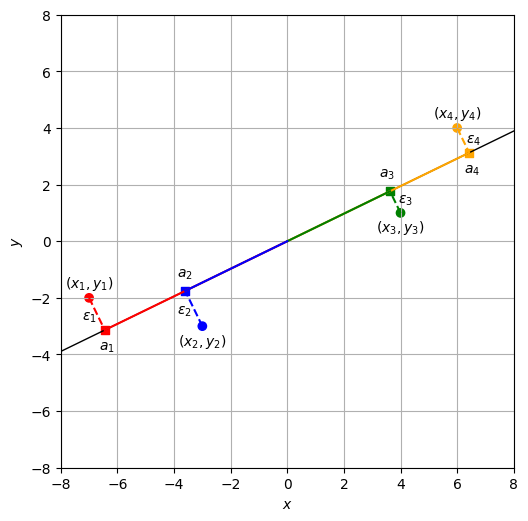
このように求めた\(\bm{u}\)を第1主成分(the first principal component)と呼ぶ。\(\lambda_1\)は目的関数の値そのものであるから、データを第1主成分の軸に写像したときの分散は\(\lambda_1 = 134.8\)である。各データ点\((x_i, y_i)\)を第1主成分の直線上に写像したときの位置\(a_i\)を第1主成分得点(the first principal component score)と呼ぶ。式(12.19)を用いて実際に主成分得点を求めてみると、
実際に求めた\(\bm{u}\)を可視化した(おおよそ、これまで例に用いていた\(y=\frac{1}{2}x\)に近いが、それよりも少しずれた直線が解であった)。
Show code cell source
u = np.array([0.89920519, 0.43752718])
uy = 8 * u[1] / u[0]
fig = plt.figure(dpi=100, figsize=(6, 6))
ax = fig.add_subplot(1,1,1)
ax.scatter(D[:,0], D[:,1], marker='o', color=C)
ax.plot([-8, 8], [-uy, uy], ls='-', color='black', lw=1)
draw_projections(ax, u / np.linalg.norm(u), show_a=True, show_e=True, show_xy=True)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_aspect('equal')
ax.set_xlim(-8, 8)
ax.set_ylim(-8, 8)
ax.grid()
12.5. 第2主成分を求める#
先ほど求めた第1主成分の軸は元データを近似的によく表現しているが、残差\(\epsilon_i\)が残っている。残差は各データ点から第1主成分の直線に降ろした垂線の長さであるから、この残差を表現するには第1主成分のベクトルと直交するベクトルを求めればよい。すなわち、残差を表現する直線の方向ベクトルを\(\bm{v}\)とおき、\(\|\bm{v}\|=1\)かつ\(\bm{u}^\top\bm{v}=0\)を満たすベクトル\(\bm{v}\)を求めればよい。\(u_1 v_1 + u_2 v_2 = 0\)であるから、
と求めることができる。この\(\bm{v}\)が第2主成分(the second principal component)である。例として用いている\(\mathcal{D}_s\)は2次元のデータであるので、第3成分以降の軸を求める必要はない。
ただ、この求め方では2次元以上のデータに対応できないので、目的関数\(J\)を最大化しても\(\bm{v}\)が求まることを説明する。データ\(\mathcal{D}_s\)を2番目に「よく」射影するベクトル\(\bm{v}\)を求めることは、\(\|\bm{v}\|=1\)および\(\bm{u}^\top \bm{v}=0\)の制約下で、以下の目的関数\(J\)を最大化すればよい。
これは、以下のラグランジュ関数\(\mathcal{L}(\bm{v}, \lambda, \alpha)\)を最大化する問題に帰着する。
ただし、\(\lambda\)と\(\alpha\)はラグランジュ乗数である。ラグランジュ関数\(\mathcal{L}(\bm{v}, \lambda, \alpha)\)を\(\bm{v}\)で偏微分すると、
これを\(0\)とおくと、
ここで、左から\(\bm{u}^\top\)をかけ、\(\bm{u}^\top\bm{v}=0\)と\(\bm{u}^\top\bm{u}=1\)であることに注意すると、
なお、最終行の式変形では、\(\bm{u}^\top\bm{S} \bm{v}\)がスカラーであるから、\((\bm{u}^\top\bm{S} \bm{v})^\top = \bm{v}^\top\bm{S} \bm{u}\)が成り立つことを用いた。ここで、第1主成分を求めたときの固有値問題により、\(\bm{S} \bm{u} = \lambda_1 \bm{u}\)であるから、
したがって、\(\alpha = 0\)であるから、ラグランジュ関数\(\mathcal{L}(\bm{v}, \lambda, \alpha)\)を\(\bm{v}\)で偏微分して\(0\)とおいた式は、
となり、再び\(\bm{S}\)の固有値問題に帰着した。そこで、先ほど求めた固有値のうち小さい方を\(\lambda_2\)と書くことにして、\(\lambda_2 = 5.185\)とする。\(\bm{S}\)の固有値問題の等式に\(\lambda = 5.185\)を代入すると、
であるから、
したがって、\(c\)をスカラー値の定数として、
と表される。さらに制約\(\|\bm{v}\|=1\)を満たすように\(\bm{v}\)を求めると、
このように求めた\(\bm{v}\)を第2主成分と呼ぶ。式(12.35)で求めた\(\bm{v}\)と逆向きであるが、固有値問題の解から同じ第2主成分が求まった。\(\lambda_2\)も目的関数の値そのものであるから、データを第2主成分の軸に写像したときの分散は\(\lambda_2 = 5.185\)である。式(12.19)を用いて第2主成分得点を求めてみると、
このデータに対する主成分分析の締めくくりとして、データ\(\mathcal{D}_s\)の第1主成分\(\bm{u}\)と第2主成分\(\bm{v}\)を可視化した。
Show code cell source
u = np.array([0.89920519, 0.43752718])
uy = 8 * u[1] / u[0]
v = np.array([-0.43752718, 0.89920519])
vy = 8 * v[1] / v[0]
fig = plt.figure(dpi=100, figsize=(6, 6))
ax = fig.add_subplot(1,1,1)
ax.scatter(D[:,0], D[:,1], marker='o', color=C)
ax.plot([-8, 8], [-uy, uy], ls='-', color='black', lw=1, label='PC1')
ax.plot([-8, 8], [-vy, vy], ls=':', color='black', lw=1, label='PC2')
draw_projections(ax, u / np.linalg.norm(u), show_xy=True)
draw_projections(ax, v / np.linalg.norm(v))
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_aspect('equal')
ax.set_xlim(-8, 8)
ax.set_ylim(-8, 8)
ax.legend()
ax.grid()
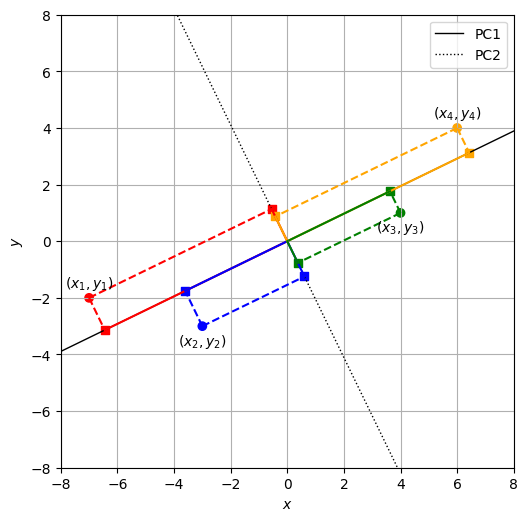
12.6. 実装#
例として用いてきたデータ\(\bm{X}\)に対して、主成分分析を行う。
X = np.array([[-7, -2], [-3, -3], [4, 1], [6, 4]])
sklearn.decomposition.PCAで\(X\)の主成分分析を行う。
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X)
PCA(n_components=2)
第1主成分と第2主成分。先ほど求めた主成分と符号が異なっているが、実質的に同じものである。
pca.components_
array([[-0.89920519, -0.43752718],
[ 0.43752718, -0.89920519]])
第1主成分と第2主成分に対応する固有値。
pca.singular_values_ ** 2
array([134.81512169, 5.18487831])
主成分得点を求める。
pca.transform(X)
array([[ 7.16949066, -1.26427988],
[ 4.0101971 , 1.38503402],
[-4.03434793, 0.85090353],
[-7.14533984, -0.97165767]])
12.7. 確認問題#
先ほどの実装では、sklearn.decomposition.PCAを用いて主成分分析を行ったが、行列\(\bm{S} = \bm{X}^\top \bm{X}\)に対して固有値問題を解くことで、主成分分析が得られることを確認したい。
(1) \(\bm{S}\)の計算
\(\bm{X}\)に対して、行列\(\bm{S} = \bm{X}^\top \bm{X}\)を求めよ。
(2) 固有値問題の解
numpy.linalg.eig等で\(\bm{S}\)の固有値問題を解き、固有値と固有ベクトルを求めよ。
(3) 第1主成分と第2主成分
第1主成分と第1主成分軸における分散、第2主成分と第2主成分軸における分散を求めよ。
(4) 第1主成分得点と第2主成分得点
第1主成分得点と第2主成分得点を求めよ。