6. 線形多クラス分類#
import numpy as np
import matplotlib.pyplot as plt
6.1. 多値分類とは#
\(\def\bm{\boldsymbol}\)二値分類を拡張し、与えられた事例を3個以上のクラスに分類する多値分類を考える。多値分類の応用範囲は広く、世の中の様々なタスクが多値分類問題として取り組まれている。
以下はリアルタイム物体認識の例である。画像(動画)中の全てのピクセルに対して、人間、車、スノーボードなどの物体のクラスを予測することで、画像中に含まれる物体とその位置を認識できる。

機械翻訳も多値分類問題の一種である。翻訳先言語の全ての単語を予測対象の「クラス」と見なす。翻訳元の文と、これまでに翻訳した単語列が与えられたとき、先頭から順に翻訳先言語の単語を分類タスクとして予測していくことで、翻訳文が得られる。

多値分類は我々の知らないところで使われていることもある。以下の例は、ツイートのプロフィールや投稿内容から、そのユーザの属性を推定する例である。推定された属性は広告の最適化や、マーケティングに用いられることがある。他にも、ニュースサイトなどのウェブサイトの閲覧履歴(どのようなページをクリックしているか)から訪問者の属性を推定し、その訪問者にとって最適な(クリック数が増えそうな)広告や記事を表示する(パーソナライゼーション)にも用いられる。

6.2. 手書き文字認識#
今回は、MNISTをデータとして用い、手書き文字(数字)認識器を構築する。MNISTは手書きの数字70,000事例(訓練用に60,000事例、評価用に10,000事例)を収録したデータセットで、それぞれの事例は\(28 \times 28\)ピクセルのグレースケール画像と認識されるべき数字で表現される。手書き数字認識は、\(28 \times 28 = 754\)ピクセルの画素値が入力(説明変数)\(\bm{x}\)として与えられたとき、認識されるべき数字(目的変数)\(\hat{y}\)を\(10\)クラス\(\mathcal{Y} = \{0, 1, 2, 3, 4, 5, 6, 7, 8, 9\}\)の中から選択する(分類する)タスクである。

{kind=link}
ここでは、mnist.npzを作成するプログラムでMNISTデータセットをNumPy形式に変換した"mnist.npz"を用いる。以下のプログラムで表示されるように、訓練データは\(60,000\) (事例) \(\times\) \(28\) (高さ) \(\times\) \(28\) (幅) のテンソル(data['train_x'])と\(60,000\) (事例) のベクトル(data['train_y'])、評価データは\(10,000\) (事例) \(\times\) \(28\) (高さ) \(\times\) \(28\) (幅) のテンソル(data['test_x'])と\(10,000\) (事例) のベクトル(data['test_y'])で構成される。
data = np.load('mnist.npz')
print("Training data (X):", data['train_x'].shape, data['train_x'].dtype)
print("Training data (Y):", data['train_y'].shape, data['train_y'].dtype)
print("Test data (X):", data['test_x'].shape, data['test_x'].dtype)
print("Test data (Y):", data['test_y'].shape, data['test_y'].dtype)
Training data (X): (60000, 28, 28) float32
Training data (Y): (60000,) uint8
Test data (X): (10000, 28, 28) float32
Test data (Y): (10000,) uint8
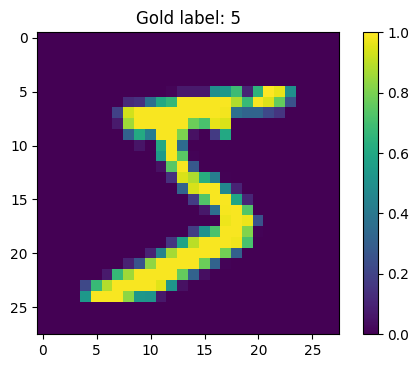
以下のプログラムは学習データ中の\(0\)番目の事例の画像と、その正解の数字を表示する。\(28 \times 28\)ピクセルの画像は\(28 \times 28\)の行列として表現され、行列の各要素はピクセルの明るさ(輝度)を表す。公式サイトで配布されているデータセットでは輝度の値が\(0\)(暗い)から\(255\)(明るい)までの整数で表現されるが、"mnist.npz"では\(0\)(暗い)から\(1\)(明るい)の範囲になるように、各輝度値を\(255\)で割っている。
i = 0
x = data['train_x'][i]
y = data['train_y'][i]
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.set_title('Gold label: {}'.format(y))
im = ax.imshow(x)
fig.colorbar(im)
plt.show()
行列の要素にアクセスするときは、縦方向のインデックス→横方向のインデックスの順番になることに注意が必要である。以下は、左上から(0から)数えて下に\(7\)番目、右に\(8\)番目のピクセルの画素値にアクセスする例である。
x[7][8]
0.93333334
二値分類では事例を\(d\)次元のベクトルで表現したが、手書き文字認識の事例は2次元の行列で表現されている。ここでは簡単のため、2次元の行列を平坦化し、1次元のベクトル\(\bm{x}\)で事例を表現する。平坦化では、画像の上端の行で左から右に画素値をスキャンしていき、一番右まで到達したら一つ下の列に移動して同様の処理を繰り返す。これにより、左上から下に\(b\)ピクセル、右に\(a\)ピクセルの画素値は、平坦化されたベクトルの\((28b + a)\)番目の要素に対応付けられる。さらに、平坦化されたベクトルの末尾に常に\(1\)となる要素を追加し、\(d = 28 \times 28 + 1 = 785\)次元のベクトルで画像を表現する。
以下のプログラムは複数の行列(画像)をまとめてベクトルに変換する。
def images_to_vectors(X):
X = np.reshape(X, (len(X), -1)) # Flatten: (N x 28 x 28) -> (N x 784)
return np.c_[X, np.ones(len(X))] # Append 1: (N x 784) -> (N x 785)
X_train = images_to_vectors(data['train_x'])
X_test = images_to_vectors(data['test_x'])
学習データ中の\(0\)番目の事例をベクトルに変換したものを可視化してみる。
x = X_train[i]
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.plot(range(len(x)), x)
ax.set_xlabel('Position')
ax.set_ylabel('Brightness')
plt.show()
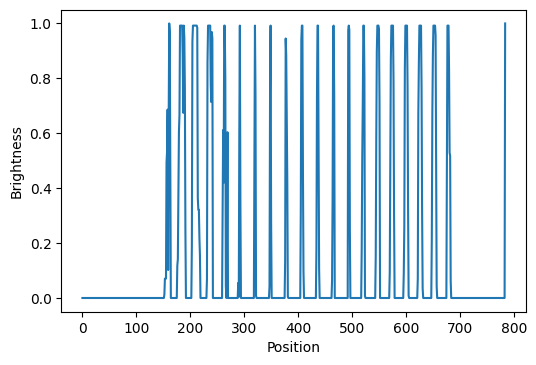
\((a,b)=(8,7)\)の画素値は\(28 \times 7 + 8 = 204\)番目の要素として現れていることが確認できる。
x[204]
0.9333333373069763
2次元の画像を1次元のベクトルに変換してしまうのは乱暴に思われるかもしれないが、このような単純な取り扱いでも驚くほどうまくいく。
6.3. 線形多クラス分類#
多クラス分類の入力と出力の表記を整理する。
入力: 分類したい事例を表す\(d\)次元の特徴ベクトル \(\bm{x} \in \mathbb{R}^{d}\)
クラス集合: 分類の候補となる\(K\)個のクラスの集合 \(\mathcal{Y} = \{\mathcal{C}_1, \mathcal{C}_2, \dots, \mathcal{C}_K\}\)
出力: 入力を分類するのに最も適切なクラス \(\hat{y} \in \mathcal{Y}\)
MNISTによる手書き文字認識の場合、入力画像は\(d=785\)次元の特徴ベクトルで表され、予測したいクラスの集合は\(\mathcal{Y} = \{0, 1, 2, 3, 4, 5, 6, 7, 8, 9\}\)である。
線形多クラス分類 (linear multi-class classification) では、各カテゴリ\(y \in \mathcal{Y}\)に重みベクトル\(\bm{w}_y \in \mathbb{R}^d\)を用意し、事例\(\bm{x} \in \mathbb{R}^{d}\)と重みベクトル\(\bm{w}_y\)との内積を計算し、最も高い内積値が計算されたカテゴリ\(y \in \mathcal{Y}\)に分類する。
線形多クラス分類のラベル推定式
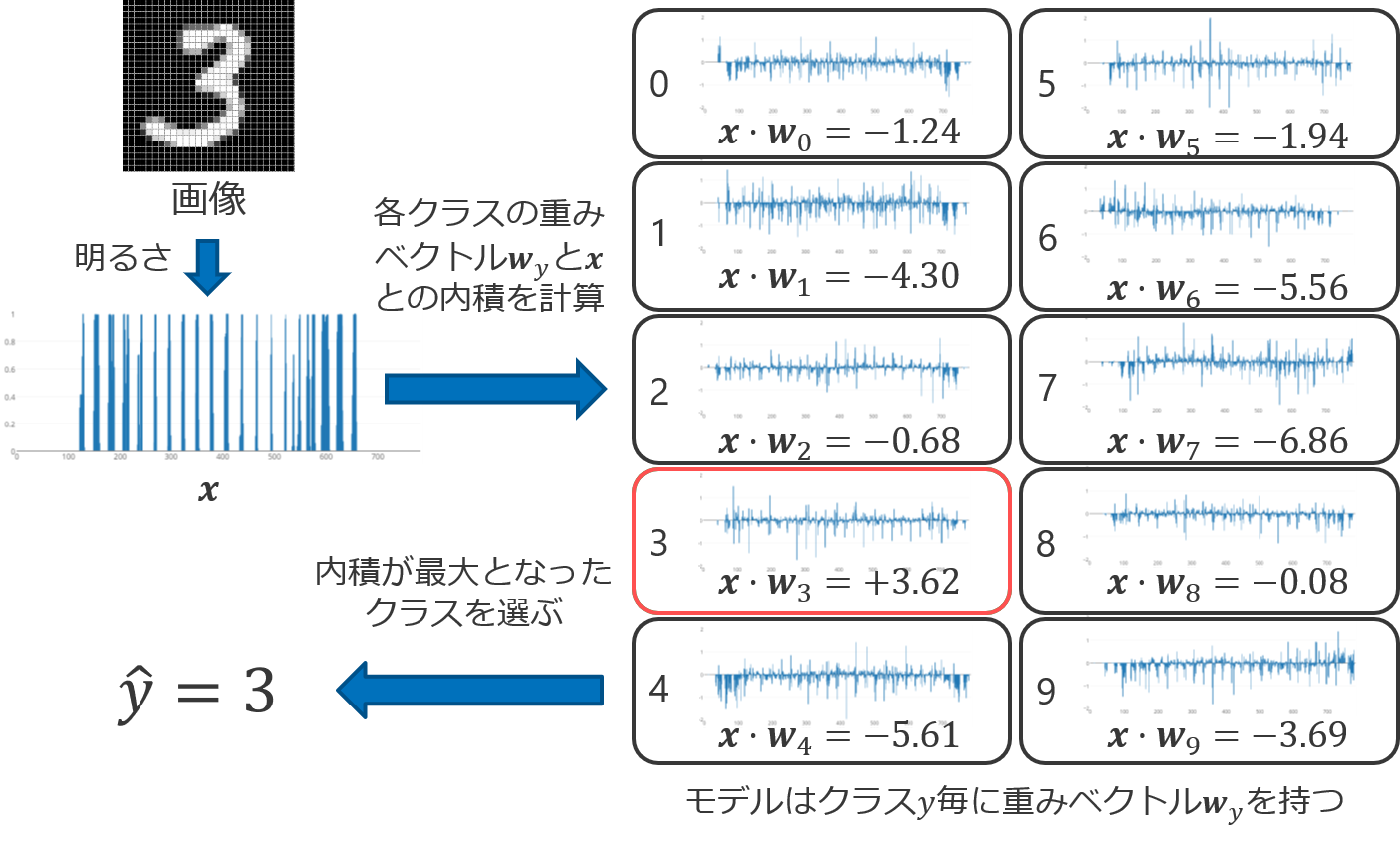
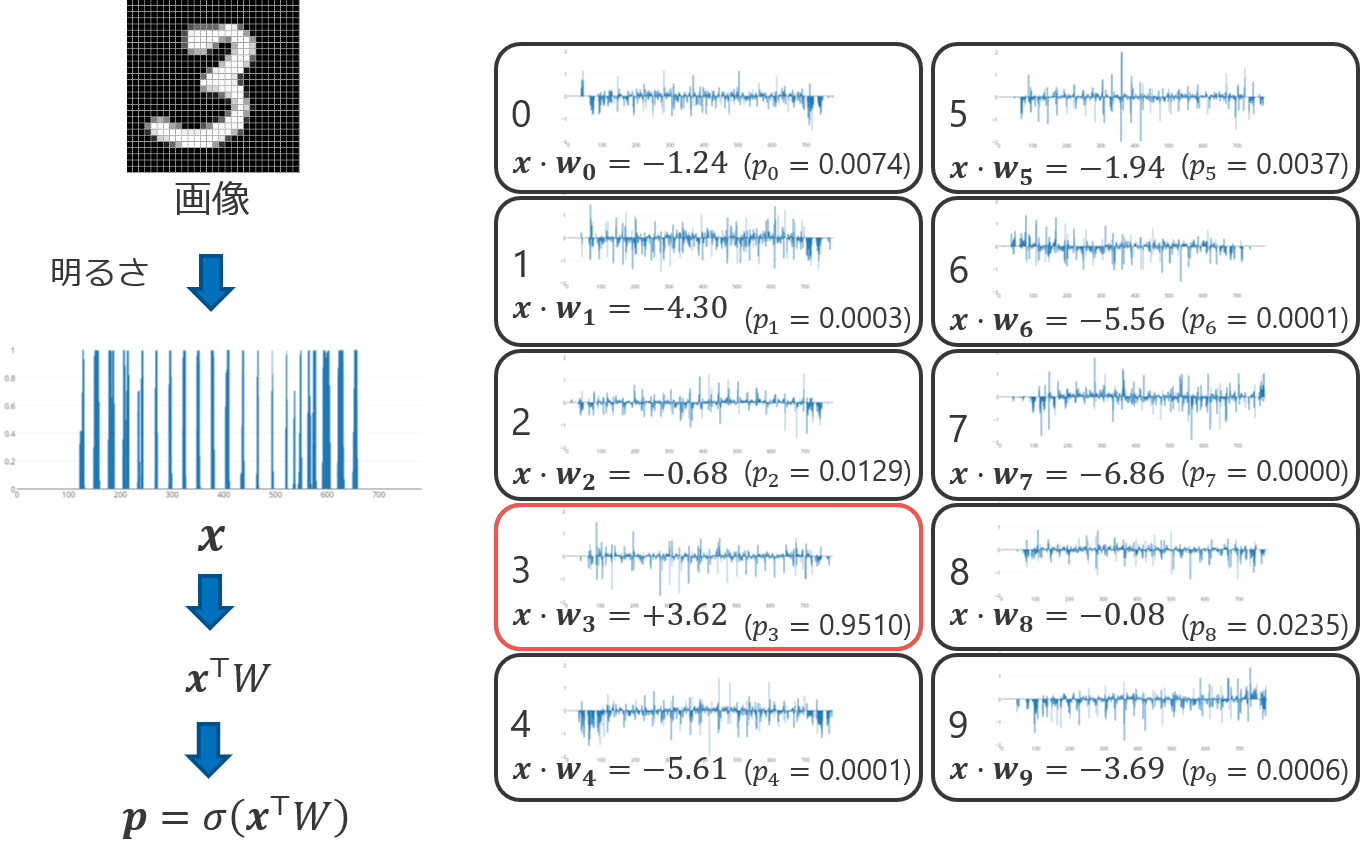
数式では分かりづらいかもしれないので、手書き数字の画像が数字に分類されるまでの流れを以下の図で示す。分類したい画像が与えられると、先ほど説明した平坦化の処理を経て、特徴ベクトル\(\bm{x}\)が作られる。線形多クラス分類のモデルは\(y \in \mathcal{Y}\)ごとに重みベクトル\(\bm{w}_y\)を保有している。特徴ベクトル\(\bm{x}\)と全てのクラスの重みベクトル\(\bm{w}_y\)との内積を計算し、その最大値を求める。下の例では、\(\bm{w}_3 \cdot \bm{x}\)の内積値が最大であったので、\(\hat{y} = 3\)、つまり入力された画像の数字を\(3\)に分類した。
線形多クラス分類モデルのパラメータ\(\bm{w}_y\)は、学習データによく合致するように(例えば学習データ上において文字認識が正しく行えるように)決定する。モデルのパラメータ\(\bm{w}_y\)を推定する方法は様々あるが、ここでは多ロジスティック回帰に基づく確率的勾配降下法を紹介する。
6.4. 多クラスロジスティック回帰#
多クラスロジスティック回帰(multi-class logistic regression)は線形多クラス分類を実現するモデルの一つで、事例\(\bm{x}\)をクラス\(\mathcal{C}_j\)に分類する条件付き確率\(P(\hat{y}=\mathcal{C}_j|\bm{x})\)を以下の式で求める。
多クラスロジスティック回帰
この式を詳しく説明するため、あるクラス\(\mathcal{C}_j\)に対するモデルの重み\(\bm{w}_j\)と事例\(\bm{x}\)との内積を\(a_j\)
と書くことにして、\(K\)個のクラスに対する内積値をベクトル\(\bm{a} \in \mathbb{R}^{K}\)にまとめる。
すると、式(6.2)はソフトマックス関数(softmax function)\(\sigma: \mathbb{R}^K \mapsto \mathbb{R}^K\)で表すことができる。
ソフトマックス関数
ここで、\(\sigma(\bm{a})_j\)はベクトル\(\bm{a}\)にソフトマックス関数を適用して計算されたベクトルの\(j\)番目の要素を表す(\(j \in \{1, 2, \dots, K\}\))。
シグモイド関数が一つの実数値のスコアを確率分布に変換したように、ソフトマックス関数は\(K\)個のスコア\(a_1, a_2, \dots, a_K\)を確率分布に変換する。二値分類におけるシグモイド関数は、多値分類におけるソフトマックス関数に対応付けられることから、両方の関数とも同じ記号\(\sigma\)で表記している。
ソフトマックス関数を実装すると以下のようになる。
def softmax(a):
ea = np.exp(a)
return ea / ea.sum()
以下のベクトルに対してソフトマックス関数を適用してみる。
a = np.array([0.1, -0.2, 0.3, -0.4, 0.5])
softmax(a)
array([0.19760595, 0.14639009, 0.24135645, 0.11985407, 0.29479344])
ソフトマックス関数への入力ベクトル、出力ベクトルを左右に並べて表示してみる。
Show code cell source
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(6.4*2, 4.8))
ax1.bar(range(1, 6), a)
ax1.set_xlabel('$k$')
ax1.set_ylabel('$a$')
ax2.bar(range(1, 6), softmax(a))
ax2.set_xlabel('$k$')
ax2.set_ylabel(r'${\rm softmax}(a)$')
fig.show()
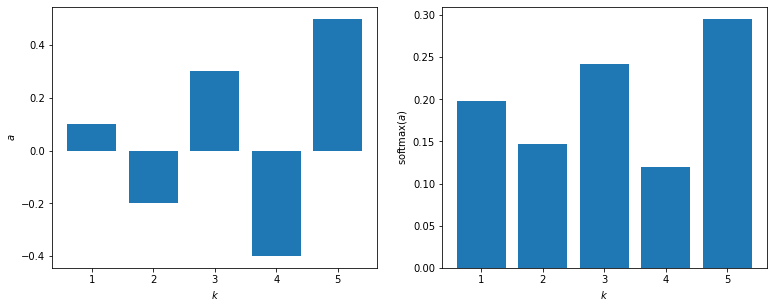
多クラスロジスティック回帰は、重みベクトルを行列で表現することで、より一般的に記述できる。重みベクトル行ベクトルとし、\(\bm{w}_1^\top, \bm{w}_2^\top, \dots, \bm{w}_K^\top \in \mathbb{R}^d\)を縦に並べた行列\(\bm{W} \in \mathbb{R}^{K \times d}\)を考える。
すると、事例\(\bm{x} \in \mathbb{R}^d\)全ての重みベクトル\(\bm{w}_k\)との内積\(a_k\)は、
とまとめて書くことができる。
さらに、\(\sigma(\bm{a})_j\)を\(p_j\)と略記することにして、ソフトマックス関数の適用結果をベクトル\(\bm{p} \in \mathbb{R}^K\)で表すことにすると、
すなわち、事例\(\bm{w}\)を線形識別の重み行列\(\bm{W}\)を用いて\(K\)個のクラスに分類するときの確率分布は、\(\bm{p} = \sigma(\bm{W}\bm{x})\)という簡単な式で表すことができる。ここで、重み行列\(\bm{W} \in \mathbb{R}^{K \times d}\)は、\(d\)次元の事例の空間\(\mathbb{R}^d\)を\(K\)個のクラスの空間\(\mathbb{R}^K\)に写像するものであると解釈できる。
これまでの定式化を手書き文字認識に当てはめた例を以下の図に示す。
6.5. ソフトマックス関数の性質#
定義から明らかなように、ソフトマックス関数は以下の性質を満たす。
また、\(K=2\)の場合は、
となることから、\((a_1 - a_2)\)を入力としたシグモイド関数と等価であることが分かる。
6.5.1. ソフトマックス関数の実装#
例えば、\(\bm{a} = \begin{pmatrix}1000 & 0\end{pmatrix}\)に対しては、\(\sigma(\bm{a}) \approx \begin{pmatrix}1 & 0\end{pmatrix}\)となることが予想される。ところが、以下のプログラムを実行すると警告が表示され、正しい実行結果が得られない。
a = np.array([1000, 0])
softmax(a)
/tmp/ipykernel_528/1334177726.py:2: RuntimeWarning: overflow encountered in exp
ea = np.exp(a)
/tmp/ipykernel_528/1334177726.py:3: RuntimeWarning: invalid value encountered in true_divide
return ea / ea.sum()
array([nan, 0.])
これは、\(e^{1000}\)の計算でオーバーフローが発生するためである。この問題を回避するには、任意の実数\(b \in \mathbb{R}\)に対して、以下の関係が成り立つことを利用する。
つまり、ソフトマックス関数の引数としてベクトル\(\bm{a}\)を与える時、その全ての要素\(a_k\)から同じ定数を引いたベクトルでソフトマックス関数を適用しても、結果は変わらない。そこで、\(\exp\)の計算結果が大きくなりすぎないように、例えばベクトル\(\bm{a}\)の要素の最大値を\(b\)として採用すればよい。
def softmax(a):
ea = np.exp(a - np.max(a))
return ea / ea.sum()
a = np.array([1000, 0])
softmax(a)
array([1., 0.])
6.5.2. ソフトマックス関数の微分#
多値分類モデルのパラメータ推定で必要になることを見越して、ここでソフトマックス関数の微分を示す。ソフトマックス関数\(\sigma: \mathbb{R}^K \mapsto \mathbb{R}^K\)を再掲する。
ここで、\(\sigma(\bm{a})_j\)はベクトル\(\bm{a}\)にソフトマックス関数を適用して計算されたベクトルの\(j\)番目の要素を表す。ソフトマックス関数が返すベクトルを陽に記述すると、
となることから明らかなように、ソフトマックス関数の計算結果の\(j\)番目の要素\(\sigma(\bm{a})_j\)は、入力されたベクトルの全ての要素の影響を受ける。したがって、
の全てを求める必要がある。ソフトマックス関数が出力するベクトルのインデックス番号を\(j \in \{1, 2, \dots, K\}\)、ソフトマックス関数に入力するベクトルのインデックス番号を\(h \in \{1, 2, \dots, K\}\)として、ソフトマックス関数の偏微分\(\frac{\partial \sigma(\bm{a})_j}{\partial a_h}\)を求める。
\(h=j\)のとき、
\(h\neq j\)のとき、
ここで、\(k = h\)の時に\(1\)を返し、それ以外の時に\(0\)を返す記法\(\delta_{jh}\)
を導入すると、ソフトマックス関数の微分は\(j=h\)と\(j \neq h\)の場合をまとめて、以下の式で表現できる。
興味深いことに、この結果はシグモイド関数の微分の結果の形によく似ている。
6.6. データの表現#
これまで、事例\(\bm{x}\)がクラス\(\mathcal{C}_j\)に分類されることを\(y=j\)と表していた。しかし、最尤推定を数式として表現しやすくするために、\(K\)次元ベクトルによる記法を導入する。事例がクラス\(\mathcal{C}_j\)に分類されることを、以下の\(y_k\)を要素とするベクトル\(\bm{y}\in \mathbb{R}^K\)で表す。
すなわち、事例がクラス\(\mathcal{C}_j\)に分類されることを、\(j\)番目の要素が\(1\)で、それ以外の要素が\(0\)であるベクトル\(\bm{y} \in \mathbb{R}^K\)で表す。このベクトルは一つの要素のみ\(1\)で、他の要素が\(0\)であるから、1-of-K表現またはone-hotベクトルなどと呼ばれる。
例えば、手書きの数字を認識するタスクにおいて、正解の数字が\(3\)であることを(\(0\)をクラス\(\mathcal{C}_1\)、\(1\)をクラス\(\mathcal{C}_2\)で表すことにしたので)クラス\(\mathcal{C}_4\)で表すことにすると、
と表現される。
以上の表記法を採用すると、多クラス分類の学習事例は\(d\)次元ベクトルの説明変数\(\bm{x} \in \mathbb{R}^d\)と\(K\)次元ベクトルの目的変数\(\bm{y} \in \mathbb{R}^K\)の1つの組として表現できる。\(1\)番目の学習事例を\((\bm{x}_1, \bm{y}_1)\)、\(2\)番目の学習事例を\((\bm{x}_2, \bm{y}_2)\)、\(i\)番目の学習事例を\((\bm{x}_i, \bm{y}_i)\)と表すことにすると、\(N\)個の事例からなるデータ\(\mathcal{D}\)は次のように表される。
6.7. 最尤推定#
多クラスロジスティック回帰のパラメータ推定の流れは、二値分類のロジスティック回帰の場合と同じである。まず、学習事例\((\bm{x}, \bm{y})\)に対するモデルパラメータ\(\bm{W}\)の尤度\(\hat{l}_{\bm{x}, \bm{y}}(\bm{W})\)を定義する。これは、事例\(\bm{x}\)のクラスが\(\mathcal{C}_j\)であるとき、条件付き確率\(P(\hat{y} = \mathcal{C}_j|\bm{x})\)を採用すればよい。
多クラスロジスティック回帰の条件付き確率は、式(6.8)より\(\bm{p} = \sigma(\bm{W}\bm{x})\)と計算されることから、
ところが、学習事例のクラスはインデックス番号\(j\)ではなく、1-of-K表現ベクトル\(\bm{y}\)で表現することにした。\(k \in \{1, 2, \dots, K\}\)に対して\(y_k = 1\)となるインデックス\(k\)があるとき、\(p_k\)がその事例の尤度であるので、
事例ごとの尤度
以下の図は、手書き文字認識においてある事例\((\bm{x}, \bm{y})\)に対するモデルパラメータ\(W\)の尤度\(\hat{l}_{\bm{x}, \bm{y}}(\bm{W})\)を尤度を計算する例である(数字との対応付けが分かりやすくなるように\(\bm{w}_j\)や\(p_j\)のインデックス番号を\(0\)から始めていることに注意せよ)。
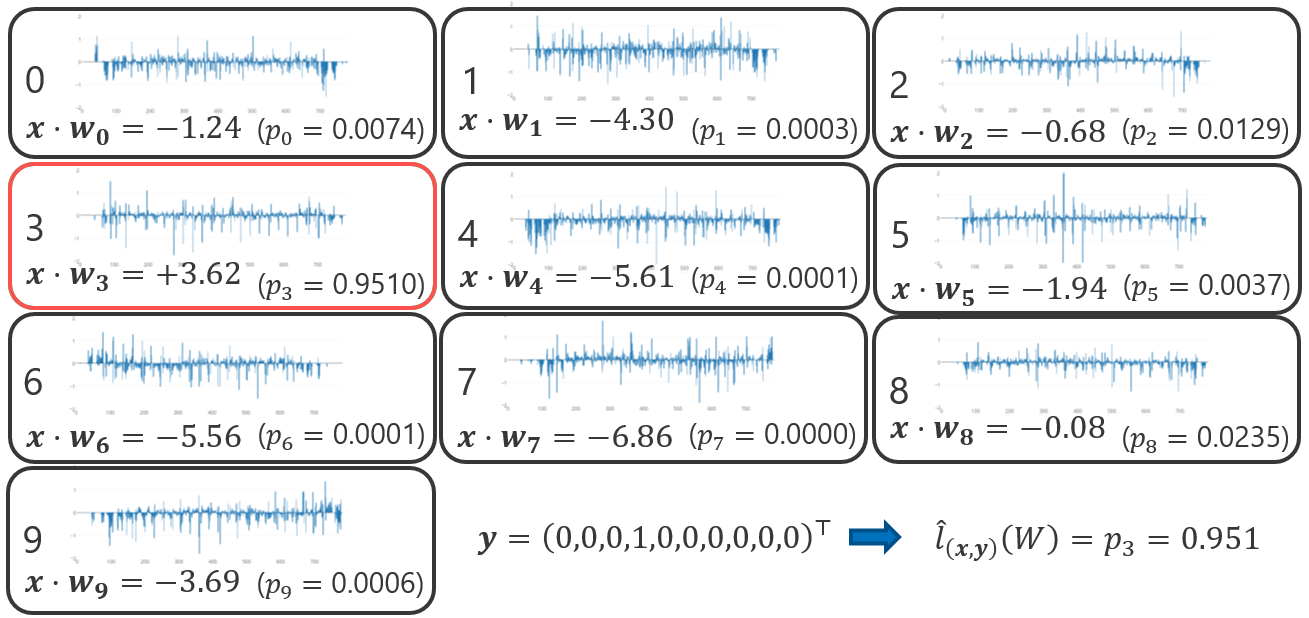
この図は、事例の尤度は画像が正解の数字に分類される確率であることを示している。
学習事例の尤度を定義したので、次は学習データ\(\mathcal{D}\)全体における尤度を定義する。学習データのすべての事例は独立同分布(i.i.d.)である仮定し、学習データ全体の尤度\(\hat{L}_{\mathcal{D}}(\bm{w})\)を各学習事例の尤度の結合確率として定義する。
\(\hat{L}_{\mathcal{D}}(\bm{W})\)を目的関数とみなし、この目的関数の値を最大化するような\(\bm{W}^*\)を求めることで、学習データ\(\mathcal{D}\)によく合致するモデルパラメータを求めることができる(最尤推定)。
ここで、二値分類のときと同様に、学習データ上の尤度を最大化するのではなく、学習データ上の負の対数尤度を最小化に書き換える。すると、多クラスロジスティック回帰モデルの学習で最小化する目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{W})\)は次式で表される。
また、学習時に\(L_2\)正則化を導入する場合、目的関数は、
となる。ここで、\(\alpha\) (\(\alpha>0\)) は\(L_2\)正則化の係数である。
6.8. 確率的勾配降下法#
これまでの議論により、多クラスロジスティック回帰モデルの学習は、目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{W})\)を最小にするパラメータ\(\bm{W}^*\)を求める問題に帰着した。二値分類のロジスティック回帰の場合と同様で、多クラスロジスティック回帰モデルの目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{W})\)は、パラメータ\(\bm{W}\)に関して偏微分はできるが、その偏微分の値を\(\bm{0}\)とする解析解を求めることができない。目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{W})\)は事例ごとの損失の和として表現されているので、確率的勾配降下法で目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}^{\rm MLE}(\bm{W})\)を最小にするパラメータ\(\bm{W}^*\)を求めることにする。
確率的勾配降下法は、各反復において事例\((\bm{x}, \bm{y}) \in \mathcal{D}\)をランダムに選びながら、以下の更新式を繰り返し適用することで、目的関数\(\hat{\mathcal{L}}_{\mathcal{D}}(\bm{W})\)を最小とするパラメータ\(\bm{W}^{*}\)を推定する。
行列\(W\)に対して偏微分を導出するのは分かりづらいかもしれないので、\(t\)回目の反復で行列\(\bm{W}^{(t)}\)の列ベクトル\(\bm{w}_j^{(t)}\)毎に偏微分を計算し、すべての\(j \in \{1, 2, \dots, K\}\)に対して、重みベクトル\(\bm{w}_j^{(t)}\)を更新する式に書き換えておく。
そこで、学習事例の対数尤度\(\log \hat{l}_{(\bm{x}, \bm{y})}(\bm{W})\)を重みベクトル\(\bm{w}_k\)で偏微分することに集中する。まず、学習事例の対数尤度\(\log \hat{l}_{(\bm{x}, \bm{y})}(\bm{W})\)を整理する。
ゆえに、
ここで、\(p_k\)は\(p_k = \sigma(\bm{a})_k\)、\(a_j = \bm{w}_j^\top\bm{x}\)という合成関数であることに着目し、式(6.19)の結果を利用すると、
この結果を確率的勾配降下法の更新式に代入すると、
確率的勾配降下法による多クラスロジスティック回帰のパラメータ更新式
6.8.1. 確率的勾配降下法の更新式の解釈#
確率的勾配降下法の更新式は、目的変数の理想値(\(y_j\))と\(t\)回目の反復における推定値(\(p_j^{(t)}\))の差をスケーリングとして、事例の特徴ベクトル\(\bm{x}^\top\)を重みベクトルに足し込むという分かりやすい形をしている。ある学習事例に対してパラメータ更新を行う例を以下に示す。
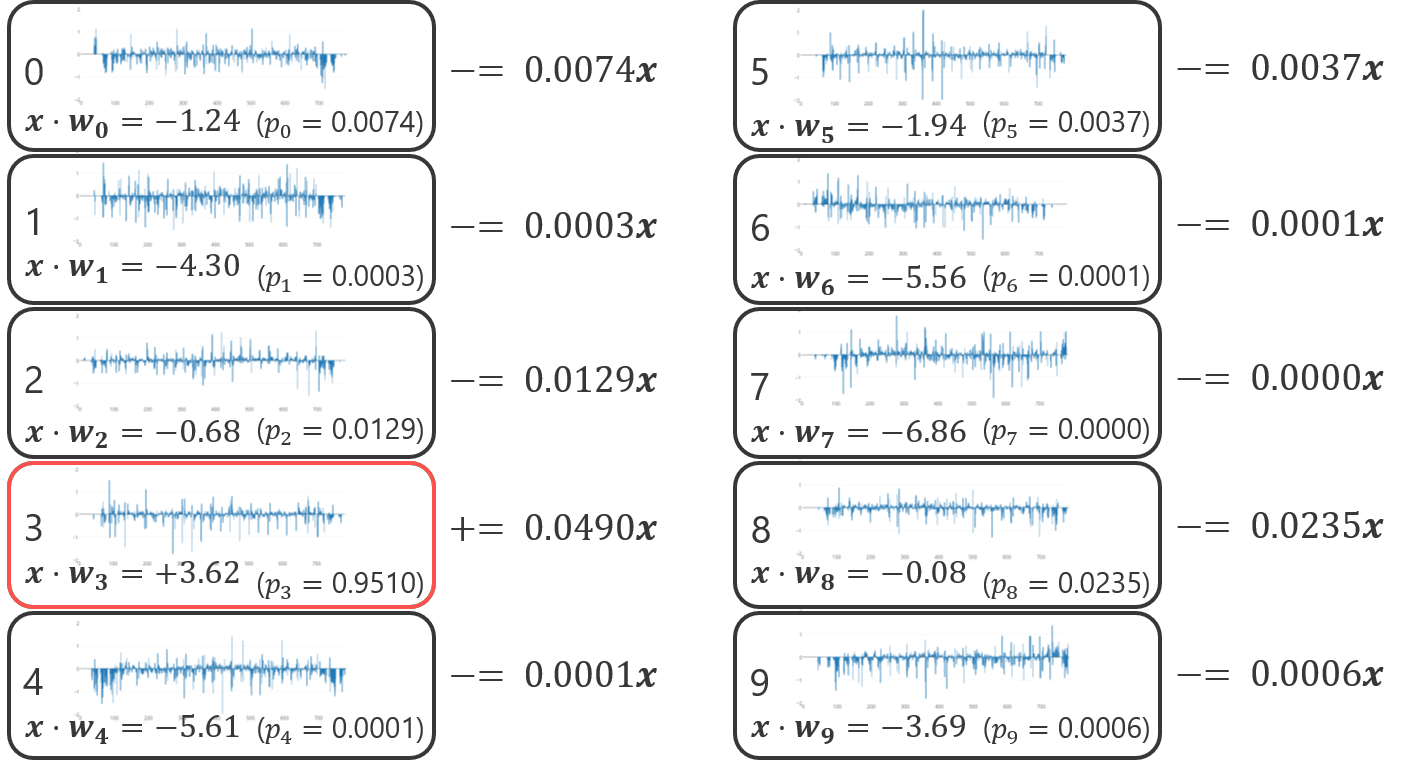
確率的勾配降下法の更新式がモデルのパラメータを望ましい方向に動かすことを確認するため、学習事例\(\bm{x}\)をクラス\(\mathcal{C}_j\)に分類すべきで、\(h \neq j\)となるクラス\(\mathcal{C}_h\)には分類すべきでない状況を想定する。
\(y_j = 1\)であるため、重みベクトル\(\bm{w}_j\)に関する更新式は、
また、\(y_h = 0\)であるため、重みベクトル\(\bm{w}_h\)に関する更新式は、
確率的勾配降下法の\(t\)回目の反復において、事例\(\bm{w}\)と重みベクトル\(\bm{w}_k^{(t)}\)との内積を\(a_k^{(t)}\)と書くことにすると、
となることから、事例\(\bm{x}\)はクラス\(\mathcal{C}_j\)に分類されやすくなり、その他のクラス\(\mathcal{C}_h\)には分類されにくくなるようにパラメータ更新が行われる。
6.9. 評価#
二値分類器の性能評価に正解率、適合率、再現率、F1スコアなどが用いられることを説明した。多値分類器の性能評価でも、これらの指標が用いられる。ただし、分類のクラスが3個以上になったため、新たに考慮すべき点が出てくる。
下の表は、評価データに対する手書き数字認識器の予測結果を行、評価データにおける実際の数字を列として、事例数をまとめたものである。例えば、\(0\)行\(0\)列の数字は、評価データにおいてモデルが数字を「0」と予測した事例のうち、実際に評価データの中で「0」と示されていた事例(予測が正しかった事例)が\(950\)件であったことを表している。\(8\)行\(2\)列の数字は、評価データにおいてモデルが数字を「8」と予測したものの、正しい数字は「2」であった事例が\(54\)件あったことを示している。このように、予測すべきクラスに関して、モデルが予測したクラスと実際(正解)のクラスの事例数をまとめた表を混同行列(confusion matrix)と呼ぶ。
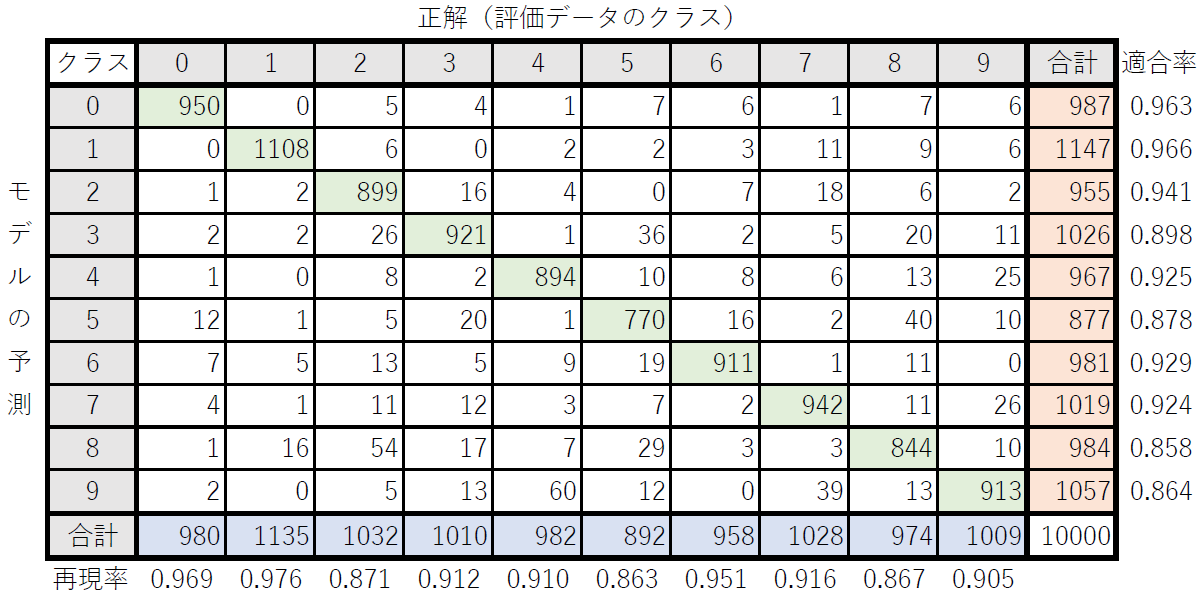
混同行列の対角成分(緑色)は多値分類器が予測に正解した事例数を表しているので、対角成分の和をとったものが全クラスにおいて予測に正解した事例数を表す。したがって、正解率は混同行列の対角成分の和を全事例数で割ったものである。
クラス\(\mathcal{C}_k\)に関する適合率は、モデルが\(\mathcal{C}_k\)として予測した事例のうち、実際に\(\mathcal{C}_k\)である事例の割合である。上の表では混同行列の各行の事例数の合計列(オレンジ色)を示している。したがって、適合率は混同行列の対角成分(緑色)をその行の事例数の合計値(オレンジ色)で割ったものとなる。
クラス\(\mathcal{C}_k\)に関する再現率は、実際に\(\mathcal{C}_k\)である事例のうち、モデルが\(\mathcal{C}_k\)として予測できた事例の割合である。上の表では混同行列の各列の事例数の合計行(青色)を示している。したがって、再現率は混同行列の対角成分(緑色)をその列の事例数の合計値(青色)で割ったものとなる。
クラス\(\mathcal{C}_k\)に関するF1スコアは、適合率と再現率の調和平均として求める。
6.9.1. マクロ平均とマイクロ平均#
これまで、適合率、再現率、F1スコアの計算はクラス\(\mathcal{C}_k\)ごとに行っていた。これにより、多値分類器の予測がどのクラスに対して強いのか・弱いのかを調べることができる。一方で、異なる多値分類器の性能を比較したいときは、各クラスの評価結果をまとめて、一つの評価結果に統合する方が便利である。各クラスの評価結果を統合する時に用いられるのが、マクロ平均(macro average)やマイクロ平均(micro average)である。
マクロ平均は、各クラスの適合率、再現率、F1スコアの平均を算出したものである。
評価データによっては、あるクラスの事例がとても多い/少ないなど、クラスによって事例数の偏りがある。その場合でも、全てのクラスの予測性能を平等に扱い、平均を取るのがマクロ平均である。
ミクロ平均は、各クラスで適合率や再現率を計算する前の事例数を分子と分母に足し合わせていく算出方法である。
これまでの設定の場合、マイクロ平均の適合率と再現率は正解率と等しくなる。
マクロ平均がその意義を発揮するのは、分類の評価から外す負のクラスを含む場合である。例えば、物体認識の例ではピクセルを人間、車、スノーボードなどのクラスに分類すると同時に、どの物体とも言えないピクセルは「その他」に分類することになる。この場合、「その他」のクラスは分類の評価から外すのが一般的であるため、マクロ平均やマイクロ平均の算出から除外することになる。今回の数字認識において、仮に認識したい数字は\(1\), \(2\), \(3\), \(4\)の4クラスだけで、それ以外の数字を「その他」とみなして分類性能の計測から除外する場合は、マクロ平均、マイクロ平均ともに以下のような計算となる。
6.10. 実装例#
sklearn.linear_model.SGDClassifierを使う例。デフォルトでは線形のサポートベクトルマシン(SVM)となるため、インスタンス化するときにloss='log'として、ロジスティック回帰を選択する。学習データが\(N\)件の事例から構成され、各事例が\(d\)次元の特徴ベクトルで表現されているとき、fitメソッドの引数Xには\(N \times d\)の行列、yには\(N\)次元ベクトルを渡せばよい。バイアス項はモデルの内部で自動的に作られるので、特徴空間側で陽に表現する必要はない。
import numpy as np
from sklearn.linear_model import SGDClassifier
def image_to_vector(X):
return np.reshape(X, (len(X), -1)) # Flatten: (N x 28 x 28) -> (N x 784)
data = np.load('mnist.npz')
Xtrain = image_to_vector(data['train_x']) # (60000 x 784) (no bias term)
Ytrain = data['train_y'] # (60000) (not one-hot encoding)
Xtest = image_to_vector(data['test_x']) # (10000 x 784) (no bias term)
Ytest = data['test_y'] # (10000) (not one-hot encoding)
model = SGDClassifier(loss='log')
model.fit(Xtrain, Ytrain)
SGDClassifier(loss='log')
評価データの先頭の事例を分類する。predictメソッドは複数の事例(\(n\)件)をまとめて分類する仕様であるため、引数Xには\(n\times d\)の行列を渡すことになっている。このため、1つだけの事例を分類する場合はスライスを使うか、reshape(1, -1)が必要。
model.predict(Xtest[0:1])
array([7], dtype=uint8)
正解のクラスと一致していることが確認できる。
Ytest[0]
7
評価データの先頭の事例に関して、分類クラスの条件付き確率\(P(\mathcal{C}_k|\bm{x})\)を求める。
model.predict_proba(Xtest[0:1])
array([[1.04771852e-04, 4.04266129e-10, 5.32192411e-04, 4.28366729e-02,
9.78897402e-06, 3.63008734e-04, 2.44318169e-08, 9.54784319e-01,
4.75248582e-05, 1.32169679e-03]])
評価データ上での正解率を計測する。
model.score(Xtest, Ytest)
0.913
混同行列を得る。
from sklearn.metrics import confusion_matrix
Ytest_pred = model.predict(Xtest)
confusion_matrix(Ytest, Ytest_pred)
array([[ 962, 0, 1, 2, 0, 3, 4, 5, 1, 2],
[ 0, 1112, 2, 2, 1, 1, 4, 1, 12, 0],
[ 10, 12, 896, 25, 12, 5, 12, 17, 36, 7],
[ 5, 1, 12, 928, 3, 18, 3, 14, 15, 11],
[ 1, 2, 3, 3, 916, 1, 3, 5, 5, 43],
[ 9, 2, 0, 38, 11, 769, 15, 10, 26, 12],
[ 11, 3, 6, 2, 10, 26, 895, 2, 3, 0],
[ 3, 8, 16, 6, 9, 2, 0, 955, 2, 27],
[ 14, 14, 8, 29, 18, 41, 10, 18, 805, 17],
[ 6, 8, 2, 15, 40, 8, 0, 34, 4, 892]])
from sklearn.metrics import precision_score, recall_score, f1_score
Ytest_pred = model.predict(Xtest)
各クラスごとの適合率、再現率、F1スコア
precision_score(Ytest, Ytest_pred, average=None)
array([0.94221352, 0.95697074, 0.94714588, 0.88380952, 0.89803922,
0.8798627 , 0.94608879, 0.90009425, 0.88558856, 0.88229476])
recall_score(Ytest, Ytest_pred, average=None)
array([0.98163265, 0.97973568, 0.86821705, 0.91881188, 0.93279022,
0.86210762, 0.934238 , 0.92898833, 0.82648871, 0.88404361])
f1_score(Ytest, Ytest_pred, average=None)
array([0.96151924, 0.96821942, 0.90596562, 0.90097087, 0.91508492,
0.87089468, 0.94012605, 0.91431307, 0.85501859, 0.88316832])
マクロ平均適合率、再現率、F1スコア
precision_score(Ytest, Ytest_pred, average='macro')
0.9122107935521413
recall_score(Ytest, Ytest_pred, average='macro')
0.911705375525386
f1_score(Ytest, Ytest_pred, average='macro')
0.9115280768024707
マイクロ平均適合率、再現率、F1スコア
precision_score(Ytest, Ytest_pred, average='micro')
0.913
recall_score(Ytest, Ytest_pred, average='micro')
0.913
f1_score(Ytest, Ytest_pred, average='micro')
0.9130000000000001
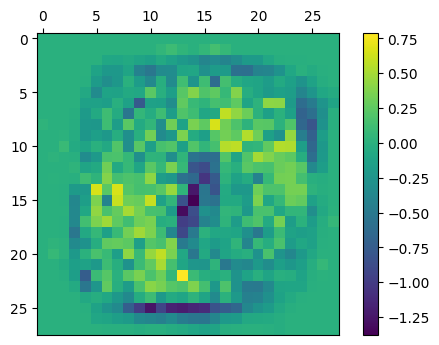
\(K \times d\)の重み行列にはcoef_属性からアクセスできる。以下は、数字を\(0\)と予測するときの重みベクトルを2次元に変換して可視化したもの。
w = model.coef_[0].reshape(28, 28)
fig, ax = plt.subplots(dpi=100)
ax.set_aspect('equal')
ax.invert_yaxis()
ax.xaxis.tick_top()
im = ax.imshow(w)
fig.colorbar(im, ax=ax)
fig.show()
6.11. 確認問題#
(1) 確率的勾配降下法による多クラスロジスティック回帰モデルの学習
確率的勾配降下法で多クラスロジスティック回帰モデルを学習するアルゴリズムを実装せよ。学習データと評価データはMNISTを用いよ。
(2) 評価データ上での正解率
評価データ上で学習したモデルの正解率を測定せよ。
6.12. 付録#
6.12.1. mnist.npzを作成するプログラム#
import gzip
import sys
import struct
import urllib.request
def read_image(fi):
magic, n, rows, columns = struct.unpack(">IIII", fi.read(16))
assert magic == 0x00000803
assert rows == 28
assert columns == 28
rawbuffer = fi.read()
assert len(rawbuffer) == n * rows * columns
rawdata = np.frombuffer(rawbuffer, dtype='>u1', count=n*rows*columns)
return rawdata.reshape(n, rows, columns).astype(np.float32) / 255.0
def read_label(fi):
magic, n = struct.unpack(">II", fi.read(8))
assert magic == 0x00000801
rawbuffer = fi.read()
assert len(rawbuffer) == n
return np.frombuffer(rawbuffer, dtype='>u1', count=n)
def openurl_gzip(url):
request = urllib.request.Request(
url,
headers={
"Accept-Encoding": "gzip",
"User-Agent": "Mozilla/5.0 (X11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11",
})
response = urllib.request.urlopen(request)
return gzip.GzipFile(fileobj=response, mode='rb')
if __name__ == '__main__':
np.savez_compressed(
'mnist',
train_x=read_image(openurl_gzip('http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz')),
train_y=read_label(openurl_gzip('http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz')),
test_x=read_image(openurl_gzip('http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz')),
test_y=read_label(openurl_gzip('http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz'))
)