3. モデル選択と正則化#
import numpy as np
from numpy.polynomial import Polynomial
import matplotlib.pyplot as plt
3.1. 汎化と過学習#
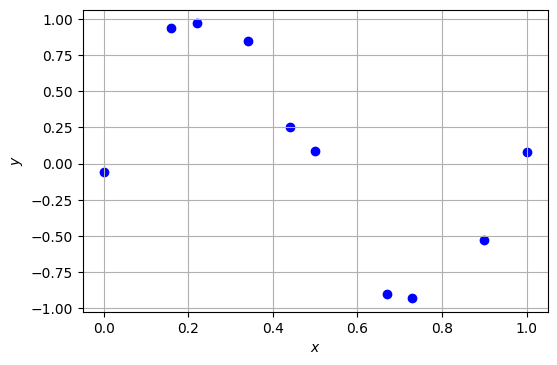
\(\def\bm{\boldsymbol}\)ここでは、以下のXを説明変数、Yを目的変数として多項式にフィッティングすることを考える。
X = np.array([ 0. , 0.16, 0.22, 0.34, 0.44, 0.5 , 0.67, 0.73, 0.9 , 1. ])
Y = np.array([-0.06, 0.94, 0.97, 0.85, 0.25, 0.09, -0.9 , -0.93, -0.53, 0.08])
Show code cell source
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='o', color='b')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.grid()
3次関数でデータX, Yをフィッティングしてみる。ここでは、多項式フィッティングを簡単に実現するnumpy.polynomialを用いる。
W3 = Polynomial.fit(X, Y, 3)
W3.convert().coef
array([ -0.06314113, 10.97825774, -32.58352732, 21.81795457])
x = np.linspace(0, 1, 1000)
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='o', color='b')
ax.plot(x, W3(x), 'r')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.grid()
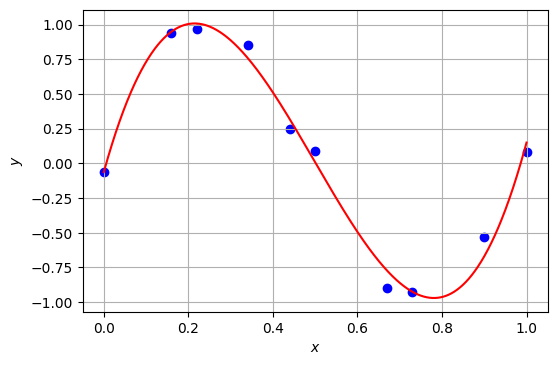
学習された3次関数のモデルの平均二乗残差は、おおよそ\(6.17 \times 10^{-3}\)である。
np.mean((Y - W3(X)) ** 2)
0.00616838615062088
3次関数でもよくデータを表現できているように見えるが、さらに近似の精度を上げるため、多項式の次数を上げてみたい。例えば、9次関数でデータX, Yをフィッティングすると、以下のようになる。
W9 = Polynomial.fit(X, Y, 9)
W9.convert().coef
array([-6.00000000e-02, 2.20316075e+02, -4.33492219e+03, 3.61547202e+04,
-1.62771499e+05, 4.32757050e+05, -6.99307115e+05, 6.74161690e+05,
-3.56090735e+05, 7.92106359e+04])
x = np.linspace(0, 1, 1000)
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='o', color='b')
ax.plot(x, W9(x), 'r')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_ylim(-1.2, 1.2)
ax.grid()
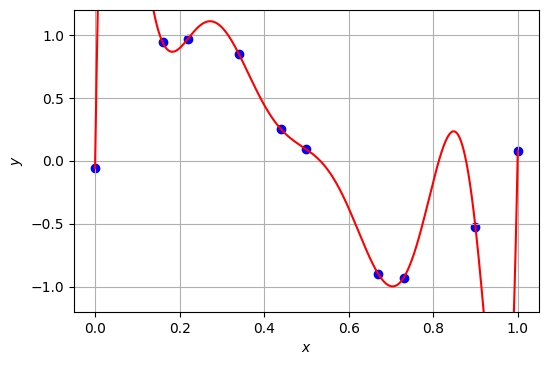
XとYの全ての点を絶妙に通過する曲線を描くことができたが、曲線がグラフの中に収まりきらなくなってしまった。そこで、\(0 \leq x \leq 1\)の範囲で曲線の全体が表示されるようにグラフを描きなおす。
x = np.linspace(0, 1, 1000)
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='o', color='b')
ax.plot(x, W9(x), 'r')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.grid()
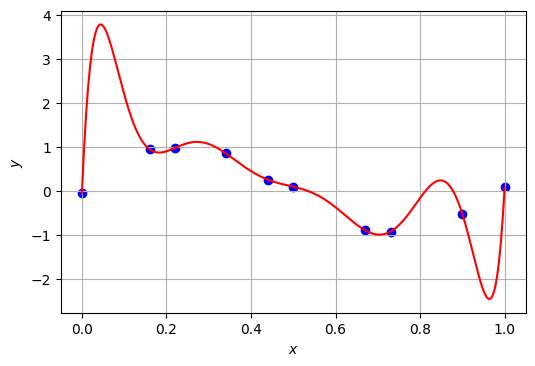
与えたデータの目的変数Yの最大値は\(0.97\)、最小値は\(-0.93\)であるが、求めた9次多項式の出力はその範囲を逸脱している。とはいえ、学習された9次関数のモデルの平均二乗残差を求めると、おおよそ\(2.03 \times 10^{-20}\)であるから、3次関数のモデルの平均二乗残差(\(6.17 \times 10^{-3}\))よりも小さい。つまり、3次関数のモデルよりも9次関数のモデルの方が、与えられたデータをよく再現できているのである。
np.mean((Y - W9(X)) ** 2)
1.6666742938195495e-27
さて、データX, Yを表現するにあたって、3次関数によるフィッティングと9次関数によるフィッティングのどちらが良いだろうか。回帰分析を行う目的は、データから説明変数と目的変数を対応付けるメカニズムを理解したり、訓練データには無かった新しい事例に対して出力を予測することであった。モデルが訓練データにはない未知の事例も普遍的に予測できることを汎化と呼ぶ。教師あり学習の目的は、汎化能力の高いモデルを学習することである。
もし、データX, Yが9次関数から生成されており、かつその正確な値がXとYに記録されていることを事前に知っているのであれば、9次関数によるフィッティングの方が適切と言える。しかし、実際にデータ分析を行うときは、目的変数と説明変数を関連付けるメカニズム(関数の形)が分からないことの方が多い(冒頭で用いた最高気温とアイスクリーム・シャーベットの支出額の関係を思い出して欲しい)。また、観測された説明変数や目的変数には、様々な要因により外乱(ノイズ)が混入することが珍しくない。実際、今回の例で用いているXとYは正弦関数\(\sin\)の入出力にノイズを加えたものであり、3次関数でも9次関数でもない。ということになると、3次関数によるフィッティングの方が真のデータをよく反映しており、汎化能力が高いと言えるのかもしれない。
この状況をグラフとして可視化した。黒の実線は\(y=\sin(2\pi x)\)の正弦曲線である。正弦曲線上で10点をランダムに選び、\(x\)軸方向と\(y\)軸方向にノイズを加えたものが、青い点で示されたデータXとYである。このデータに対して、3次関数をフィッティングしたものが青色の点線、9次関数をフィッティングしたものが橙色の破線である。データXとYが正弦関数から作られていることを知っているのであれば、3次関数のモデルのほうが汎化性能が高いことになる。9次関数のフィッティング結果のように、データを厳密に再現しようとしすぎた結果、汎化性能が低いモデルが学習されてしまう状況を過学習(過剰適合、オーバーフィッティング)と呼ぶ。
Show code cell source
W3 = Polynomial.fit(X, Y, 3)
W9 = Polynomial.fit(X, Y, 9)
x = np.linspace(0, 1, 1000)
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='o', color='b')
ax.plot(x, np.sin(2 * np.pi * x), 'black', label=r'$\sin(2\pi x)$', linestyle="solid")
ax.plot(x, W3(x), label=r'Polymominal ($d=3$)', linestyle="dotted")
ax.plot(x, W9(x), label=r'Polymominal ($d=9$)', linestyle="dashed")
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_ylim(-1.2, 1.2)
plt.legend(loc='upper right')
fig.savefig('overfitting.png')
ax.grid()
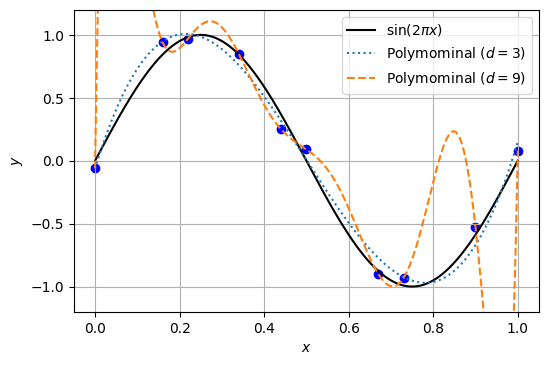
3.2. モデル選択#
データX, Yに対して汎化性能の高いモデルを獲得するにはどのようにすればよいか。素朴なアイディアとして、XとYのプロットを見ながら多項式の次数\(d\)を(ひらめきで)調整することを思いつくかもしれない。例えば、「データXとYをプロットした形状から、3次関数にフィッティングするのが適切かもしれない」といった具合である。
ただ、3次の多項式が本当に適切なのか疑問が残る。9次関数でフィッティングするのは行き過ぎだとしても、4次関数から8次関数の中に3次関数よりも適切なものがあるかもしれない。ここで、次元数\(d\)は多項式モデルのパラメータではあるが、学習によって(目的関数の最小化によって)求めるものではなく、学習に先立って与えておくものであるから、ハイパーパラメータ(hypterparameter)と呼ばれる。ハイパーパラメータを変えることによって、同じ学習データから異なるモデルが得られる。今回の例では、次元数を\(d=3, 4, \dots, 9\)と変えながらモデルを学習することで7個のモデルが得られる。さて、この中で汎化性能の高いモデルを選択するにはどのようにすればよいか?
3次関数と9次関数の学習データ上の平均二乗残差(MSR)を比較したとき、9次関数の平均二乗残差の方が小さくなった。一般に、学習データ\(\mathcal{D}\)上のモデルの損失\(\hat{L}_\mathcal{D}(\bm{W})\)は、モデルを複雑にする(例えば、多項式の次数を高くする)ことによって低下するため、汎化性能を測定する指標として用いることができない。
モデルの汎化性能を定量化する基本的なアイディアは、訓練データとは異なるデータを準備してモデルの性能を評価することである。訓練データで学習したモデルの汎化性能を測定するためのデータは、評価データ(evaluation data)やテストデータ(test data)と呼ばれる。
訓練データと評価データを分ける理由を端的に説明する例として、学校の期末試験の話をしてみたい。ある先生は学生のモチベーションを高めるために、期末試験対策の演習問題プリント(訓練データ)を学生に配布している。演習問題は修得してほしい内容の典型例を示すものであり、学生はその問題に取り組むことで、より一般的な問題の解き方を身に付けていく(汎化)。ただ、期末試験では、学生が問題の解決法を修得したのか、問題の答えを丸覚え(過学習)したのか区別する必要がある。したがって、期末試験の問題(評価データ)は演習プリント(訓練データ)のものと異なるのが通常である。
さて、汎化性能の高いモデルを選択する場合は、評価データの他に検証データ(validation data)を用意する。検証データと評価データの内容には本質的な差はなく、検証用データはモデルの選択(ハイパーパラメータを決定など)に用いられるのに対し、評価データはモデルの最終的な性能を評価するために用いられる。なお、訓練データに含まれる事例が検証データや評価データに混じってしまうと、モデルの汎化性能を測定したことにならないので、訓練データに含まれる事例が検証データや評価データに混じってはいけない。データ分析のコンペティションなどでは、訓練データ、検証データ、評価データが予め用意されていることがあるが、これらが分離されていないときは、自分でデータを適当な比率(例えば8:1:1など)で訓練データ、検証データ、評価データに分けておく。なお、検証データは開発データ(development data)と呼ばれることもある。

この図では、ハイパーパラメータを変えるなどして4つの異なるモデルを学習し、それぞれ検証データ上で性能(例えばMSRやエラー率)を測定したところ、2番目のモデルの性能が良かったので、このモデルの汎化性能が最も高いと判断している。そこで、この2番目のモデルを採用し、その最終的な性能を評価データ上で測定している。
さて、以下のX_validとY_validを検証用データとして用いてモデルを選択する例を説明する。
X_valid = np.array([ 0.05, 0.08, 0.16, 0.28, 0.44, 0.47, 0.55, 0.63, 0.84, 0.99])
Y_valid = np.array([ 0.35, 0.58, 0.87, 0.98, 0.45, 0.01, -0.36, -0.73, -0.85, -0.06])
fig, ax = plt.subplots(dpi=100)
ax.scatter(X_valid, Y_valid, marker='x', color='r')
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_ylim(-1.2, 1.2)
ax.grid()
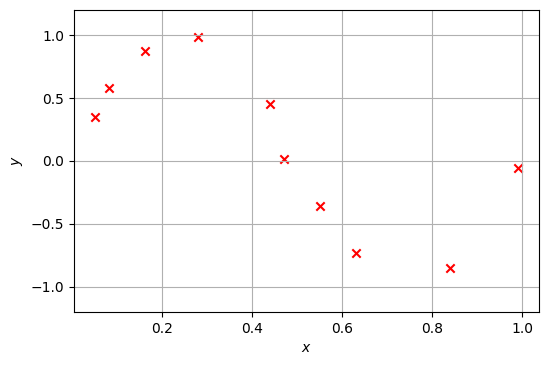
以下のプログラムは、次元数\(d\)を\(1\)から\(9\)まで変化させて多項式フィッティングを行ったとき、訓練データ上のMSRと検証データ上のMSRを計測・表示する。この結果によると、訓練データ上では次元数\(d\)を増やすことでMSRを下げることができ、\(d=9\)ではMSRがほぼ\(0\)になっていることが分かる。一方で、検証データ上のMSRは\(d=9\)の時が明らかに悪く、深刻な過学習が起こっていることを示唆している。また、検証データ上のMSRは\(d=5\)で最小(MSR=0.0052849468)となることが分かる。この実験結果から\(d=5\)のモデルが最も高い汎化性能を示すと判断し、多項式フィッティングの次元数は\(d=5\)が最適と決定するのが、検証データによるハイパーパラメータの調整(チューニング)である。
for d in range(1, 10):
W = Polynomial.fit(X, Y, d)
Y_hat = W(X)
Y_valid_hat = W(X_valid)
e_train = np.mean((Y_hat - Y) ** 2)
e_valid = np.mean((Y_valid_hat - Y_valid) ** 2)
print(f'd = {d}: MSR = {e_train:.10f} (training), {e_valid:.10f} (validation)')
d = 1: MSR = 0.2911223347 (training), 0.1731786835 (validation)
d = 2: MSR = 0.2911017232 (training), 0.1724489756 (validation)
d = 3: MSR = 0.0061683862 (training), 0.0089782205 (validation)
d = 4: MSR = 0.0059072699 (training), 0.0086822313 (validation)
d = 5: MSR = 0.0027495672 (training), 0.0052849468 (validation)
d = 6: MSR = 0.0025021465 (training), 0.0060748073 (validation)
d = 7: MSR = 0.0024176615 (training), 0.0083442287 (validation)
d = 8: MSR = 0.0023835792 (training), 0.0061707210 (validation)
d = 9: MSR = 0.0000000000 (training), 1.9813186074 (validation)
確認のため、5次関数と3次関数でフィッティングしたときの結果を以下に示す。訓練データ、検証データのいずれにおいても、3次関数よりも5次関数によるフィッティングの方が良さそうであることが分かる。
W3 = Polynomial.fit(X, Y, 3)
W5 = Polynomial.fit(X, Y, 5)
x = np.linspace(0, 1, 1000)
fig, ax = plt.subplots(dpi=100)
ax.scatter(X, Y, marker='o', label=r'Training data', color='b')
ax.scatter(X_valid, Y_valid, label=r'Validation data', marker='x', color='r')
ax.plot(x, W3(x), label=r'Polymominal ($d=3$)', linestyle="dotted")
ax.plot(x, W5(x), label=r'Polymominal ($d=5$)', linestyle="solid")
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_ylim(-1.2, 1.2)
plt.legend()
ax.grid()
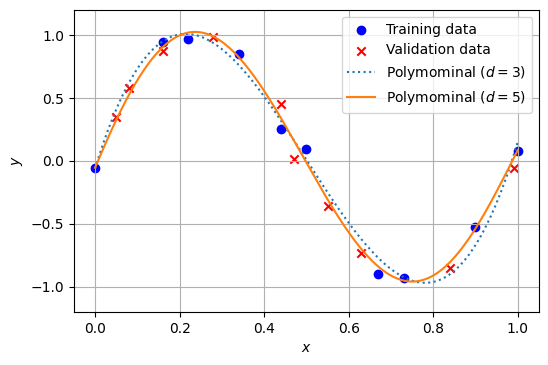
3.3. \(L_2\)正則化(リッジ回帰)#
ところで、モデルの過学習が起こるとき、パラメータはどのような値を取るのだろうか。以下のプログラムは、次元数\(d\)を\(1\)から\(9\)まで変化させて多項式フィッティングを行ったとき、実際に求められた重みベクトル\(\bm{w}\)の値を表示するものである。
np.set_printoptions(precision=1, linewidth=180)
for d in range(1, 10):
W = Polynomial.fit(X, Y, d)
print(f'd = {d}: {W.convert().coef}')
np.set_printoptions()
d = 1: [ 0.7 -1.3]
d = 2: [ 0.7 -1.3 0.1]
d = 3: [ -0.1 11. -32.6 21.8]
d = 4: [ -0.1 11.6 -35.8 27.1 -2.7]
d = 5: [-5.6e-02 8.0e+00 -5.1e+00 -6.0e+01 9.8e+01 -4.1e+01]
d = 6: [-5.9e-02 1.1e+01 -3.5e+01 5.9e+01 -1.2e+02 1.4e+02 -5.9e+01]
d = 7: [-6.0e-02 1.5e+01 -9.5e+01 3.9e+02 -1.0e+03 1.4e+03 -9.4e+02 2.5e+02]
d = 8: [-6.0e-02 9.2e+00 2.4e+00 -2.8e+02 1.4e+03 -3.4e+03 4.5e+03 -3.1e+03 8.3e+02]
d = 9: [-6.0e-02 2.2e+02 -4.3e+03 3.6e+04 -1.6e+05 4.3e+05 -7.0e+05 6.7e+05 -3.6e+05 7.9e+04]
次元数\(d\)が増加するにつれて、多項式の係数の値が急激に増加し、極端な曲線でデータをフィッティングしようとしている傾向が見受けられる。そこで、パラメータ\(\bm{w}\)の「複雑さ」を何らかの関数\(R(\bm{w})\)で測定すれば、過学習の検出に役立つ。また、学習の過程において、複雑すぎるパラメータ対してペナルティ(罰則)を与えながら、パラメータの学習を行うことができれば、過学習の抑制につながる。パラメータの訓練データへの適合度合いとパラメータの複雑さのバランスを取りながら学習する方法は、正則化(regularization)と呼ばれる。
具体的には、訓練データの適合度合い\(\hat{L}(\bm{w})\)に加えて、パラメータ\(\bm{w}\)の複雑さを表現する関数\(R(\bm{w})\) に関するペナルティ項を追加した目的関数\(\hat{J}(\bm{w})\)を採用することで、両者のバランスを自動的に保ちながらパラメータを求めることを考える。
ここで、\(\alpha\) \((\geq 0)\)は正則化の効果を指定するハイパーパラメータである。\(\alpha\)を大きく設定すると、パラメータの複雑さ\(R(\bm{w})\)が目的関数に与える影響が大きくなるので、過学習が抑制される。ただし、\(\alpha\)を大きくしすぎるとモデルのデータへの適合度合い\(\hat{L}(\bm{w})\)を軽視することになるため、過少適合(アンダーフィッティング)となる。逆に\(\alpha\)を小さく設定すると、モデルへのデータへの適合度合いを重視することになるが、過学習を抑制する効果が薄れる。このように、\(\alpha\)の設定はモデルのデータへの適合度合いと複雑さのトレードオフの関係にある。モデル選択の時と同様に、正則化の重み係数\(\alpha\)はハイパーパラメータとして検証データ上でチューニングする。
パラメータ\(\bm{w}\)の複雑さを定量化する方法はいくつかある。ここでは、最も取り扱いが簡単なパラメータベクトルの\(L_2\)ノルムの二乗を用いる。すなわち、
とする。
以下のプログラムは、次元数\(d\)を\(1\)から\(9\)まで変化させて多項式フィッティングを行ったとき、実際に求められた重みベクトルの\(R(\bm{w})\)を表示する。次元数が高い場合のパラメータベクトルは、このままでは非常に大きなペナルティを受けると想像できる。
for d in range(1, 10):
W = Polynomial.fit(X, Y, d)
W = W.convert().coef
print('d = {}: |W|_2^2 = {}'.format(d, np.dot(W, W)))
d = 1: |W|_2^2 = 2.1881924835400115
d = 2: |W|_2^2 = 2.3385062888975967
d = 3: |W|_2^2 = 1658.2355242363506
d = 4: |W|_2^2 = 2162.7387677156717
d = 5: |W|_2^2 = 15001.365517235135
d = 6: |W|_2^2 = 42524.33266368812
d = 7: |W|_2^2 = 3999189.945322787
d = 8: |W|_2^2 = 44487211.24694737
d = 9: |W|_2^2 = 1291698590072.5356
目的関数の正則化項としてパラメータの\(L_2\)ノルムを用いる回帰を、リッジ回帰(\(L_2\)正則化付き回帰)と呼ぶ。リッジ回帰の目的関数は、通常の回帰の目的関数にモデルの複雑さを表すペナルティ項を付与したもので、次式で表される。
リッジ回帰の目的関数
リッジ回帰のパラメータ推定は通常の回帰と同様である。目的関数\(J(\bm{w})\)を最小化する\(\bm{w}\)を求めるために、その勾配\(\nabla \hat{J}(\bm{w})\)を求める。重回帰の時に求めた偏微分の結果を用いると、
これを\(0\)とおき、\(\bm{w}\)について解くと、
このように、パラメータ推定の式を少し変更するだけで、リッジ回帰を実現することができる。
モデルの過学習を抑制し、汎化性能を改善したいとき、モデルに与える特徴ベクトルの要素を手作業で厳選し、過学習をコントロールすることを考えるかもしれない。例えば、先ほどの多項式フィッティングの例では、検証データを用いながら多項式の次元数\(d\)を決定できた。ところが、実際に機械学習を用いる局面では、特徴空間の次元数が膨大(例えば\(1,000,000\)次元以上)となることがある。この場合、探索すべき特徴量の組み合わせは爆発的に増えるため、検証データを用いながら汎化性能が高い特徴量の組み合わせを選ぶのは困難となる。これに対し、リッジ回帰は、モデルパラメータの重みの\(L_2\)ノルムが大きくなりすぎないようにコントロールしながらパラメータ推定を行うため、過学習の抑制を比較的容易に行える(ただし、正則化の係数\(\alpha\)を検証データ上で調整する必要がある)。
3.4. 確認問題#
(1) 9次関数によるリッジ回帰
例として用いてきた以下の学習データX, Yに対してリッジ回帰を行い、回帰曲線をプロットせよ。
ただし、正則化のハイパー・パラメータは\(\alpha = 10^{-9}, 10^{-6}, 10^{-3}, 1\)の4通りを試し、すべての回帰曲線と学習データの各点を一つのグラフ上にプロットせよ。
X = np.array([ 0. , 0.16, 0.22, 0.34, 0.44, 0.5 , 0.67, 0.73, 0.9 , 1. ])
Y = np.array([-0.06, 0.94, 0.97, 0.85, 0.25, 0.09, -0.9 , -0.93, -0.53, 0.08])
なお、scikit-learnにはリッジ回帰を行う便利なクラスsklearn.linear_model.Ridgeがあるが、ここでは使わずに本資料で説明した式をプログラムとして表現すること。
(2) パラメータの\(L_2\)ノルム
学習した4つのモデルのパラメータの\(L_2\)ノルムを計算し、表示せよ。
(3) 検証データに基づく\(\alpha\)の選択
例として用いてきた以下の検証データX_valid, Y_validに対して、これまでに学習した4つのモデルの平均二乗残差(MSR)を計算し、正則化のハイパー・パラメータとして最も汎化性能が高いと思われるものを選択せよ。
X_valid = np.array([ 0.05, 0.08, 0.12, 0.16, 0.28, 0.44, 0.47, 0.55, 0.63, 0.99])
Y_valid = np.array([ 0.35, 0.58, 0.68, 0.87, 0.83, 0.45, 0.01, -0.36, -0.83, -0.06])