13. 主成分分析 (2)#
Show code cell content
!pip install japanize-matplotlib
Requirement already satisfied: japanize-matplotlib in /usr/local/lib/python3.8/dist-packages (1.1.3)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.8/dist-packages (from japanize-matplotlib) (3.4.2)
Requirement already satisfied: pyparsing>=2.2.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (2.4.7)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (0.10.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (1.3.1)
Requirement already satisfied: numpy>=1.16 in /home/okazaki/.local/lib/python3.8/site-packages (from matplotlib->japanize-matplotlib) (1.19.5)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (8.3.1)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.8/dist-packages (from matplotlib->japanize-matplotlib) (2.8.1)
Requirement already satisfied: six in /home/okazaki/.local/lib/python3.8/site-packages (from cycler>=0.10->matplotlib->japanize-matplotlib) (1.15.0)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
\(\def\bm{\boldsymbol}\)2次元のデータの例で主成分分析の基本的な考え方を掴んだところで、多次元のデータに対する主成分分析を考えよう。
13.1. データの表現#
\(d\)次元のベクトル\(\bm{x} \in \mathbb{R}^d\)からなる事例を\(N\)件集めたデータを行列\(\bm{X} \in \mathbb{R}^{N \times d}\)で表す。
また、データの平均ベクトル\(\bm{\bar{x}} \in \mathbb{R}^d\)を次式で定義する。
13.1.1. 射影したデータの分散#
あるベクトル\(\bm{u} \in \mathbb{R}^d\)でデータ点を射影したとき、\(\bm{u}\)上に射影された点の分散\(J\)は、
射影後の点の分散
\(N\)個のデータ点\(\bm{x}_1, \dots, \bm{x}_N \in \mathbb{R}^d\)をベクトル\(\bm{u} \in \mathbb{R}^d\)で射影したとき、\(\bm{u}\)上に射影された点の分散は、
ここで、\(\bm{S} \in \mathbb{R}^{d \times d}\)はデータの分散共分散行列である。
なお、分散共分散行列\(\bm{S}\)の各要素\(S_{a,b}\)は、行列\(\bm{X}\)を用いると、
と表される。\(a\)と\(b\)を入れ替えても同じ値が求まるので、分散共分散行列\(\bm{S}\)は\(d \times d\)の実対称行列である。
13.2. 固有値問題と主成分分析#
13.2.1. 第1主成分#
主成分分析では、ある単位ベクトル\(\bm{u} \in \mathbb{R}^d\)でデータ点を射影したとき、射影された点の分散を最大化したい。前章で説明した通り、第1主成分\(\bm{u}_1\)は、\(\|\bm{u}_1\|=1\)の制約のもとで次式の目的関数を最大化する問題の解である。
これを制約なしの最大化問題に書き換えるため、ラグランジュの未定乗数法を用いる。ラグランジュ関数\(\mathcal{L}\)は、
ここで、\(\lambda_1\)はラグランジュ乗数である。ラグランジュ関数\(\mathcal{L}\)を最大化するため、\(\bm{u}_1\)に関する偏微分を\(0\)とおくと、
ゆえに、第1主成分を求める問題は分散共分散行列\(\bm{S}\)の固有値問題に帰着する。なお、上式の両辺に左から\(\bm{u}_1^\top\)をかけると、左辺は最大化したい目的関数\(J\)となり、右辺は\(\lambda_1\)となる。
したがって、射影後の分散\(J\)を最大にする第1主成分ベクトル\(\bm{u}_1\)は、\(\bm{S}\)の固有値の中で最大のものを\(\lambda_1\)として、それに対応する固有ベクトルを長さ\(1\)になるように正規化したものである。また、データ\(\bm{X}\)を第1主成分ベクトル\(\bm{u}_1\)に射影したとき、その軸における分散は\(\lambda_1\)である。
これまでの議論をまとめる。
主成分分析の第1主成分
\(N\)個の事例からなるデータ\(\bm{X} = \begin{pmatrix}\bm{x}_1 & \bm{x}_2 & \dots & \bm{x}_N \end{pmatrix}^\top\)が与えられ、その分散共分散行列を\(\bm{S}\)とする。主成分分析の第1主成分ベクトル\(\bm{u}_1\)は以下の固有値問題の解である。
ここで、\(\lambda_1\)は\(\bm{S}\)の最大の固有値で、\(\bm{u}_1\)は\(\lambda_1\)に対応する固有ベクトルを正規化したものである。データの平均ベクトルを\(\bar{\bm{x}}\)と書くことにすると、データ\(\bm{X}\)に含まれるある事例\(\bm{x}\)の第1主成分得点は、
データ点を第1主成分ベクトル\(\bm{u}_1\)に射影したとき、その軸におけるデータの分散は\(\lambda_1\)である。
13.2.2. 第2主成分以降#
第2主成分以降を一般的に求めるため、第\(k\)主成分ベクトル\(\bm{u}_1, \dots, \bm{u}_k\)までを求めてあると仮定し、第\(k+1\)主成分ベクトルを求める(\(1 \leq k < d\))。各主成分ベクトルの長さは\(1\)で、互いに直交するように選ぶので、主成分ベクトルは以下の制約を満たす(つまり、\(\bm{u}_1, \dots, \bm{u}_k\)は正規直交系である)。
第\(k+1\)主成分ベクトル\(\bm{u}_{k+1}\)は、\(\|\bm{u}_{k+1}\|=1, \bm{u}_1^\top \bm{u}_{k+1} = \dots = \bm{u}_k^\top \bm{u}_{k+1} = 0\)の制約のもとで次の目的関数を最大化する問題の解である。
これを制約なしの最大化問題に書き換えるため、ラグランジュの未定乗数法を用いる。ラグランジュ関数\(\mathcal{L}\)は、
ただし、\(\alpha_1, \dots, \alpha_k, \lambda_{k+1}\)はラグランジュ乗数である。ラグランジュ関数\(\mathcal{L}\)を最大化するため、\(\bm{u}_{k+1}\)に関する偏微分を\(0\)とおくと、
ここで、上の等式において\(\bm{u}_1^\top\)を左からかけ、式(13.13)に注意しながら展開すると、
同様に、全ての\(j \in \{1, \dots, k\}\)に対して、\(\bm{u}_j^\top\)を左からかけることで、\(\alpha_j = 0\)が示される。ゆえに、式(13.16)は、
と整理される。したがって、第\(k+1\)主成分以降を求める問題も分散共分散行列\(\bm{S}\)の固有値問題に帰着する。これを\(k=1\)から\(k=d-1\)まで繰り返すことで、すべての主成分ベクトルを求めることができる。
固有値問題による主成分分析をまとめる。
主成分分析と固有値問題
\(N\)個の事例からなるデータ\(\bm{X} = \begin{pmatrix}\bm{x}_1 & \bm{x}_2 & \dots & \bm{x}_N \end{pmatrix}^\top\)が与えられ、その分散共分散行列を\(\bm{S}\)とする。\(\bm{S}\)の\(d\)個の固有値を大きい順に並べ、
とする。また、\(\lambda_1, \lambda_2, \dots, \lambda_d\)に対応する固有ベクトルを\(\bm{u}_1, \bm{u}_1, \dots, \bm{u}_d\)とする。ただし、固有ベクトルは、
を満たすように求める。すると、\(\bm{u}_1, \bm{u}_2, \dots, \bm{u}_d\)はそれぞれ、第1主成分、第2主成分、……、第\(d\)主成分に対応する。データの平均ベクトルを\(\bar{\bm{x}}\)と書くことにすると、データ\(\bm{X}\)に含まれるある事例\(\bm{x}\)の第\(i\)主成分得点は(\(i \in \{1, \dots, d\}\))、
データ\(\bm{X}\)を各主成分に射影したとき、各軸におけるデータの分散はそれぞれ、\(\lambda_1, \lambda_2, \dots, \lambda_d\)である。
なお、式(13.19)において、\(\bm{S}\)の固有値が実数で、かつ全て非負であることは後ほど説明する。
13.3. スペクトル分解と主成分分析#
主成分分析への理解を深めるため、スペクトル分解との関連を説明する。
13.3.1. スペクトル分解#
まず、スペクトル分解を復習する。一般に、実対称行列は以下の性質を持つ。
実対称行列のすべての固有値は実数である
実対称行列\(\bm{S} \in \mathbb{R}^{d \times d}\)のある固有値を\(\lambda \in \mathbb{C}\)とする(この時点では複素数の可能性を排除していない)。また、この固有値に対応する固有ベクトルを\(\bm{q} \in \mathbb{C}^d\)と書く。
両辺の複素共役をとると(\(\bm{S}\)は実行列なので\(\bm{\bar{S}} = \bm{S}\))、
上の2つの等式、および\(\bm{S}^\top = \bm{S}\)に注意しながら\(\bm{q}^\top \bm{S} \bm{\bar{q}}\)を二通りの方法で変形する。
上の二つの等式の右辺は等しいので、次の等式が成り立つ。
一般に、複素数\((a + ib)\)とその複素共役\((a - ib)\)の積は\((a + ib)(a - ib) = a^2 + b^2 = |a + ib|^2\)であるので、
したがって、式(a)が成り立つことから\(\lambda = \bar{\lambda}\)。すなわち、\(\lambda\)は実数である。
実対称行列の固有ベクトルは正規直交系を構成する
実対称行列\(\bm{S} \in \mathbb{R}^{d \times d}\)の異なる二つの固有値を\(\lambda, \mu\)、これらに対応する固有ベクトル\(\bm{u}, \bm{v}\)とする。
\(\bm{u}\)と\(\bm{v}\)を定数倍しても上の等式は成り立つので、\(\|\bm{u}\|=\|\bm{v}\|=1\)となるように正規化しておく。上の2つの等式、および\(\bm{S}^\top = \bm{S}\)に注意しながら\(\bm{u}^\top \bm{S} \bm{v}\)を二通りの方法で変形する。
上の二つの等式の右辺は等しいので、次の等式が成り立つ。
もし、二つの固有値\(\lambda\)と\(\mu\)が異なるとき、\(\lambda - \mu \neq 0\)であるから、\(\bm{u}^\top \bm{v} = 0\)である。
もし、二つの固有値\(\lambda\)と\(\mu\)が等しいとき、すなわち実対称行列が重複する固有値を持つ場合は、対応する固有ベクトルをグラム・シュミットの直交化法により直交化すればよい。
ある実対称行列\(\bm{S} \in \mathbb{R}^{d \times d}\)の固有値を\(\lambda_1, \lambda_2, \dots, \lambda_d\)とし、対応する固有ベクトルを\(\bm{q}_1, \bm{q}_2, \dots, \bm{q}_d \in \mathbb{R}^d\)とする。
なお、固有ベクトルを正規直交系を構成するように選ぶことができるので、\(i, j \in \{1, \dots, d\}\)に関して、
等式(13.22)をベクトルとして横に並べると、次のように整理できる。
ここで、\(\bm{\Lambda} \in \mathbb{R}^{d \times d}\)は固有値を要素とする対角行列である。
また、行列\(\bm{Q} \in \mathbb{R}^{d \times d}\)は列ベクトルである固有ベクトルを横方向に配置したものである。
以下に示すように、\(\bm{Q}^\top \bm{Q} = \bm{I}\)であるから、\(\bm{Q}\)は直交行列である。
式(13.24)の右から\(\bm{Q}^\top\)をかけ、左辺において\(\bm{Q}\bm{Q}^\top = \bm{I}\)であることに注意すると、スペクトル分解(spectral decomposition)が得られる。
スペクトル分解
実対称行列\(\bm{S} \in \mathbb{R}^{d \times d}\)は、直交行列\(\bm{Q} \in \mathbb{R}^{d \times d}\)、対角行列\(\bm{\Lambda} \in \mathbb{R}^{d \times d}\)、直交行列\(\bm{Q}^\top\)の積に分解できる。
なお、
\(\bm{\Lambda}\)の対角要素\(\lambda_1, \lambda_2, \dots, \lambda_d\)は\(\bm{S}\)の固有値を並べたものである。
\(\bm{Q}\)の列ベクトル\(\bm{q}_1, \dots, \bm{q}_d \in \mathbb{R}^d\)は\(\lambda_1, \lambda_2, \dots, \lambda_d\)に対応する固有ベクトルであり、正規直交系をなす。
13.3.2. 主成分分析の導出#
スペクトル分解に基づいて主成分分析を導出してみよう。主成分分析では、データ行列\(\bm{X} \in \mathbb{R}^{N \times d}\)に対して式(13.5)で計算される分散共分散行列\(\bm{S} \in \mathbb{R}^{d \times d}\)が出発点である。以下の二つの性質により、分散共分散行列\(\bm{S}\)の固有値は非負である。
分散共分散行列は半正定値対称行列である
行列\(\bm{X} \in \mathbb{R}^{N \times d}\)の分散共分散行列を\(\bm{S} \in \mathbb{R}^{d \times d}\)とする。分散共分散行列は対称行列であるので、半正定値行列であることを示せばよい。任意のベクトル\(\bm{u}\)に対して、
が成り立つので、分散共分散行列\(\bm{S}\)は半正定値行列である。なお、この証明は式(13.38)を逆向きに辿っていると考えればよい。
半正定値対称行列の固有値はすべて非負である
半正定値対称行列を\(\bm{S}\)とする。その行列のある固有値を\(\lambda\)、対応する固有ベクトルを\(\bm{u}\)とする。すなわち、
ここで、\(\bm{S}\)の二次形式を計算すると、
分散共分散行列は半正定値対称行列であるから、左辺は非負であることが分かっている。右辺が非負となるためには、\(\lambda \geq 0\)が成り立たなければならない。
分散共分散行列\(\bm{S}\)は実対称行列であるから、直交行列\(\bm{Q} \in \mathbb{R}^{d \times d}\)と対角行列\(\bm{\Lambda} = {\rm diag}(\lambda_1, \dots, \lambda_d) \in \mathbb{R}^{d \times d}\)によるスペクトル分解が存在する。
さらに、分散共分散行列\(\bm{S}\)は半正定値対称行列であり、その固有値はすべて非負である。そこで、\(\bm{S}\)の固有値を大きい順に並べておく。
また、これらの固有値に対応するように固有ベクトル\(\bm{Q} = \begin{pmatrix}\bm{q}_1 & \bm{q}_2 & \dots & \bm{q}_d\end{pmatrix}\)を並び替えておく。
さて、式(13.38)で示したように、主成分分析における第1主成分\(\bm{u}_1 \in \mathbb{R}^d\)は以下の最大化問題で求まる。
ここで、\({\rm argmax}\)の中身、
はレイリー商(Rayleigh quotient)と呼ばる。以下で示すように、このレイリー商は\(\bm{u} = \pm \bm{q}_1\)のとき最大値\(\lambda_1\)をとる。すなわち、データ\(\bm{X}\)を第1主成分ベクトルに射影するとき、その分散の最大値は\(\lambda_1\)であり、その最大値を与える第1主成分ベクトルは\(\bm{u}_1 = \pm \bm{q}_1\)である。
レイリー商による最大値
上式は\(\lambda_1, \lambda_2, \dots, \lambda_d\)の\(z_1^2, z_2^2, \dots, z_d^2\)による重み付き平均である。したがって、その最大値は、
等号が成立するのは、\(z_1^2 = 1, z_2^2 = z_3^2 = \dots = z_d^2 = 0\)、すなわち\(\bm{u} = \pm \bm{q}_1\)のときである。
続いて、主成分分析で第\(k\)主成分までデータ\(\bm{X}\)を射影する場合を考える(\(1 \leq k \leq d\))。\(k\)個の直交基底ベクトルで射影した後のデータの分散の和の最大値は\(\lambda_1 + \dots + \lambda_k\)であること、その最大値は\(\bm{q}_1, \dots, \bm{q}_k\)で射影した場合であることを示す [Dasgupta, 2008]。
\(k\)個の直交基底ベクトルを\(\bm{u}_1, \dots, \bm{u}_k\)とおく。式(13.4)より、これらのベクトルでデータを射影した後の分散の和\(J_k\)は、分散共分散行列\(\bm{S}\)のスペクトル分解\(\bm{Q}\bm{\Lambda}\bm{Q}^\top\)を用いて、次のように展開できる。
ゆえに、分散の和\(J_k\)は\(d\)個の固有値\(\lambda_1, \dots, \lambda_d\)の\(z_1, \dots, z_d\)による重み付き和として表される。そこで、\(j \in \{1, 2, \dots, d\}\)に関して\(z_j\)の性質を調べる。まず、ベッセルの不等式より、
さらに、\(z_j\)の和は、
したがって、式(13.38)は\(0 \leq z_j \leq 1\)かつ、\(\sum_{j = 1}^{d} z_j = k\)による固有値\(\lambda_1, \dots, \lambda_d\)の重み付き和である。式(13.33)のように、分散共分散行列\(\bm{S}\)の固有値を大きい順に並べてある場合、式(13.38)が最大となるのは、\(z_1 = \dots = z_k = 1, z_{k+1} = \dots = z_d = 0\)と選んだときである。\(1 \leq j \leq k\)に対して、\(z_j = 1\)を満たすには、\(\bm{u}_j = \bm{q}_j\)とすればよい。
まとめると、\(k\)個の直交基底ベクトルでデータ\(\bm{X}\)を射影した後の分散の和\(J_k\)の最大値は、
この最大値は、データを\(\bm{q}_1, \dots, \bm{q}_k\)で射影した時に得られる。
固有値問題と主成分分析では、データの分散共分散行列\(\bm{S}\)の固有値を大きい順に並べ、対応する固有ベクトルを主成分ベクトルとして一つずつ選んでいた。式(13.41)は、\(k\)個の直交基底ベクトルでデータを射影するとき、\(\bm{q}_1, \bm{q}_2, \dots, \bm{q}_k\)を射影ベクトルに選ぶことで、射影後のデータの分散の和が最大となること、その分散の和の最大値が\(\lambda_1 + \lambda_2 + \dots + \lambda_k\)であることを保証している。
13.4. 主成分分析と次元圧縮#
データ\(\bm{X}\)の共分散行列\(\bm{S}\)の対角成分の和は、データ\(\bm{X}\)の分散の和である。\(\bm{S} = \bm{Q} \bm{\Lambda} \bm{Q}^\top\)のスペクトル分解を用いると、\(\bm{S}\)の対角成分の和は、
つまり、データ\(\bm{X}\)の分散の和は分散共分散行列\(\bm{S}\)の固有値の和に等しい
第\(k\)主成分に対応する固有値\(\lambda_k\)は、元のデータ\(X\)を第\(k\)主成分の軸に射影したときの分散を表す。全ての主成分における分散の総和に対し、第\(k\)主成分の分散が占める割合を第\(k\)主成分の寄与率と呼ぶ。
寄与率
また、第\(k\)主成分までに表現された分散の総和が、データ全体の分散の総和に占める割合を第\(k\)主成分までの累積寄与率と呼ぶ。
累積寄与率
累積寄与率は、元々\(d\)次元のベクトルで表されていたデータ点を主成分分析で\(k\)次元に圧縮したとき、元データの分散をどの程度表現できているかを表す指標である。
13.5. 応用例 (1): 麺類の支出額#
前章の冒頭で紹介した教育用標準データセット(SSDSE: Standardized Statistical Data Set for Education)の「C. 都道府県庁所在市別、家計消費データ」から麺類だけを抜き出したデータを2次元平面上で可視化してみよう。まず、データを読み込んで表示する。
df = pd.read_excel('https://www.nstac.go.jp/SSDSE/data/2021/SSDSE-C-2021.xlsx', skiprows=1)
df = df[['都道府県', '生うどん・そば', "乾うどん・そば", "パスタ", "中華麺", "カップ麺", "即席麺", "他の麺類"]]
df = df.iloc[1:]
df
| 都道府県 | 生うどん・そば | 乾うどん・そば | パスタ | 中華麺 | カップ麺 | 即席麺 | 他の麺類 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 北海道 | 3162 | 2082 | 1266 | 4152 | 5189 | 1609 | 726 |
| 2 | 青森県 | 2964 | 2224 | 1114 | 5271 | 6088 | 2039 | 554 |
| 3 | 岩手県 | 3349 | 2475 | 1305 | 5991 | 5985 | 1889 | 898 |
| 4 | 宮城県 | 3068 | 2407 | 1339 | 5017 | 5295 | 1709 | 842 |
| 5 | 秋田県 | 3231 | 3409 | 1019 | 5172 | 5013 | 1680 | 554 |
| 6 | 山形県 | 4478 | 3084 | 1288 | 5236 | 5875 | 1745 | 754 |
| 7 | 福島県 | 2963 | 2705 | 1064 | 4397 | 5862 | 1687 | 919 |
| 8 | 茨城県 | 3353 | 2477 | 1248 | 4034 | 4562 | 1440 | 653 |
| 9 | 栃木県 | 3908 | 2218 | 1391 | 4534 | 4945 | 1860 | 742 |
| 10 | 群馬県 | 4563 | 1948 | 1203 | 4153 | 5049 | 1544 | 546 |
| 11 | 埼玉県 | 4016 | 2256 | 1487 | 4512 | 4584 | 1568 | 949 |
| 12 | 千葉県 | 3389 | 2277 | 1441 | 4582 | 4513 | 1840 | 835 |
| 13 | 東京都 | 3088 | 2385 | 1595 | 4592 | 3953 | 1734 | 974 |
| 14 | 神奈川県 | 3410 | 2684 | 1472 | 4484 | 4035 | 1741 | 1049 |
| 15 | 新潟県 | 2697 | 3409 | 1308 | 4192 | 6095 | 2201 | 612 |
| 16 | 富山県 | 3294 | 2738 | 1184 | 4367 | 5576 | 1928 | 491 |
| 17 | 石川県 | 3597 | 2233 | 1339 | 5159 | 4408 | 1880 | 607 |
| 18 | 福井県 | 4124 | 2549 | 1200 | 4247 | 3838 | 1875 | 387 |
| 19 | 山梨県 | 3870 | 1947 | 1123 | 4529 | 4786 | 1580 | 660 |
| 20 | 長野県 | 4075 | 2705 | 1267 | 4333 | 4346 | 1620 | 808 |
| 21 | 岐阜県 | 3154 | 2106 | 1239 | 3816 | 4566 | 1907 | 650 |
| 22 | 静岡県 | 3045 | 2414 | 1319 | 5106 | 4582 | 1682 | 935 |
| 23 | 愛知県 | 3991 | 2198 | 1394 | 4239 | 4490 | 1882 | 731 |
| 24 | 三重県 | 3720 | 2190 | 1251 | 4176 | 4222 | 1922 | 595 |
| 25 | 滋賀県 | 3835 | 2004 | 1295 | 4121 | 4397 | 1976 | 659 |
| 26 | 京都府 | 3816 | 2160 | 1345 | 4136 | 3216 | 1959 | 596 |
| 27 | 大阪府 | 3999 | 1599 | 1013 | 3567 | 5564 | 2246 | 540 |
| 28 | 兵庫県 | 3437 | 1988 | 1129 | 3914 | 4630 | 1984 | 795 |
| 29 | 奈良県 | 3543 | 2727 | 1229 | 3973 | 4067 | 2003 | 617 |
| 30 | 和歌山県 | 3024 | 2363 | 940 | 3603 | 3972 | 1921 | 502 |
| 31 | 鳥取県 | 3455 | 1684 | 1251 | 3700 | 5687 | 3007 | 436 |
| 32 | 島根県 | 3456 | 2314 | 1316 | 4166 | 4233 | 2086 | 421 |
| 33 | 岡山県 | 3384 | 2219 | 1425 | 3958 | 4655 | 2036 | 522 |
| 34 | 広島県 | 3285 | 1851 | 1404 | 4036 | 4047 | 2077 | 585 |
| 35 | 山口県 | 3426 | 1840 | 1164 | 3342 | 4937 | 2533 | 535 |
| 36 | 徳島県 | 3692 | 2106 | 1107 | 3340 | 4149 | 2038 | 409 |
| 37 | 香川県 | 6558 | 3940 | 972 | 3661 | 4412 | 2170 | 411 |
| 38 | 愛媛県 | 3744 | 1939 | 1197 | 3624 | 3728 | 1825 | 498 |
| 39 | 高知県 | 3333 | 1513 | 1134 | 3306 | 5126 | 2234 | 478 |
| 40 | 福岡県 | 2877 | 1745 | 1354 | 3376 | 4084 | 2128 | 640 |
| 41 | 佐賀県 | 2428 | 2032 | 1132 | 3251 | 4329 | 2330 | 517 |
| 42 | 長崎県 | 2556 | 1882 | 1066 | 3720 | 4054 | 1893 | 463 |
| 43 | 熊本県 | 2307 | 1647 | 1303 | 2840 | 4631 | 2864 | 501 |
| 44 | 大分県 | 2493 | 1597 | 1074 | 3164 | 4158 | 2384 | 552 |
| 45 | 宮崎県 | 2668 | 1573 | 1185 | 3290 | 4098 | 2232 | 463 |
| 46 | 鹿児島県 | 2868 | 2391 | 1289 | 3524 | 3994 | 2054 | 462 |
| 47 | 沖縄県 | 1753 | 1488 | 1012 | 4424 | 3342 | 1481 | 229 |
7種類の麺類の品目に関して、47都道府県庁所在市別の年間支出金額が収録されたデータである。したがって、データ\(\bm{X}\)は\(47 \times 7\)の行列で表される。
X = df.iloc[:,1:].values
X
array([[3162, 2082, 1266, 4152, 5189, 1609, 726],
[2964, 2224, 1114, 5271, 6088, 2039, 554],
[3349, 2475, 1305, 5991, 5985, 1889, 898],
[3068, 2407, 1339, 5017, 5295, 1709, 842],
[3231, 3409, 1019, 5172, 5013, 1680, 554],
[4478, 3084, 1288, 5236, 5875, 1745, 754],
[2963, 2705, 1064, 4397, 5862, 1687, 919],
[3353, 2477, 1248, 4034, 4562, 1440, 653],
[3908, 2218, 1391, 4534, 4945, 1860, 742],
[4563, 1948, 1203, 4153, 5049, 1544, 546],
[4016, 2256, 1487, 4512, 4584, 1568, 949],
[3389, 2277, 1441, 4582, 4513, 1840, 835],
[3088, 2385, 1595, 4592, 3953, 1734, 974],
[3410, 2684, 1472, 4484, 4035, 1741, 1049],
[2697, 3409, 1308, 4192, 6095, 2201, 612],
[3294, 2738, 1184, 4367, 5576, 1928, 491],
[3597, 2233, 1339, 5159, 4408, 1880, 607],
[4124, 2549, 1200, 4247, 3838, 1875, 387],
[3870, 1947, 1123, 4529, 4786, 1580, 660],
[4075, 2705, 1267, 4333, 4346, 1620, 808],
[3154, 2106, 1239, 3816, 4566, 1907, 650],
[3045, 2414, 1319, 5106, 4582, 1682, 935],
[3991, 2198, 1394, 4239, 4490, 1882, 731],
[3720, 2190, 1251, 4176, 4222, 1922, 595],
[3835, 2004, 1295, 4121, 4397, 1976, 659],
[3816, 2160, 1345, 4136, 3216, 1959, 596],
[3999, 1599, 1013, 3567, 5564, 2246, 540],
[3437, 1988, 1129, 3914, 4630, 1984, 795],
[3543, 2727, 1229, 3973, 4067, 2003, 617],
[3024, 2363, 940, 3603, 3972, 1921, 502],
[3455, 1684, 1251, 3700, 5687, 3007, 436],
[3456, 2314, 1316, 4166, 4233, 2086, 421],
[3384, 2219, 1425, 3958, 4655, 2036, 522],
[3285, 1851, 1404, 4036, 4047, 2077, 585],
[3426, 1840, 1164, 3342, 4937, 2533, 535],
[3692, 2106, 1107, 3340, 4149, 2038, 409],
[6558, 3940, 972, 3661, 4412, 2170, 411],
[3744, 1939, 1197, 3624, 3728, 1825, 498],
[3333, 1513, 1134, 3306, 5126, 2234, 478],
[2877, 1745, 1354, 3376, 4084, 2128, 640],
[2428, 2032, 1132, 3251, 4329, 2330, 517],
[2556, 1882, 1066, 3720, 4054, 1893, 463],
[2307, 1647, 1303, 2840, 4631, 2864, 501],
[2493, 1597, 1074, 3164, 4158, 2384, 552],
[2668, 1573, 1185, 3290, 4098, 2232, 463],
[2868, 2391, 1289, 3524, 3994, 2054, 462],
[1753, 1488, 1012, 4424, 3342, 1481, 229]])
\(\bm{X}\)の各事例に対応する都道府県名を変数Cに保存しておく。
C = df.iloc[:,0].values
C
array(['北海道', '青森県', '岩手県', '宮城県', '秋田県', '山形県', '福島県', '茨城県', '栃木県',
'群馬県', '埼玉県', '千葉県', '東京都', '神奈川県', '新潟県', '富山県', '石川県', '福井県',
'山梨県', '長野県', '岐阜県', '静岡県', '愛知県', '三重県', '滋賀県', '京都府', '大阪府',
'兵庫県', '奈良県', '和歌山県', '鳥取県', '島根県', '岡山県', '広島県', '山口県', '徳島県',
'香川県', '愛媛県', '高知県', '福岡県', '佐賀県', '長崎県', '熊本県', '大分県', '宮崎県',
'鹿児島県', '沖縄県'], dtype=object)
\(\bm{X}\)の品目名を変数Fに保存しておく。
F = df.columns[1:].values
F
array(['生うどん・そば', '乾うどん・そば', 'パスタ', '中華麺', 'カップ麺', '即席麺', '他の麺類'],
dtype=object)
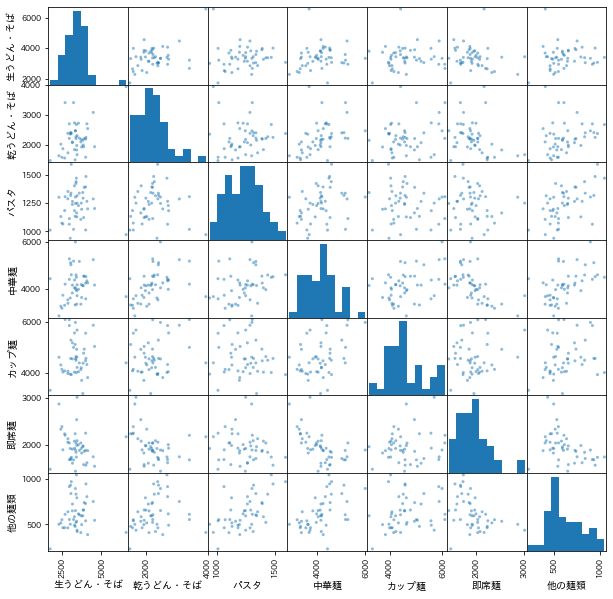
データの傾向を掴むために、散布図行列を描画してみる。対角部分はヒストグラム、非対角部分は2つの変数間に着目した場合の散布図が示される。
from pandas import plotting
plotting.scatter_matrix(df.iloc[:,1:], figsize=(10, 10), alpha=0.5)
plt.show()
sklearn.decomposition.PCAを用いて主成分分析を実行する。
from sklearn.decomposition import PCA
pca = PCA()
P = pca.fit_transform(X)
7個の主成分ベクトル(PC1からPC7)を表示する。第1主成分ベクトルの係数が概ね正であるので、第1主成分得点は麺類の消費の多さを反映すると考えられる。第2主成分ベクトルの係数は、「うどん・そば」では正、「中華麺」や「カップ麺」では負であるので、うどん・そばの消費の多さを反映すると考えられる。
pd.DataFrame(pca.components_, columns=F, index=[f'PC{i+1}' for i in range(pca.n_components_)])
| 生うどん・そば | 乾うどん・そば | パスタ | 中華麺 | カップ麺 | 即席麺 | 他の麺類 | |
|---|---|---|---|---|---|---|---|
| PC1 | 0.5050 | 0.4089 | 0.0169 | 0.5472 | 0.5031 | -0.1329 | 0.0858 |
| PC2 | 0.7567 | 0.1505 | -0.0064 | -0.2922 | -0.5624 | -0.0256 | -0.0487 |
| PC3 | -0.2577 | 0.1220 | 0.0783 | 0.6099 | -0.6228 | -0.3794 | 0.0938 |
| PC4 | -0.3246 | 0.8904 | -0.0693 | -0.2862 | -0.0487 | 0.0988 | -0.0550 |
| PC5 | 0.0214 | 0.0239 | 0.2031 | 0.3552 | -0.1849 | 0.8891 | -0.0829 |
| PC6 | 0.0054 | -0.0359 | -0.6138 | 0.1797 | -0.0219 | -0.0069 | -0.7675 |
| PC7 | -0.0093 | 0.0255 | 0.7555 | -0.0536 | 0.0759 | -0.1934 | -0.6184 |
主成分分析により、各データ点を第1から第7主成分に射影したときの主成分得点を表形式で表示する。
pd.options.display.float_format = '{:.4f}'.format
pd.DataFrame(P, columns=[f'PC{i+1}' for i in range(pca.n_components_)], index=C)
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | |
|---|---|---|---|---|---|---|---|
| 北海道 | 153.4222 | -534.3034 | -152.1148 | -141.8253 | -420.6236 | -98.0002 | 65.1171 |
| 青森県 | 1101.6032 | -1496.8960 | -152.2914 | -252.7109 | 175.4282 | 299.5492 | -12.7754 |
| 岩手県 | 1793.4762 | -1334.3605 | 386.5550 | -402.2430 | 341.3197 | 43.9761 | -95.7998 |
| 宮城県 | 763.3783 | -877.5282 | 352.0041 | -76.2460 | -33.1394 | -91.6132 | 0.0315 |
| 秋田県 | 1172.0693 | -473.2078 | 661.3547 | 767.5094 | 34.5863 | 324.9647 | -63.6768 |
| 山形県 | 2150.6186 | -95.0627 | -182.2755 | -10.1633 | 12.6520 | 16.8480 | 45.4275 |
| 福島県 | 783.0933 | -1051.2636 | -321.7877 | 385.6438 | -435.1023 | -116.8548 | -166.2046 |
| 茨城県 | 47.2661 | 64.7670 | 221.2223 | 200.7490 | -480.9328 | -50.3860 | 96.3663 |
| 栃木県 | 642.1218 | 68.3046 | -26.7517 | -345.0909 | 26.5946 | -115.6424 | 58.6243 |
| 群馬県 | 728.3322 | 594.9992 | -438.8713 | -701.5308 | -423.2849 | 94.8302 | 114.2694 |
| 埼玉県 | 576.7350 | 361.9543 | 299.1710 | -369.3226 | -168.5329 | -328.2688 | 33.3482 |
| 千葉県 | 224.5805 | -90.9914 | 432.7337 | -127.3440 | 98.5016 | -204.3793 | 13.7063 |
| 東京都 | -130.8999 | 4.4330 | 943.6409 | 62.1463 | 127.2547 | -396.2840 | 27.0850 |
| 神奈川県 | 139.5407 | 275.5104 | 774.9649 | 255.8418 | 62.7917 | -408.6177 | -96.9218 |
| 新潟県 | 851.1234 | -1217.4607 | -642.1768 | 1196.9064 | -7.8734 | -103.1752 | 157.6930 |
| 富山県 | 736.6941 | -612.2866 | -365.4479 | 369.1469 | -110.8816 | 137.8001 | 120.1706 |
| 石川県 | 547.9223 | -39.0012 | 746.5229 | -370.5084 | 359.9966 | 141.6180 | 27.9426 |
| 福井県 | 136.8892 | 1006.1167 | 418.3710 | 49.8097 | 145.8780 | 235.9303 | 68.7181 |
| 山梨県 | 455.0597 | 102.5065 | 123.4897 | -569.4544 | -249.6373 | 125.8385 | -57.3433 |
| 長野県 | 549.7100 | 667.2875 | 327.6183 | 102.2576 | -162.8597 | -128.1230 | -53.2867 |
| 岐阜県 | -384.6726 | -91.9716 | -86.3750 | 44.1388 | -158.5730 | -72.7617 | 5.4615 |
| 静岡県 | 455.8524 | -522.6362 | 874.5050 | -59.6981 | 94.2201 | -119.2878 | -125.8976 |
| 愛知県 | 281.7116 | 470.1198 | 43.7052 | -280.6772 | 28.3411 | -151.0600 | 43.4152 |
| 三重県 | -47.1050 | 439.4803 | 201.9089 | -147.4071 | 67.3410 | 34.2168 | -2.9096 |
| 滋賀県 | -8.0834 | 411.3792 | -3.9890 | -344.3619 | 65.1042 | -48.7050 | -9.2709 |
| 京都府 | -542.1400 | 1083.4309 | 769.0285 | -147.7499 | 292.4058 | -8.0488 | -15.5865 |
| 大阪府 | 142.2460 | -19.1879 | -1296.0106 | -603.7145 | -160.9610 | 104.1794 | -94.4841 |
| 兵庫県 | -203.8417 | 31.4682 | -178.0018 | -176.7118 | -98.2611 | -95.1057 | -188.2460 |
| 奈良県 | -115.2237 | 529.8485 | 255.3790 | 462.1403 | 98.6741 | -23.0343 | -34.3392 |
| 和歌山県 | -780.2281 | 253.3868 | 175.8894 | 435.2915 | -157.0167 | 189.0887 | -157.5332 |
| 鳥取県 | -69.1043 | -542.0104 | -1420.7600 | -331.0915 | 587.4943 | 47.9239 | 11.8743 |
| 島根県 | -165.2852 | 258.9724 | 198.6653 | 72.2967 | 232.5081 | 118.8384 | 129.0717 |
| 岡山県 | -124.8443 | 9.2985 | -147.0644 | 32.0185 | 46.0927 | -68.8385 | 200.0767 |
| 広島県 | -588.9009 | 194.1220 | 248.4702 | -254.1786 | 202.2912 | -64.5546 | 78.4911 |
| 山口県 | -523.1440 | -6.2518 | -963.2277 | -90.0340 | 154.8302 | -25.0465 | -56.9032 |
| 徳島県 | -623.5714 | 697.9746 | -338.2960 | 61.3932 | -129.3636 | 118.8313 | 18.2818 |
| 香川県 | 1861.8465 | 2898.5926 | -881.5167 | 681.5892 | 130.8813 | 200.6197 | -87.5708 |
| 愛媛県 | -684.5301 | 866.4939 | 159.5305 | -197.1324 | -132.0062 | 63.2729 | 20.4916 |
| 高知県 | -594.0772 | -211.0039 | -1013.0915 | -374.2155 | -169.9183 | 39.8092 | 22.3229 |
| 福岡県 | -1183.6986 | 37.7734 | -103.0164 | -23.5416 | -19.5804 | -194.1989 | 36.1238 |
| 佐賀県 | -1279.3688 | -357.8023 | -286.6590 | 443.6874 | 32.6912 | -5.4547 | -57.7901 |
| 長崎県 | -1105.4465 | -251.6660 | 274.9161 | 112.1158 | -148.1998 | 175.8729 | -40.7751 |
| 熊本県 | -1640.3146 | -571.0515 | -931.9119 | 284.8872 | 329.9288 | -169.0873 | 14.2677 |
| 大分県 | -1563.1952 | -255.2315 | -324.8045 | 75.9314 | 57.7498 | 7.0017 | -153.7285 |
| 宮崎県 | -1431.4404 | -121.9727 | -200.6135 | -53.1888 | 11.5342 | 33.9756 | 1.0191 |
| 鹿児島県 | -894.9367 | 146.5679 | 130.7319 | 523.5690 | 0.6234 | -11.8609 | 113.2129 |
| 沖縄県 | -1611.2403 | -701.6404 | 1436.6764 | -168.9272 | -150.9670 | 543.4036 | 48.4329 |
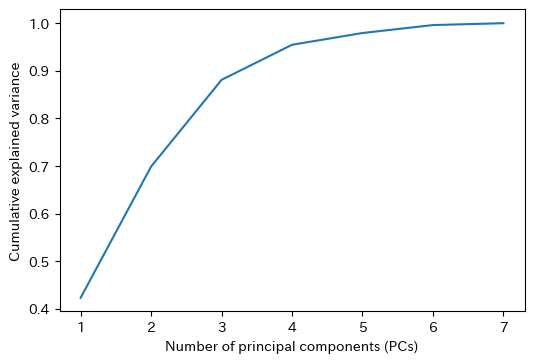
用いる主成分の数\(k\)を横軸、累積寄与率を縦軸としてグラフを描画する。第2主成分までで元データの分散の約70%、第3主成分までで元データの分散の約90%を説明できることが分かる。
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.plot(np.arange(1, pca.n_components_+1), np.cumsum(pca.explained_variance_ratio_))
ax.set_xlabel('Number of principal components (PCs)')
ax.set_ylabel('Cumulative explained variance')
fig.show()
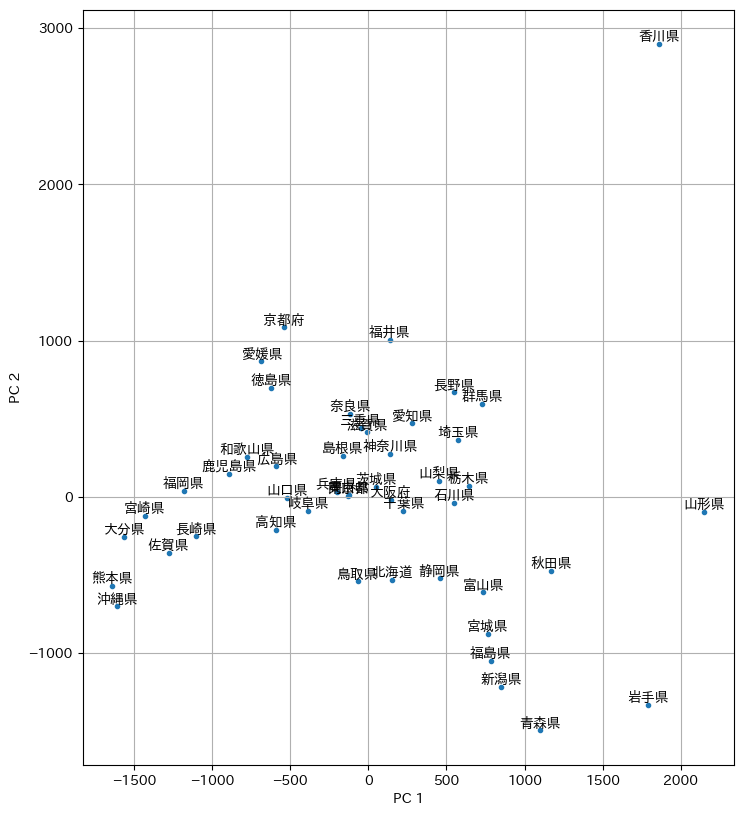
第1主成分得点を横軸、第2主成分得点を縦軸として、各都道府県庁所在地の麺類の支出金額を2次元平面上にプロットしてみる。これだけでも、地理的に近い都道府県庁所在地が近くにプロットされるのが興味深い。第1主成分得点が最も高いのは山形市(山形県)であり、周辺に他の都道府県庁所在地がプロットされていないことから、麺類の支出金額が特徴的であることが分かる。ただ、他の都道府県を全く寄せ付けない圧倒的な存在感を示すのは、第1主成分得点と第2主成分得点のいずれも高い高松市(香川県)である。
fig = plt.figure(dpi=100, figsize=(10, 10))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('PC 1')
ax.set_ylabel('PC 2')
m = ax.scatter(P[:, 0], P[:, 1], marker='.')
for i, label in enumerate(C):
ax.text(P[i][0], P[i][1], label, ha='center', va='bottom')
ax.set_aspect('equal')
ax.grid()
fig.show()
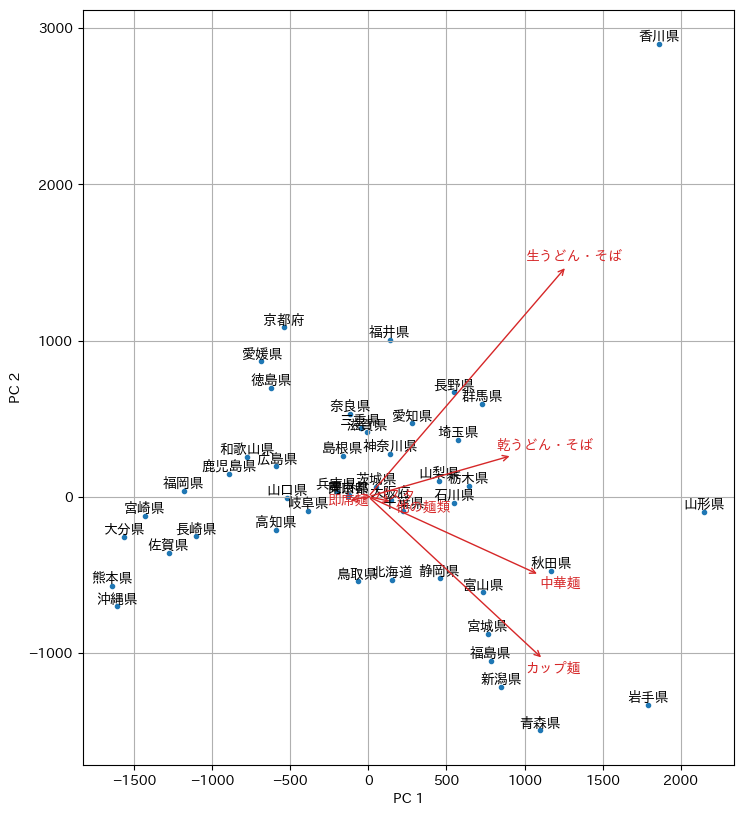
各都道府県庁所在地がどの品目に支出するのかを表すため、各品目を2,000円消費したときの点を原点からの矢印で表示した。高松市(香川県)は「生うどん・そば」に対する支出が特徴的であること、青森市(青森県)はカップ麺に対する支出が特徴的であること、山形市(山形県)は麺類全般に対して支出していることが示唆される。
fig = plt.figure(dpi=100, figsize=(10, 10))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('PC 1')
ax.set_ylabel('PC 2')
ax.set_aspect('equal')
m = ax.scatter(P[:, 0], P[:, 1], marker='.')
for i, label in enumerate(C):
ax.text(P[i][0], P[i][1], label, ha='center', va='bottom')
for i, label in enumerate(F):
ax.annotate(
label, xy=(0, 0), xytext=pca.components_[:2,i] * 2000,
color="tab:red", arrowprops=dict(arrowstyle='<-', color="tab:red")
)
ax.grid()
fig.show()
13.6. 応用例 (2): 手書き文字#
scikit-learnのsklearn.datasets.load_digitsを使い、手書き文字認識のデータセットを読み込む。
from sklearn.datasets import load_digits
X, y = load_digits(return_X_y=True)
読み込まれたデータは\(1797\)事例からなり、各事例は\(64\)(\(8 \times 8\)ピクセル)次元。
X.shape
(1797, 64)
y.shape
(1797,)
データ中の先頭の事例の画像をプロットする。
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.matshow(X[0].reshape(8, -1))
fig.show()

入力データは\(64\)次元の特徴空間で表現されていたが、主成分分析を用いて特徴空間を\(2\)次元に圧縮する。
from sklearn.decomposition import PCA
pca = PCA(2)
P = pca.fit_transform(X)
各事例の特徴空間の次元が\(2\)次元になった。
P.shape
(1797, 2)
先ほどの画像の特徴ベクトルを\(2\)次元に圧縮したものを表示する。
P[0]
array([-1.25946627, 21.2748836 ])
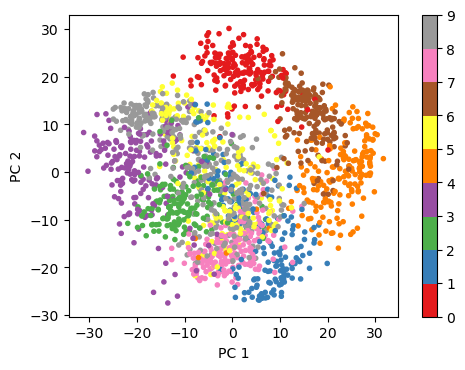
各事例の特徴ベクトルが\(2\)次元に圧縮されたので、それらを\(2\)次元平面上にプロットする。そのとき、画像の数字の正解で色分けを行うと、同じ数字の画像が近くにまとまっていることが確認できる。
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('PC 1')
ax.set_ylabel('PC 2')
ax.set_aspect('equal')
m = ax.scatter(P[:, 0], P[:, 1], c=y, marker='.', cmap='Set1')
fig.colorbar(m)
fig.show()
第1主成分ベクトルと第2主成分ベクトルを2次元画像として可視化する。入力画像とこれらの主成分ベクトルとの内積で主成分得点(射影後の値)が計算される。
fig, axes = plt.subplots(1, 2, dpi=100)
for i, ax in enumerate(axes.flat):
ax.matshow(pca.components_[i].reshape(8, -8))
ax.set_title(f'PC {i+1}', y=-0.2)
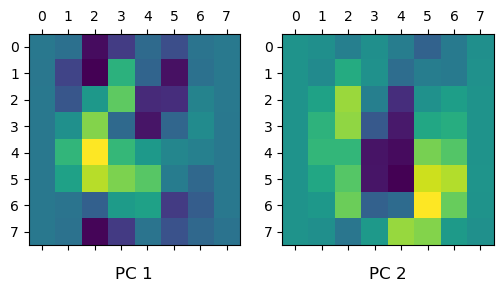
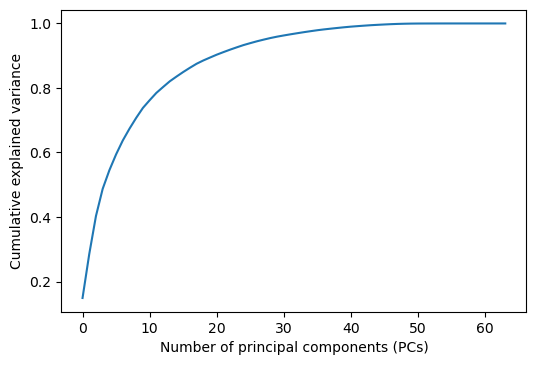
横軸を主成分の数、縦軸を累積寄与率としてグラフを書いてみると、おおよそ10数個の主成分ベクトルでデータ全体の分散の80%以上をカバーできることが分かる。
pca = PCA()
pca.fit(X)
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.plot(np.cumsum(pca.explained_variance_ratio_))
ax.set_xlabel('Number of principal components (PCs)')
ax.set_ylabel('Cumulative explained variance')
fig.show()
13.7. 応用例 (3): 固有顔#
固有顔(Eigenface)と呼ばれる手法を体験してみよう。固有顔は顔画像のデータに対して主成分分析を行い、主成分ベクトルを求めたもので、顔認識の特徴量抽出(の次元圧縮)に用いられる。今回は、sklearn.datasets.fetch_lfw_peopleを用いて、顔画像のデータを読み込む。
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=60)
読み込まれたデータは\(1348\)件で、それぞれ、縦が\(62\)ピクセル、横が\(47\)ピクセルの画像になっている。
faces.images.shape
(1348, 62, 47)
読み込まれた画像を、その人物名と一緒に表示する。
fig, axes = plt.subplots(4, 4, dpi=100, figsize=(8, 8))
for i, ax in enumerate(axes.flat):
ax.imshow(faces.images[i], cmap='binary_r')
ax.set_title(faces.target_names[faces.target[i]], y=-0.2)
ax.set_axis_off()

顔画像データに主成分分析をかけて、150個の主成分ベクトルを求める。
from sklearn.decomposition import PCA
pca = PCA(150)
pca.fit(faces.data)
PCA(n_components=150)
sklearn.decomposition.PCAは、主成分分析を行う前に、データの事例ベクトルの平均を自動的に取り除く。その平均を2次元で可視化することで、先ほどのデータセットの顔画像の「平均」を見ることができる(彫りが深い…)。
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.imshow(pca.mean_.reshape(faces.images[0].shape), cmap='bone')
fig.show()

第1主成分から順に、第16主成分まで可視化してみる。
fig, axes = plt.subplots(4, 4, dpi=100, figsize=(8, 8))
for i, ax in enumerate(axes.flat):
ax.imshow(pca.components_[i].reshape(62, 47), cmap='bone')
ax.set_title(f'PC {i+1}', y=-0.2)
ax.set_axis_off()

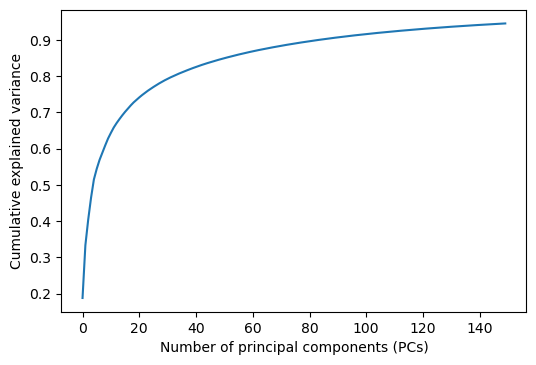
横軸を主成分の数、縦軸を累積寄与率としてグラフを書いてみると、だいたい30個弱の主成分ベクトルでデータ全体の分散の80%以上をカバーできることが分かる。
fig = plt.figure(dpi=100)
ax = fig.add_subplot(1,1,1)
ax.plot(np.cumsum(pca.explained_variance_ratio_))
ax.set_xlabel('Number of principal components (PCs)')
ax.set_ylabel('Cumulative explained variance')
fig.show()
画像データを\(150\)次元の空間に射影してから、元の画像の空間に戻してみると、元画像を少ない情報量に圧縮した画像を得ることができる。以下の可視化では、上段が元画像、下段が圧縮後の画像である。
P = pca.transform(faces.data)
PB = pca.inverse_transform(P)
fig, axes = plt.subplots(2, 8, dpi=100, figsize=(8, 2))
for i in range(8):
axes[0, i].imshow(faces.data[i].reshape(62, 47), cmap='binary_r')
axes[0, i].set_axis_off()
axes[1, i].imshow(PB[i].reshape(62, 47), cmap='binary_r')
axes[1, i].set_axis_off()
