9. サポートベクトルマシン#
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation
import matplotlib.colors
from IPython.display import HTML
\(\def\bm{\boldsymbol}\)サポートベクトルマシン(SVM: Support Vector Machines)は、「マージン最大化」や「カーネルトリック」などの興味深い特徴を持つ回帰・分類モデルである。元となるアイディアは1963年に発表されたが、1990年代に研究が進み、2000年頃から回帰や分類でよく用いられるようになった。ニューラルネットワークと同様に、非線形な分類器を構築できる。この章では、ハード・マージン・サポートベクトルマシンを通して、基本的なアイディアを説明したい。なお、この章の説明では Winston [2010] を参考にした。
なお、この章においてグラフの描画に用いられるユーティリティ関数は、以下の隠しセルで定義されている。どのようにグラフを描画しているのか把握できるように、説明の箇所では関数呼び出しのプログラムのみを示している。呼び出される関数の実装については、以下のセルを参照せよ。
Show code cell content
def find_range(Xx, Xy):
xmin, xmax = Xx.min() - 0.1, Xx.max() + 0.1
ymin, ymax = Xy.min() - 0.1, Xy.max() + 0.1
if xmax - xmin < ymax - ymin:
xmid = (xmax + xmin) / 2
xmin = xmid - (ymax - ymin) / 2
xmax = xmid + (ymax - ymin) / 2
else:
ymid = (ymax + ymin) / 2
ymin = ymid - (xmax - xmin) / 2
ymax = ymid + (xmax - xmin) / 2
return ((xmin, xmax), (ymin, ymax))
def init_graph(X, Y, dpi=100, figsize=(6,6)):
(xmin, xmax), (ymin, ymax) = find_range(X[:,0], X[:,1])
fig, ax = plt.subplots(dpi=dpi, figsize=figsize)
ax.set_xlabel('$x_1$')
ax.set_ylabel('$x_2$')
ax.set_xlim(xmin, xmax)
ax.set_ylim(ymin, ymax)
ax.set_aspect('equal')
return fig, ax
def plot_data(ax, X, Y):
I = np.where(Y == -1)
ax.scatter(X[I,0], X[I,1], c='tab:blue', marker='_')
I = np.where(Y == 1)
ax.scatter(X[I,0], X[I,1], c='tab:red', marker='+')
def draw_line(ax, wx, wy, b, ls, name='', color='tab:gray'):
def f(x, wx, xy, b):
return - wx / wy * x - b / wy
x = np.array(ax.get_xlim())
y = f(x, wx, wy, b)
ax.plot(x, y, color=color, ls=ls, label=f'{name}')
def draw_margins(ax, wx, wy, Xx, Xy, svn, svp, s=None):
length = np.sqrt(wx ** 2 + wy ** 2)
margin = 1 / length
for i in svn:
x, y = Xx[i], Xy[i]
ax.scatter([x], [y], s=s, facecolors='none', edgecolors='tab:blue')
ax.plot([x, x + wx * margin / length], [y, y + wy * margin / length], ls=':', color='tab:blue')
for i in svp:
x, y = Xx[i], Xy[i]
ax.scatter([x], [y], s=s, facecolors='none', edgecolors='tab:red')
ax.plot([x, x - wx * margin / length], [y, y - wy * margin / length], ls=':', color='tab:red')
def plot_support_vectors(ax, X, Y, svs, s=None):
for i in svs:
color = 'tab:red' if Y[i] == 1 else 'tab:blue'
ax.scatter([X[i][0]], [X[i][1]], s=s, facecolors='none', edgecolors=color)
def draw_heatmap(ax, fig, X, Y, model, step=1, N=1024):
(xmin, xmax), (ymin, ymax) = find_range(X[:,0], X[:,1])
XX, YY = np.meshgrid(np.linspace(xmin, xmax, N), np.linspace(ymin, ymax, N))
XY = np.vstack([XX.ravel(), YY.ravel()]).T
C = model.decision_function(XY).reshape(XX.shape)
vmin, vmax = C.min(), C.max()
vmin = ((vmin // step) - 1) * step
vmax = ((vmax // step) + 1) * step
width = max(abs(vmin), abs(vmax))
mesh = ax.pcolormesh(XX, YY, C, norm=matplotlib.colors.Normalize(vmin=-width, vmax=width), cmap='bwr', shading='auto', alpha=0.2)
cbar = fig.colorbar(mesh, ax=ax)
cbar.set_label('Output value')
cont = ax.contour(XX, YY, C, colors='tab:gray', linewidths=0.5, linestyles='dashed', levels=np.arange(vmin, vmax+1, step))
cont.clabel(fmt='%1.1f')
9.1. 線形モデル#
まず、線形モデルによる二値分類を説明する。\(d\)次元ベクトルで表される事例\(\bm{x} \in \mathbb{R}^d\)に対して、二値のクラス\(\hat{y} \in \{+1, -1\}\)を次式で予測する。
線形モデルのラベル推定式
ここで、重みベクトル\(\bm{w} \in \mathbb{R}^d\)と\(b \in \mathbb{R}\)はモデルのパラメータである。なお、この判別式はロジスティック回帰のものと同様であるが、今後の数式の表記をシンプルにするため、クラス(目的変数が取りうる値)の定義を\(\{1, 0\}\)から\(\{+1, -1\}\)に変更した。
事例ベクトル\(\bm{x}_i \in \mathbb{R}^d\)とその正解クラス\(y_i \in \{+1, -1\}\)の組で訓練事例が表現され、\(N\)個の事例からなる訓練データ\(\mathcal{D} = \{(\bm{x}_i, y_i)\}_{i=1}^N\)が与えられる。また、簡単のため訓練データは線形分離可能であると仮定する。例として、\(d=2\)(2次元)で\(50\)事例からなる訓練データを考える。
from sklearn.datasets import make_blobs
X, Y = make_blobs(n_samples=50, centers=2, random_state=129, cluster_std=.6)
Y = Y * 2 - 1
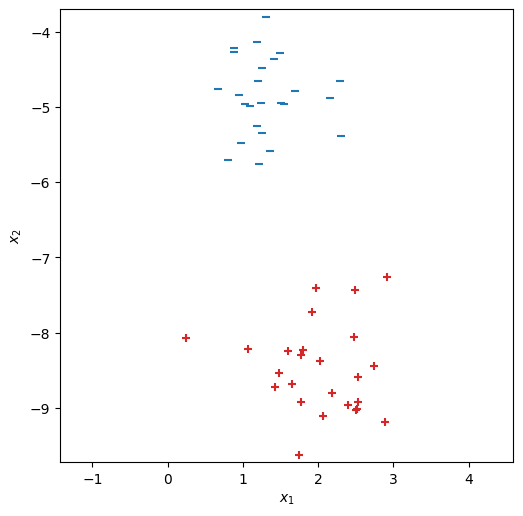
この訓練データの\(\bm{x} \in \mathbb{R}^2\)を2次元平面上にプロットする。この章では、正例(\(y = +1\))は+印(赤色)で、負例(\(y = -1\))はー印で示す。
fig, ax = init_graph(X, Y)
plot_data(ax, X, Y)
plt.show()
9.1.1. マージン最大化#
さて、線形モデルのパラメータ\(\bm{w}\)と\(b\)の値が決まると、\(\hat{y}\)を\(+1\)と\(-1\)に識別する分離平面を描くことができる。以下の可視化では、\(\bm{w}\)と\(b\)の値を適当にセットし、\(b\)の値を変えながら3本の分離平面を描いた。今回のデータは\(2\)次元であるため、分離平面は直線で表現される。この中でどの分離平面が良さそうであろうか?
fig, ax = init_graph(X, Y)
plot_data(ax, X, Y)
plot_support_vectors(ax, X, Y, [4, 40], s=100)
draw_line(ax, 0.366, -1.046, -6.8, '-', 'Line 1')
draw_line(ax, 0.366, -1.046, -7.5, '-.', 'Line 2')
draw_line(ax, 0.366, -1.046, -8.2, ':', 'Line 3')
plt.legend(loc='upper left')
plt.show()
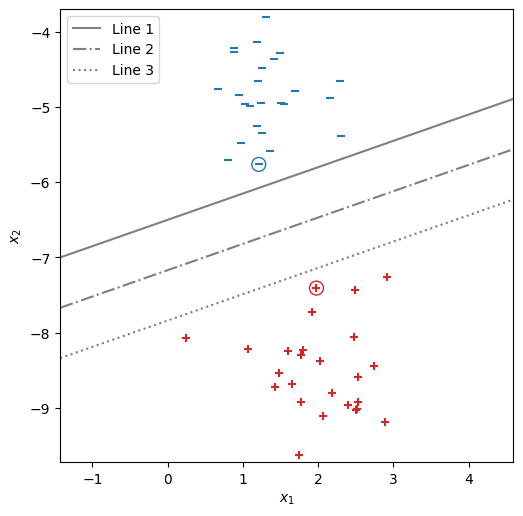
この3つの分離平面は、学習事例の全てを正しく分類できている。ところが、汎化性能の高い分類器を作るという観点では、学習データに現れていない点を正しく分類できるかどうかが重要である。言い換えれば、上のグラフでプロットされていない領域の分類結果が合理的なものになりそうか、検討しなければならない。
まず、一番上の分離平面 "Line 1" を考える。その分離平面の近くに丸印を付けた負例がある。もし(未知の)事例がその負例の周辺に現れた場合、\(\hat{y}=-1\)に分類することが合理的である。ところが、この分離平面は丸印の負例の点のすぐ近くにあるため、その点の下側では\(\hat{y}=+1\)と分類されてしまう恐れがある。 続いて、一番下の分離平面 "Line 3" を考える。その分離平面の近くに丸印を付けた正例がある。もし(未知の)事例がその正例の周辺に現れた場合、\(\hat{y}=+1\)に分類することが合理的である。ところが、この分離平面が正例のすぐ近くにあるため、その点の上側では\(\hat{y}=-1\)と分類されてしまう恐れがある。
サポートベクトルマシンでは、すべての学習事例を正しく分類でき、かつ全ての学習事例から離れた分離平面は、高い汎化性能を持つと仮定する。全学習事例と分離平面との距離を定量化するため、全学習事例から分離平面に垂線を降ろし、その距離の最小値をマージン(margin)として定義する。サポートベクトルマシンの学習は、与えられた学習データに対してマージンを最大にする分離平面を求めることである。
マージンを最大化するという観点では、先ほどの3つの分離平面の中では真ん中が最も良さそうである。また、この可視化が示唆するように、分離平面を\(y=-1\)の事例から遠ざけると、\(y=+1\)の事例に近づくことになる。この均衡があるため、マージンが最大になるように分離平面を求めた時、マージンの計算に関与する事例(垂線の距離が最小になる事例)は、\(y=\pm 1\)の双方のクラスにおいて少なくとも1つずつ存在する。
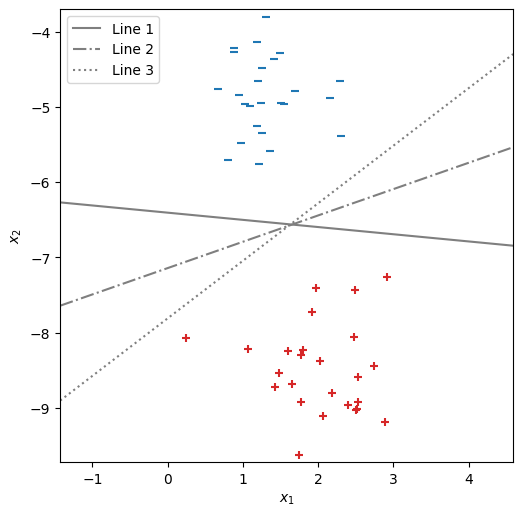
今度は、\(b\)を固定し、\(\bm{w}\)を変えることで傾きの異なる3つの直線を分離平面として引いた。この中でマージンが最も大きくなるのはどの直線であろうか? 真ん中の分離平面 "Line 2" であることは明白であろう。
fig, ax = init_graph(X, Y)
plot_data(ax, X, Y)
draw_line(ax, -0.1, -1.046, -6.7, '-', 'Line 1')
draw_line(ax, 0.366, -1.046, -7.471, '-.', 'Line 2')
draw_line(ax, 0.8, -1.046, -8.17, ':', 'Line 3')
plt.legend(loc='upper left')
plt.show()
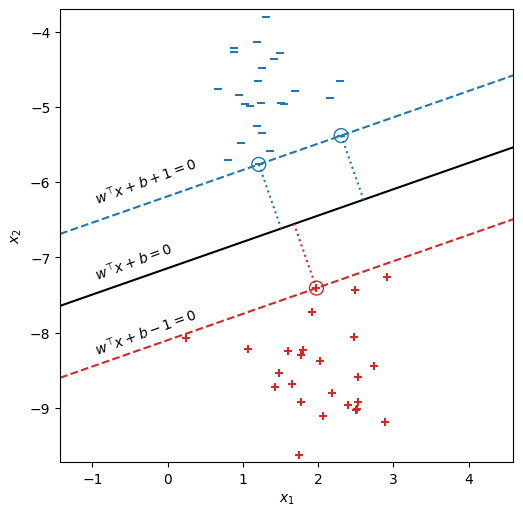
この中央の分離平面 "Line 2" に着目して書き直したのが、下のグラフである。このグラフでは、分離平面を黒色の実線で示した。マージンの計算に関与する事例は、\(y = +1\)側に1つ(丸印付きの+)、\(y = -1\)側に2つ(丸印付きのー)ある。このマージンの計算に関与する事例をサポートベクトルと呼ぶ。サポートベクトルから分離平面に降ろした垂線を点線で示した。実は、この分離平面は訓練事例に対してサポートベクトルマシンを学習した結果得られたものである。したがって、このような分離平面に対応するパラメータ\(\bm{w}, b\)を求めることが、以降の議論の中心である。
wx, wy, b = 0.36586586, -1.04568619, -7.470506295184168
fig, ax = init_graph(X, Y)
plot_data(ax, X, Y)
draw_line(ax, wx, wy, b, '-', color='black')
draw_line(ax, wx, wy, b+1, '--', color='tab:blue')
draw_line(ax, wx, wy, b-1, '--', color='tab:red')
draw_margins(ax, wx, wy, X[:,0], X[:,1], [4, 30], [40], s=100)
ax.text(-1, -6.3, r'$w^\top x + b + 1 = 0$', rotation=20)
ax.text(-1, -7.3, r'$w^\top x + b = 0$', rotation=20)
ax.text(-1, -8.3, r'$w^\top x + b - 1 = 0$', rotation=20)
plt.show()
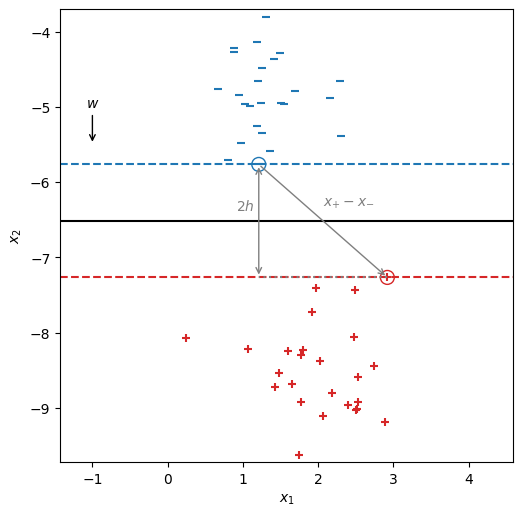
いま、\(y = +1\)のサポートベクトルを適当に選び、\(\bm{x}_{+}\)と書くことにする、また、\(y = -1\)のサポートベクトルも適当に選び、\(\bm{x}_{-}\)と書くことにする。さらに、パラメータ\(\bm{w}\)の値を適当に設定したとする。なお、パラメータ\(\bm{w}\)を設定したことにより、分離平面は\(\bm{w}\)に直交するものの中から選ぶことになる。
マージンを\(h\)とおくと、その長さの2倍は\(\bm{x}_{-}\)から\(\bm{x}_{+}\)への向きベクトルを分離平面の法線ベクトル\(\bm{w}\)に射影した長さに等しいので、
Show code cell source
def solve(dx, dy, xp, xn):
# This function solves:
# c \cdot d \cdot xp + b = 1
# c \cdot d \cdot xn + b = -1
d = np.array([dx, dy])
wxp = np.dot(d, xp)
wxn = np.dot(d, xn)
c = 2 / (wxp - wxn)
b = 1 - c * wxp
return (dx * c, dy * c, b)
xp = X[23]
xn = X[4]
dx, dy = 0.0, -0.5
wx, wy, b = solve(dx, dy, xp, xn)
base = np.array([-1, -5])
w = np.array([wx, wy])
h = np.abs(np.dot(xp - xn, w)) / (2 * np.linalg.norm(w))
xn2 = xn + 2 * h * w / np.linalg.norm(w)
fig, ax = init_graph(X, Y)
plot_data(ax, X, Y)
draw_line(ax, wx, wy, b, '-', color='black')
draw_line(ax, wx, wy, b+1, '--', color='tab:blue')
draw_line(ax, wx, wy, b-1, '--', color='tab:red')
plot_support_vectors(ax, X, Y, [4, 23], s=100)
ax.annotate('$w$', base + np.array([dx, dy]), base, ha='center', arrowprops={'arrowstyle': '->'})
ax.annotate('', xp, xn, arrowprops=dict(arrowstyle='->', color='tab:gray'))
ax.text((xn[0] + xp[0]) / 2, (xn[1] + xp[1]) / 2 + 0.2, '$x_{+} - x_{-}$', color='tab:gray')
ax.annotate('', xn2, xn, arrowprops=dict(arrowstyle='<->', color='tab:gray'))
ax.text(xn[0] - 0.3, (xn[1] + xn2[1]) / 2 + 0.2, '$2h$', va='center', color='tab:gray')
ax.plot([xp[0], xn2[0]], [xp[1], xn2[1]], ls=':', color='tab:gray')
plt.show()
したがって、この\(h\)を最大にする\(\bm{w}\)や\(b\)を求めればよい。ところが、マージン\(h\)を求める式は、\(\bm{w}\)を定数倍しても値が変わらない。すなわち、\(\bm{w}\)を\(\gamma\)倍してからマージンを求めても、分子と分母で\(\gamma\)が打ち消されるだけである。
言い換えれば、現状のマージン最大化の定式化では、求まる\(\bm{w}\)や\(b\)に関して任意性が残っている。そこで、サポートベクトルに対応する事例\(\bm{x}_{+}, \bm{x}_{-}\)に対して、以下の式が成り立つこととし、\(\bm{w}\)と\(b\)の任意性を除去する。
この\(\bm{w}^\top\bm{x} + b - 1 = 0\)の直線を赤の破線で、\(\bm{w}^\top\bm{x} + b + 1 = 0\)の直線を青の破線で示した。
以上の取り決めを導入したことにより、\(y_i = +1\)である学習事例は、
を満たし、\(y_i = -1\)である学習事例は
を満たす必要がある。なお、この2つの条件式は、\(y_i\)を使って次のようにまとめることができる。
さて、マージンを求める式にサポートベクトルが満たすべき条件(式(9.4))を代入すると、
ゆえに、サポートベクトルマシンの学習は以下の制約付き最適化問題でパラメータ\(\bm{w}^*, b^*\)を求める問題に帰着する。
最大化問題を最小化問題に変更し、数学的な取り扱いの都合で目的関数に\(\frac{1}{2}\)を付けると、サポートベクトルマシンの学習のための最小化問題は次式で表される。
サポートベクトルマシンの主問題
なお、この最適化問題ではパラメータ\(b\)が最小化に関与しないように見えるが、\(\bm{w}\)が変化すると制約を満たすために\(b\)を変更する必要がある。
9.2. 制約付き最適化#
この不等式制約付き最小化問題を解くため、ラグランジュの未定乗数法を用いる。
ここで、\(\alpha_1, \dots, \alpha_N \geq 0\)はラグランジュ乗数であり、これらをまとめてベクトル\(\bm{a}\)で表す。
ラグランジュ関数\(L(\bm{w}, b, \bm{a})\)を最小化するため、\(\bm{w}\)で偏微分して\(0\)とおくと、
また、ラグランジュ関数\(L(\bm{w}, b, \bm{a})\)を\(b\)で偏微分して\(0\)とおくと、
式(9.11)(元のラグランジュ関数)に式(9.13)を代入し、さらに式(9.14)を使って整理すると、\(\bm{a}\)に関する最小化問題が得られる。この目的関数は元の目的関数の双対問題(dual problem)と呼ばれる。
まとめると、サポートベクトルマシンの学習の双対問題は以下の通りである。
サポートベクトルマシンの双対問題
この最小化問題は二次計画法で解くことができ、サポートベクトルマシンでは逐次最小問題最適化法(SMO: Sequential Minimal Optimization)などが解法アルゴリズムとして用いられる。ただし、ここではその解法の詳細は省略する。
双対問題を最小にする解\(\bm{a}^*\)を求めたのち、式(9.13)に代入すると、\(\bm{w}^*\)を求める式が得られる。
なお、ラグランジュの未定乗数法におけるKarush-Kuhn-Tucker (KKT) 条件により、以下の条件が成り立つ。
この3番目の条件から、\(y_i (\bm{w}^\top\bm{x}_i + b) > 1\)が成り立つ事例\(\bm{x}_i, y_i\)、すなわちサポートベクトルではない事例に対しては、\(a_i = 0\)が必ず成立することが分かる。ゆえに、\(\bm{w}^*\)を求める式は、学習データ中の少数のサポートベクトルの重み付き和で表現され、サポートベクトル以外の事例は\(\bm{w}^*\)の計算に影響を与えない。
求めたサポートベクトルのいずれかに対して、式(9.4)を利用することで、\(b^*\)を求めることができる。例えば、\(\bm{x}_{-}\)を用いる場合は、
となる。一般に、サポートベクトルとなった事例のインデックスを\(s\)として、その事例の特徴ベクトルとラベルをそれぞれ、\(\bm{x}_s\)と\(y_s\)と書くと、
である。
9.3. 線形SVMの学習例#
sklearn.svm.SVCを用いて、例として用いた学習データで線形モデルを学習する。
from sklearn.svm import SVC
model = SVC(kernel='linear')
model.fit(X, Y)
SVC(kernel='linear')
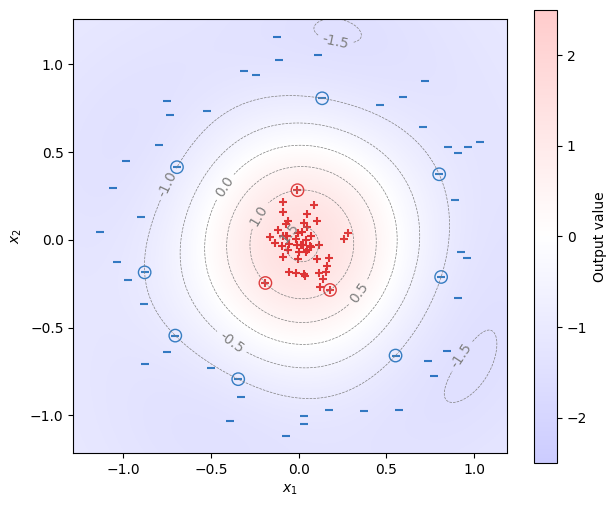
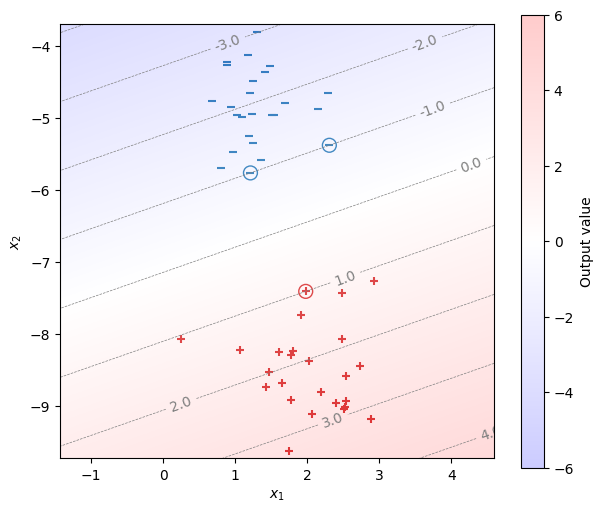
学習で求めたパラメータ\(\bm{w}, b\)を用い、\(\bm{w}^\top\bm{x} + b\)の等高線を描いたうえで、学習事例をプロットする。なお、サポートベクトルは丸印で表示している。サポートベクトルが等高線上で\(\pm 1\)の直線上に乗っていることが確認できる。
fig, ax = init_graph(X, Y, figsize=(7, 6))
plot_data(ax, X, Y)
plot_support_vectors(ax, X, Y, model.support_, s=100)
draw_heatmap(ax, fig, X, Y, model)
plt.show()
学習により求められた\(\bm{w}\)と\(b\)を確認する。
model.coef_[0], model.intercept_[0]
(array([ 0.36586586, -1.04568619]), -7.470506295184168)
サポートベクトルとなった事例のインデックス番号を確認する。
model.support_
array([ 4, 30, 40], dtype=int32)
サポートベクトルとなった事例のラベルを確認する。
Y[model.support_]
array([-1, -1, 1])
上で示した事例に対応する\(\alpha_i\)の値を確認する。なお、このdual_coef_では\(y_i \alpha_i\)の値が得られるため、負の値を取ることがある。
model.dual_coef_[0]
array([-0.51806476, -0.0957497 , 0.61381447])
念のため、\(\sum_{i=1}^{N} \alpha_i y_i = 0\)が満たされているか確認する。
np.sum(model.dual_coef_[0])
2.220446049250313e-16
念のため、\(\bm{w}^* = \sum_{i=1}^{N} \alpha_i y_i \bm{x}_i\)で重みベクトル\(\bm{w}^*\)を求め、model.coef_[0]の結果と一致することを確認する。
w = model.dual_coef_[0] @ X[model.support_]
w
array([ 0.36586586, -1.04568619])
念のため、\(b^*= y_s -\bm{w}^* \cdot \bm{x}_{s}\)でバイアス項\(b^*\)を求め、model.intercept_[0]の結果と一致することを確認する。
i = model.support_[0]
b = Y[i] - np.dot(w, X[i])
b
-7.470906877495702
9.4. カーネルSVM#
さて、入力の特徴ベクトル\(\bm{x}\)に非線形変換を施し、非線形な分類モデルを構成することを考える。\(d\)次元の特徴空間から\(r\)次元の特徴空間への非線形変換を\(\bm{\phi}: \mathbb{R}^d \mapsto \mathbb{R}^{r}\)とすると、このモデルのパラメータはベクトル\(\bm{w} \in \mathbb{R}^{r}\)とバイアス項\(b \in \mathbb{R}\)となる。線形の場合と同様に、事例\(\bm{x}\)に対して分類器が予測するクラス\(\hat{y}\)は、
このモデルは、事例の特徴ベクトル\(\bm{x}\)を\(\bm{\phi}(\bm{x})\)に置き換えただけであるから、サポートベクトルマシンの学習の双対問題は、式(9.16)より、
ここで、
とおくと、先ほどの問題を以下の式で表現できる。
カーネル関数によるサポートベクトルマシンの双対問題
これは単なる置換に思えるかもしれないが、重要な意味を持つ。サポートベクトルマシンの学習では、\(\bm{\phi}(\bm{x})\)を求めなくても、全事例の組み合わせに対して\(K(\bm{x}_i, \bm{x}_j)\)が求められれば十分である。\(K\)はカーネル関数(kernel function)と呼ばれる。機械学習において\(\bm{\phi}(\bm{x})\)を陽に計算せず、カーネル関数の計算だけで済ませてしまうことは、カーネル・トリック(kernel trick)と呼ばれる。
ここでは、よく用いられるカーネル関数を紹介する。
9.4.1. 線形カーネル#
このカーネルに対応する変換は\(\bm{\phi}(\bm{x}) = \bm{x}\)である(つまり、これまでに導出した線形SVMそのものである)。
9.4.2. 多項式カーネル#
\(m=2\)の場合、
であるから、このカーネルに対応する変換は、
すなわち、2次の多項式カーネル\(K(\bm{u}, \bm{v}) = (\bm{u}^\top\bm{v} + c)^2\)を用いることは、\(d\)次元の特徴ベクトル\(\bm{x}\)から、各要素の二乗、2つの要素同士の積、各要素を\(\bm{\phi}(\bm{x})\)で取り出すことに相当する。
9.4.3. Radial Basis Function (RBF)#
RBFカーネルに対応する変換は無限次元になり得る。
9.4.4. カーネル関数を用いた分類#
式(9.24)の双対問題を解き、\(\alpha^*_i\; (i \in \{1, \dots N\})\)を求めることで、カーネル関数を用いたサポートベクトルマシンを学習できる。この学習時に必要なのは、全事例の組み合わせ\(i, j \in \{1, \dots N\}\)に対する\(K(\bm{x}_i, \bm{x}_j)\)の値であり、\(\bm{\phi}(\bm{x})\)を求めなくても(求められなくても)十分であった。 ただ、与えられた事例\(\bm{x}\)を式(9.21)で分類するときには、\(\bm{\phi}(\bm{x})\)の計算が必要のように思える。 ところが、事例を分類するときも、カーネル関数を用いて\(\bm{\phi}(\bm{x})\)の計算を回避できる。
\(\bm{\phi}(\bm{x})\)に対する最適な重み\(\bm{w}^*\)は、式(9.17)を用いて次のように表される。
これを、式(9.21)の判別式に代入すると、次のように整理できる(\(b^*\)はバイアス項の最適値である)。
すなわち、\(\bm{\phi}(\bm{x})\)を陽に計算することなく、カーネル関数の値さえ計算できれば、事例を分類できる。バイアス項の最適値\(b^*\)は、サポートベクトルとなった事例を用いて調整すればよい。例えば、ある正例のサポートベクトル\(\bm{x}_{+}\)(\(y=+1\))を用いる場合、次のように求める。
9.5. カーネルSVMの学習例#
事例数\(N=100\)、入力\(\bm{x}\)の次元数\(d_{\rm in}=2\)の二値分類の訓練データを用意する(このデータは線形分離不能である)。
from sklearn.datasets import make_circles
X, Y = make_circles(100, factor=.1, noise=.1)
Y = Y * 2 - 1
fig, ax = init_graph(X, Y)
plot_data(ax, X, Y)
plt.show()
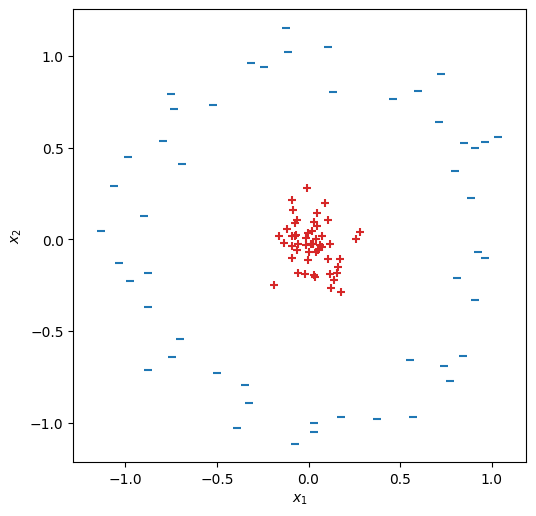
このデータは\(z = x_1^2 + x_2^2\)の非線形変換を施すことにより、簡単に分離できる。
Show code cell source
Z = np.exp(-(X ** 2).sum(1))
(xmin, xmax), (ymin, ymax) = find_range(X[:,0], X[:,1])
fig = plt.figure(dpi=100, figsize=(8, 8))
ax = fig.add_subplot(projection='3d')
ax.set_xlabel('$x_1$')
ax.set_ylabel('$x_2$')
ax.set_zlabel('$z$')
ax.set_xlim(xmin, xmax)
ax.set_ylim(ymin, ymax)
I = np.where(Y == -1)
ax.scatter(X[I,0], X[I,1], Z[I], c='tab:blue', marker='_')
I = np.where(Y == 1)
ax.scatter(X[I,0], X[I,1], Z[I], c='tab:red', marker='+')
def update(i, ax):
ax.view_init(elev=90-i*2, azim=45)
ani = matplotlib.animation.FuncAnimation(fig, update, fargs=(ax,), interval=100, frames=46)
html = ani.to_jshtml()
plt.close(fig)
HTML(html)
カーネル関数を用いたSVMでは、この非線形変換を陽に与えずに、カーネル関数の形だけを指定して非線形分類を行う。以下は2次の多項式カーネルを用いる例である。
model = SVC(kernel='poly', degree=2, C=1e6)
model.fit(X, Y)
SVC(C=1000000.0, degree=2, kernel='poly')
式(9.31)を用いて、決定関数(\(\bm{w}^\top\bm{\phi}(\bm{x}) + b\))の値をヒートマップで描画する。
fig, ax = init_graph(X, Y, figsize=(7, 6))
plot_data(ax, X, Y)
plot_support_vectors(ax, X, Y, model.support_, s=80)
draw_heatmap(ax, fig, X, Y, model, step=0.5)
plt.show()
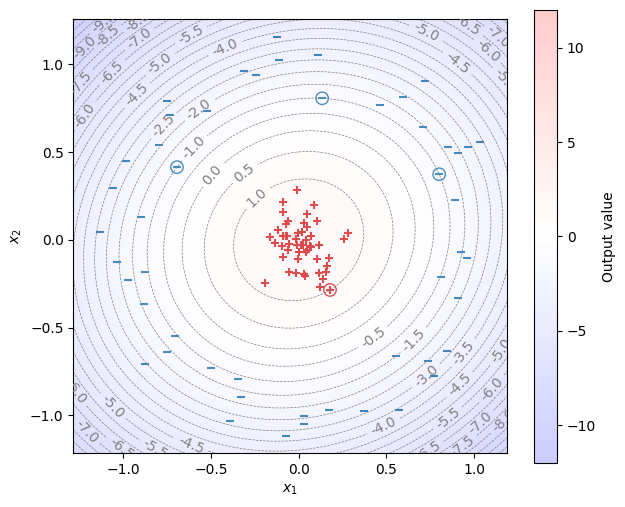
RBFカーネルを用いる例である。
model = SVC(kernel='rbf', C=1e6)
model.fit(X, Y)
SVC(C=1000000.0)
式(9.31)を用いて、決定関数(\(\bm{w}^\top\bm{\phi}(\bm{x}) + b\))の値をヒートマップで描画する。
fig, ax = init_graph(X, Y, figsize=(7, 6))
plot_data(ax, X, Y)
plot_support_vectors(ax, X, Y, model.support_, s=80)
draw_heatmap(ax, fig, X, Y, model, step=0.5)
plt.show()